标签:class substr 另类 学习 字符 highlight oid arp nbsp
如题,给出两个字符串s1和s2,其中s2为s1的子串,求出s2在s1中所有出现的位置。
为了减少骗分的情况,接下来还要输出子串的前缀数组next。如果你不知道这是什么意思也不要问,去百度搜[kmp算法]学习一下就知道了。
输入格式:
第一行为一个字符串,即为s1(仅包含大写字母)
第二行为一个字符串,即为s2(仅包含大写字母)
输出格式:
若干行,每行包含一个整数,表示s2在s1中出现的位置
接下来1行,包括length(s2)个整数,表示前缀数组next[i]的值。
ABABABC ABA
1 3 0 0 1
时空限制:1000ms,128M
数据规模:
设s1长度为N,s2长度为M
对于30%的数据:N<=15,M<=5
对于70%的数据:N<=10000,M<=100
对于100%的数据:N<=1000000,M<=1000
样例说明:
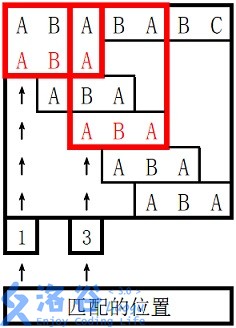
所以两个匹配位置为1和3,输出1、3
一种另类题解:
#include <cstring>//这题用string非常方便
#include <cstdio>
#include <iostream>
using namespace std;
string s,s1;
int next[1000];
void get_next(string s)
{
for (int k=0;k<=s.size();k++)
{
string st=s.substr(0,k+1);
for (int i=1;i<st.size();i++)
{
string s1=st.substr(0,i),s2=st.substr(st.size()-i,i);//前缀与后缀
if(s1==s2) next[k]=i;
}
}
}
void match(string s,string s1)
{
int l=s.size()-1,l1=s1.size()-1;
for (int i=0;i<=l;i++)
{
int j;
for (j=0;j<=l1;j++)
if (s[i+j]!=s1[j])
break;
if (j-1==l1) //j还是加了1,所以要减1
{
printf("%d\n",i+1);//匹配成功
continue;
}
else
i+=next[j]; //跳跃
}
}
main()
{
cin>>s>>s1;
get_next(s1);
match(s,s1);
for (int i=0;i<s1.size();i++)
printf("%d ",next[i]);
}
1 #include<iostream> 2 #include<cstring> 3 #include<cstdio> 4 using namespace std; 5 char s1[1000010],s2[1002]; 6 int next[1000010]; 7 inline void print(int x) 8 { 9 static int ans[10],top=0; 10 if(x==0) 11 putchar(‘0‘); 12 while(x) 13 ans[top++]=x%10,x/=10; 14 while(top) 15 putchar(ans[--top]+‘0‘); 16 } 17 int main() 18 { 19 scanf("%s%s",s1,s2); 20 int len2=strlen(s2),p=-1; 21 next[0]=-1; 22 for(int i=1;i<len2;i++){ 23 while(p!=-1&&s2[p+1]!=s2[i]) 24 p=next[p]; 25 p+=(s2[p+1]==s2[i]); 26 next[i]=p; 27 } 28 int len1=strlen(s1); 29 p=-1; 30 for(int i=0;i<len1;i++){ 31 while(p!=-1&&s1[i]!=s2[p+1]) 32 p=next[p]; 33 p+=(s2[p+1]==s1[i]); 34 if(p+1==len2) 35 print(i-len2+2),putchar(‘\n‘), p=next[p]; 36 } 37 for(int i=0;i<len2;i++) 38 print(next[i]+1),putchar(‘ ‘); 39 return 0; 40 }
标签:class substr 另类 学习 字符 highlight oid arp nbsp
原文地址:http://www.cnblogs.com/suishiguang/p/6285639.html