标签:insert const erro 提取 统计 改变 联系 处理器 个人
最近基于huffman编码和最小堆排序算法实现了一个压缩、解压缩的小程序。其源代码已经上传到github上面: Jcompress下载地址 。在本人的github上面有一个叫Utility的repository,该分类下面有一个名为Jcompress的目录便是本文所述的压缩、解压缩小程序的源代码。后续会在Utility下面增加其他一些实用的小程序,比如基于socket的文件断点下载小程序等等。如果你读了此文觉得还不错,不防给笔者的github点个star, 哈哈。在正式介绍Jcompress设计之前,笔者先展示一下Jcompress压缩、解压缩文件的一些截图。下图一是笔者用来做实验的一些文件,包括pdf电子书,可执行文件,jpg图片,以及电影美人鱼等,图中后缀名为.jcprs的便是Jcompress压缩后的文件,而文件名中带数字‘1’的是.jcprs文件经过Jcompress解压缩而得到的文件。剩下的几幅图分别是解压缩后的pdf, exe, jpg, rmvb格式文件正常打开、运行以及播放的截图。为了方便排版,笔者在上传图片的时候将图片长度、宽度重新设置了一下,导致看起来有点模糊,大家凑合着看吧,哈哈。
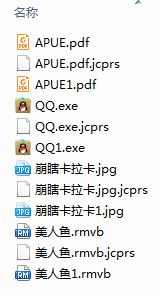


相信大家在本科学习数据结构课程(严蔚敏版)的时候都接触过huffman编码吧,课本中的例子给了若干个字符,以及每个字符的出现次数,并以此构造了一颗huffman树。然后从huffman树的根节点到每一个叶子节点走一条路径,如果约定往左编码0,往右编码1,那么每一个叶子便可以得到一个由一串0和1表示的串。现在我们回到实际问题上来,我们要压缩的文件格式多种多样,可能是图片,也可能是各种格式的电影,还有可能是可执行文件。那么问题就来了,课本中的例子是对‘字符’来构造huffman树的,那么面对实际问题我们是对‘谁’来构造huffman树呢?我们来看一看下图,答案就自然浮出水面了。
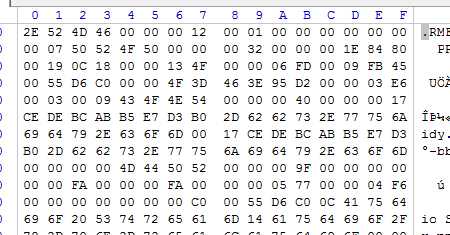
上图是用winhex软件打开rmvb格式的电影美人鱼后的部分截图,从图中可以看出它本质上其实就是一系列的二进制01串(图中是以16进制表示的)。例如图中第一个‘数字’ 2E其实就是二进制的0010 1110,也就是8个二进制的bit,所以我们何不以每8个bit为一个单位把它看做课本中的例子中的‘字符’呢?根据排列组合,8个bit最多有256中情况:从0x00到0xFF。当然这256种编码所代表的‘字符’只有部分是可以以ASCII码的形式打印出来的。那么我们在代码里把要处理的文件以‘二进制’格式读入内存,把内存里的bits们看做一个个的char,然后统计256种char每一个出现的频率。这样我们就可以根据每一个‘字符’出现的频率来构造一颗huffman树了,进而得到每一个‘字符’的编码,并把编码写入到另外一个文件里面,便得到了压缩后的文件。然后我们按照同样的规则对压缩后的文件按照huffman树来解码,把解码出来的‘字符’在写入到新的文件里面,于是就得到了新的解压缩后的文件了。
??上一段文字里面其实漏掉了一个细节:char其实是有符号的,为了方便我们把每8个bit组成的char 定义为unsigned char。这样的好处是255就是0xff,否则的话-1才对应着0xff,因为在有符号的情况下左边第一个bit是代表符号位的。为了避免负char给我们实现带来不必要的麻烦,最好是以unsigned char的类型来看待每8个bit的组合。其实char只是代表了一个数据的长度为8bit而已,我们在printf的时候以%c来解释的时候它才是字符,完全可以把它看做数据并以%d等格式打印出数字来。当然char类型的名字容易给人以误解,认为它理所当然的代表着字符类型。
??在构造huffman树的过程当中,我们每次都需要从现有的结点中选取出现频率(或者权重)最小的两个unsigned char来构造huffman树,因此还需要一个排序算法。堆排序是一种不错的算法,我们可以构造出一个最小堆,堆顶的元素就是最小的元素。这个最小堆应该提供如下功能:第一,提取堆的最小值,这个简单,直接从堆顶取值就行了。当然每一次提取最小值后,此时的堆已经不是最小堆了,要紧跟着调整堆,使之重新成为最小堆;第二,该最小堆应该支持插入操作,因为在构造huffman树的过程中,每一次取出来的两个最小权重的结点会构造一个新的huffman树,而此树的跟会重新作为下一次构造的候选结点,因而该候选结点需要重新插入堆中,并且通过调整使之再次符合最小堆的特征。
??综上所述,本文将要实现的压缩、解压缩小程序Jcompress的核心组件是:最小堆排序算法、huffman编码算法。本文将会围绕这两个主题来分析Jcompress的具体实现过程。
??还记得有句名言吗:算法+数据结构=程序,没错,我们写的任何代码基本上都是要操作数据的。有些程序比较小,可能只需要使用基本的数据类型而不需要定义较为复杂数据结构。但是当一个程序的逻辑相对复杂的时候,为了代码逻辑的清晰,我们往往就需要定义一些数据结构,然后实现一系列的算法来操作这些数据结构,在加上业务逻辑代码,于是一个程序的形态便初步具备了。因此我们可以稍微扩充上面这句话:算法+数据结构+业务逻辑代码=系统。因此我们每个人在面临设计较为复杂的系统的时候,都应该按照算法、数据结构、业务逻辑代码的三个角度来考虑设计方案。
1 typedef struct HuffmanNode{ 2 unsigned char data_8bit; 3 unsigned long long data_8bit_count; 4 struct HuffmanNode *parent; 5 struct HuffmanNode *left_child; 6 struct HuffmanNode *right_child; 7 }HuffmanNode;
数据结构HuffmanNode包括5个字段。data_8bit就是存储前文中我们所说的unsigned char的;data_8bit_count存储data_8bit出现的次数;指针parent表示该结点的父结点;left_child表示该结点的左孩子;right_child表示该结点的右孩子。其中data_8bit_count需要遍历一次文件内容得到,而parent、left_child、right_child在构造huffman树的过程中会被设置。
1 typedef struct HuffmanEncode{ 2 char *encode; 3 long length_of_encode; 4 }HuffmanEncode;
数据结构HuffmanEncode代表每一个unsigned char的编码结果,其中字段encode会指向一串字符,该字符由字符‘0’和字符‘1’组成,从huffman树的根节点走一条到叶子结点的路便可以得到该编码,而length_of_encode代表着encode的长度。此刻细心的读者可能会问两个问题,首先HuffmanEncode结构体好像看不出来该编码对应哪个字符;其次*encode为什么不以\0结束的字符串形式存在,而是多了一个表示长度的字段。
??首先对于第一个问题,笔者在使用该数据结构的时候是以HuffmanEncode huffman_encode[256]的方式来使用的,因为unsigned char一共有256种情况,用数组的方式比较方便,下标便直接代表了对应的unsigned char。例如huffman_encode[255]的下标是255,对应着0xff这个unsigned char。对于第二个问题,假设unsigend char 0x255的编码为字符串"00101",我们在压缩的时候需要把"00101"以二进制‘00101‘的形式写入内存缓冲区,继而写入磁盘文件。我们不能直接把"00101"以\0为结束标志的字符串的形式写入内存缓冲区中,那样的话就达不到压缩的目的了,变成一个字符用5个字符来表示,显然不行,我们应该挨个遍历字符如果是字符‘0’则就往内存对应的bit写入0,‘1’则对应的bit写入1,这样才能最大程度节省空间。因此我们用增加一个长度字段的方式来代替\0为结束标志的字符串,在代码实现上更为方便一点。
??当然读者或许会问HuffmanNode数据结构中为什么用专门的字段data_8bit而不是数组索引来代表对应的unsigned char呢?这是因为HuffmanEncode是一个数组,而HuffmanNode最终是以一颗树的形式存在的,在构造huffman树的过程中,特定索引位置对应的结点会发生变化。
1 typedef struct EncodeBuffer{ 2 unsigned char *buffer; 3 long size; 4 long bits_num_lastbytes; 5 }EncodeBuffer;
想象一下,在压缩的时候,我们把最初的文件经过编码之后先是存储在内存中,然后在用诸如fwrite的函数把该内存写入磁盘文件中。而在解压缩的时候我们需要把压缩文件的内容读入到内存中,在根据huffman树来恢复原本的数据。这里提到的内存便可以一个数据结构EncodeBuffer来表示,其中的字段buffer将来是通过malloc函数分配的一块内存,字段size表示该buffer存储的有效字节数量,bits_num_lastbytes表示最后一个字节中包含的有效bit数量。这是因为一个文件经过编码后包含的bit数量不一定是8的整数倍,也就是说除以8后,余数可能是1--7中的任意一个,我们需要记住这个数字,最后一个字节的剩下的bit是不需要进行处理的。当然在压缩、解压缩的过程都会使用到这个数据结构,其使用方式的微妙之处在下文的源代码里面可以清晰的看出。
1 typedef struct DecodeBuffer{ 2 unsigned char *buffer; 3 long size; 4 }DecodeBuffer;
同样,我们把原始文件读入EncodeBuffer类型的内存缓冲区,然后根据恢复出来的huffman树来找到编码对应的‘原码’,这个‘原码’当然不能直接写入磁盘中的压缩文件中,这样写磁盘次数太多,性能会下降。而应该先把解码出来的数据写入内存缓冲区中,积累多了再一次写入磁盘中。DecodeBuffer便是用来表示该缓冲区的,其中的buffer字段也是通过malloc得到的内存,而size表示buffer中存储的有效字节数。与EncodeBuffer不同,这里没有bits_num_lastbytes这个字段,因为无论压缩文件的bit数是不是8的倍数,压缩前的文件bit数量肯定是8的倍数,因为存储于磁盘上的文件的最小的单位就是字节了。因此解压出来的数据无需担心最后一个bit的有效数量的问题。
1 typedef struct CompressFileHeader{ 2 long length_of_header1; 3 long length_of_header2; 4 5 unsigned char length_of_author_name; 6 unsigned char routine_name_length; 7 unsigned char suffix_length; 8 unsigned char file_name_length; 9 unsigned char bits_of_lastByte; 10 11 char *author_name; 12 char *routine_name; 13 char *suffix; 14 char *file_name; 15 16 }CompressFileHeader;
在解压缩文件的时候,我们所知道的也就是一个压缩文件而已,我们根据什么来解压呢?在压缩的时候,我们构造了一颗huffman树,如果我们能够在解压的时候恢复这颗huffman树,显然我们就可以顺利成章的把压缩文件恢复为原始文件,这个过程也就是所谓的‘解压缩’。因此我们在压缩的时候可以在压缩文件的开始处写入一些元信息,使得我们可以依赖此信息构造出huffman树就可以了。当然还可以在头部加入其它一些信息。在Jcompress中,压缩文件由3部分构成:

上图便是Jcompress的一个压缩文件用winhex打开后的部分截图。右边红色涂掉的部分便是笔者的姓名,紧接着是软件名Jcompress,后缀jcprs,原始文件名APUE.pdf。注意16进制最开始的两个long 型数据2B 00 00 00和59 0A 00 00分别代表着length_of_header1和length_of_header2. 但是他们都是以小端的方式存储的,其实际的值分别是00 00 00 2B和00 00 0A 59.有兴趣的读者可以下去了解下处理器的大端、小端存储方式。
??有了基本思路和数据结构之后,我们便可以定义接口了,本文接口分为四部分:堆排序部分、huffman编码部分、huffman解码部分和业务逻辑部分。下面我们将围绕这四个部分简要介绍这些接口的作用,其源代码将在下文“Jcompress源代码实现”部分呈现。
1 int heap_min_adjust(HuffmanNode **huffman_node_array, long data_start, long data_end); 2 int heap_min_construct(HuffmanNode **huffman_node_array, long array_size); 3 int heap_min_get2min(HuffmanNode **huffman_node_array, HuffmanNode **min_first, HuffmanNode **min_second, long *heap_size);
熟悉堆排序的同学都知道,堆排序其实包括两个过程:一个是堆的调整,另一个是堆的构造,后者是以前者为基础的。heap_min_adjust()便是对堆的调整,使之重新符合最小堆的定义。heap_min_construct()基于heap_min_adjust()而来,通过不断调整初始堆来构造一个最小堆。在构造huffman树的过程中,需要不断地从堆中取出最小的两个堆元素,因此定义接口heap_min_get2min来实现这个功能。
??我们再来看下这些接口函数的参数部分。每一个接口函数的第一个参数huffman_node_array是一个HuffmanNode **类型的数据,实际上huffman_node_array是一个数组,而数组元素又是一个指针,该指针指向具体的HuffmanNode类型的结点数据。数组元素被设计为指针,是为了方便堆排序,排序的时候可以直接交换指针。data_start和data_end标志了huffman_node_array的起始和结束的位置,这样比较灵活,我们可以选择性的对其中某一段数据进行堆排序。array_size表示了用于构造最小堆的数组的长度。min_first和min_second是两个指针,其指向的内容又是一个指针,该指针指向得到的两个最小的堆元素。heap_size存储的是当前最小堆的长度。
??注意参数min_first和min_second都是指向指针的指针,为什么这么做呢?首先这个接口函数为了得到最小的两个堆元素的指针,那么在传递参数的时候如果传递的是HuffmanNode *min_first,那么即使函数内部把min_first设置成了正确的值,调用结束后,在主调函数里min_first依然保持了调用之前的状态,而没有发生丝毫改变,这是因为c函数是传值调用,参数均以值的形式进行传递,指针也不例外。这里有一个误区,很多人可能见过这样的情形:在调用函数里定义了一个变量:int a; 然后以func(&a)的形式来调用int func( int *a),func内部做了动作*a=8,然后主调函数里面就会得到a的值为8.为什么这里不行呢,在这个例子中,传递进来的是a的地址&a, &a的值始终没有变,只是改变了它指向的内存的内容;而对于heap_min_get2min()来说,如果传递的是HuffmanNode *类型的数据min_first,则min_first的本身的值永远不会变,只会改变它所指向的内存的内容,而我们的代码逻辑是要改名指针本身,为了达到这个目的,我们只能传递指针的指针,也即HuffmanNode **类型的min_first,在函数内部我们做类似这样的操作*min_first=xxxx,就可以做到改变min_first指向的内容,也即改变HuffmanNode *类型的数据,这正是我们要的结果。
1 int huffman_tree(HuffmanNode **huffman_tree_root, HuffmanNode **huffman_node_array, long array_size); 2 int huffman_encode(HuffmanNode **huffman_node_array, long huffman_node_array_size,HuffmanEncode *huffman_encode_array);
由前文可知,huffman编码是根据huffman树而来的,走一条从根结点到叶子结点的路径就能得到叶子结点所代表的数据对应的编码。因此上述函数huffman_tree()的作用便是构造一颗huffman树,构造完毕的huffman树的根节点的指针会写入第一个参数指向的内存,第二个参数是调用者传递的huffman结点数组,第三个参数array_size表示huffman结点数组的元素个数。
??函数huffman_encode的作用是:根据huffman_tree()构造出的huffman树,对于每一个叶子结点,走一条去往跟结点的路径,这样便得到了该叶子结点对应的huffman编码的逆序列,有了逆序列,自然就可以得到正序列了。第一个参数是一个存储叶子结点的数组,第二个参数是数组元素个数,第三个参数会返回最终每一个叶子结点对应的huffman编码,以便后文使用。
1 int huffman_decode_internal(HuffmanNode **huffman_tree_current_root, long direction); 2 int huffman_decode(HuffmanNode *huffman_tree_root, HuffmanNode **last_stop_at, EncodeBuffer *encode_buffer, DecodeBuffer *decode_buffer);
huffman解码部分对应着业务逻辑中的‘解压缩’这个概念,为了使得代码逻辑清晰,解码功能被拆分为两个函数。huffman_decode()会在内部调用huffman_decode_internal() 。其具体功能将在后文的源代码部分有比较详细的解析,这里大概描述下解码的功能:首先解码需要根据huffman树来解码,因此会有其他函数来负责根据压缩文件头里的编码表来恢复哈夫曼树。其次需要读取压缩文件的正文到内存缓冲区里面,这正是我们要解码的对象。最后解码后的结果要存储在两外一块内存缓冲区里面,等待最后写入磁盘。
1 int bit_set(unsigned char *ch, long index, long flag); 2 int open_file(char *filename, FILE **fp); 3 int creat_file(char *filename, FILE **fp); 4 int make_uchar_weight(FILE *fp, HuffmanNode **huffman_node, long *size); 5 int create_Uncompress_file(char *filename, FILE **fp);
上述有5个函数,除了bit_set()外,其余四个都是打开、创建文件之类的,比较简单不在赘述。bit_set()的功能是把特定字节*ch的第index个bit设置为0或者1,具体根据flag的指示。
1 int Jcompress(char *src_name); 2 int JparseHead(FILE **fp, HuffmanEncode *huffman_encode_array, char **file_name, long *last_bits); 3 int JUnCompress(char *src_name); 4 int restore_huffman_tree(HuffmanNode **huffman_tree_root, HuffmanEncode *huffman_encode_array);
上述四个函数是比较重要的业务逻辑函数,他们在1,2,3 中描述的函数的基础上负责上层的压缩、解压缩逻辑。Jcompress()是用来对文件进行压缩的,而后三个函数是为了解压缩的,首先JparseHead()会读取压缩文件的头部,并且解析出必要的信息,比如编码表,然后restore_huffman_tree()会根据解析出的编码表来重建huffman树,这个重建的huffman树与压缩时创建的huffman树一模一样,否则的话解码出的结果就是不正确的。而JUnCompress()会在这两个函数的基础上做具体的解压缩操作。
?最小堆排序算法基本上是按照<数据结构>严蔚敏版的算法来实现的,其具体功能这里不再赘述,仅列出代码,读者可以参考课本自行分析之。首先是heap_min_adjust,也就是调整堆,代码如下所示:
1 int heap_min_adjust(HuffmanNode **huffman_node_array, long data_start, long data_end){ 2 /** 3 ** check error for argument 4 */ 5 if(huffman_node_array==NULL || data_start<0 || data_end<0 || data_end<data_start){ 6 printf("heap_min_adjust: argument error\n"); 7 exit(0); 8 } 9 10 if(data_end==data_start) return 1; 11 /** 12 ** the top of heap-min indicated by index data_start is the only element 13 ** which need to be adjusted to make a min-heap 14 */ 15 HuffmanNode * current_data_tobe_adjust=huffman_node_array[data_start]; 16 long current_indexof_data=data_start; 17 18 for(long cur=2*data_start;cur<=data_end;cur=2*cur){ 19 if(cur<data_end){ 20 /** compare the left child and right child to find the min one */ 21 if(((huffman_node_array[cur])->data_8bit_count)>((huffman_node_array[cur+1])->data_8bit_count)){ 22 cur+=1; 23 } 24 } 25 if((current_data_tobe_adjust->data_8bit_count)<=((huffman_node_array[cur])->data_8bit_count)) 26 break; 27 huffman_node_array[current_indexof_data]=huffman_node_array[cur]; 28 current_indexof_data=cur; 29 } 30 huffman_node_array[current_indexof_data]=current_data_tobe_adjust; 31 /** 32 ** return 1 means everything is ok 33 */ 34 return 1; 35 }
接下来是heap_min_construct()的代码,此函数是通过不断的调用上面的调整堆的函数来达到堆排序的目的。
1 int heap_min_construct(HuffmanNode **huffman_node_array, long array_size){ 2 /** valid data start from index 1 not 0 */ 3 4 /** 5 ** check error for argument 6 */ 7 if(huffman_node_array==NULL || array_size<=0 || array_size>256){ 8 printf("heap_min_construct: argument error\n"); 9 exit(0); 10 } 11 12 for(long HeapRoot=array_size/2; HeapRoot>=1;HeapRoot--){ 13 heap_min_adjust(huffman_node_array,HeapRoot,array_size); 14 } 15 return 1; 16 }
最后是heap_min_get2min()函数
1 int heap_min_get2min(HuffmanNode **huffman_node_array, HuffmanNode **min_first, HuffmanNode **min_second, long *heap_size){ 2 3 /** 4 ** check argument 5 **/ 6 if(huffman_node_array==NULL){ 7 printf("heap_min_get2min: argument error\n"); 8 exit(0); 9 } 10 11 *min_first=huffman_node_array[1]; 12 huffman_node_array[1]=huffman_node_array[*heap_size]; 13 (*heap_size)-=1; 14 /** after we get the min data, we should again adjust the heap to make a min-heap */ 15 heap_min_adjust(huffman_node_array,1,*heap_size); 16 17 *min_second=huffman_node_array[1]; 18 huffman_node_array[1]=huffman_node_array[*heap_size]; 19 (*heap_size)-=1; 20 21 /** the same as above*/ 22 if(*heap_size>0){ 23 heap_min_adjust(huffman_node_array,1,*heap_size); 24 } 25 26 return 1; 27 }
?哈夫曼编码部分的代码也是基本和<数据结构>课本上的一致,这里也仅给出代码,读者如有不明白的地方可参考课本中的描述。
1 int huffman_tree(HuffmanNode **huffman_tree_root, HuffmanNode **huffman_node_array, long array_size){ 2 /** 3 ** check error for argument 4 */ 5 if(huffman_node_array==NULL || array_size<1 || array_size>256){ 6 printf("huffman_tree:argument error\n "); 7 exit(0); 8 } 9 10 if(array_size==1){ 11 printf("huffman_tree: \nnode size: %ld too small to construct huffman tree\ntry a bigger file\n",array_size); 12 exit(0); 13 } 14 15 long heap_size=array_size; 16 HuffmanNode *huffman_parent_node=(HuffmanNode *)malloc(sizeof(HuffmanNode)*(array_size-1+1)); 17 for(long i=1;i<=array_size-1;i++){ 18 (huffman_parent_node+i)->data_8bit=0x00; 19 (huffman_parent_node+i)->data_8bit_count=0; 20 (huffman_parent_node+i)->left_child=NULL; 21 (huffman_parent_node+i)->right_child=NULL; 22 (huffman_parent_node+i)->parent=NULL; 23 } 24 25 heap_min_construct(huffman_node_array,array_size); 26 27 HuffmanNode *min1; 28 HuffmanNode *min2; 29 30 for(long i=1;i<=array_size-1;i++){ 31 heap_min_get2min(huffman_node_array,&min1,&min2,&heap_size); 32 33 huffman_parent_node[i].data_8bit=0x00; 34 huffman_parent_node[i].data_8bit_count=min1->data_8bit_count+min2->data_8bit_count; 35 huffman_parent_node[i].left_child=min1; 36 huffman_parent_node[i].right_child=min2; 37 huffman_parent_node[i].parent=NULL; 38 39 min1->parent=&(huffman_parent_node[i]); 40 min2->parent=&(huffman_parent_node[i]); 41 42 /** insert parent node and again make min heap*/ 43 heap_size+=1; 44 huffman_node_array[heap_size]=&(huffman_parent_node[i]); 45 heap_min_construct(huffman_node_array,heap_size); 46 47 } 48 if(huffman_parent_node[array_size-1].parent==NULL){ 49 50 *huffman_tree_root=&(huffman_parent_node[array_size-1]); 51 } 52 else{ 53 printf("huffman tree construct failed\n"); 54 exit(0); 55 } 56 return 1; 57 }
1 int huffman_encode(HuffmanNode **huffman_node_array, long huffman_node_array_size, HuffmanEncode *huffman_encode_array){ 2 /** 3 ** check error for argument 4 */ 5 if(huffman_node_array==NULL || huffman_encode_array==NULL || huffman_node_array_size<1 || 6 huffman_node_array_size>256){ 7 printf("huffman_encode: argument error\n"); 8 exit(0); 9 } 10 11 if(huffman_node_array_size==1){ 12 printf("huffman_encode: node array size too small to construct huffman encode\n"); 13 exit(0); 14 } 15 16 HuffmanNode **huffman_node_array_backup=(HuffmanNode **)malloc((huffman_node_array_size+1)* 17 sizeof(HuffmanNode *)); 18 if(NULL==huffman_node_array_backup){ 19 printf("malloc failed\n"); 20 exit(0); 21 } 22 23 /** 24 ** later we will use this backup to make huffman encode 25 ** note: backup should before invoking huffman_tree(),because this function will 26 ** change array huffman_node_array 27 */ 28 29 for(long i=1;i<=huffman_node_array_size;i++){ 30 huffman_node_array_backup[i]=huffman_node_array[i]; 31 } 32 33 HuffmanNode *huffman_tree_root=NULL; 34 huffman_tree(&huffman_tree_root, huffman_node_array, huffman_node_array_size); 35 36 /** 37 ** construct huffmanencode, traverse huffman tree, left encode 0, right encode 1 38 */ 39 40 char encode_temp[260]; 41 long start_temp=259; 42 43 for(long i=1;i<=huffman_node_array_size;i++){ 44 start_temp=259; 45 46 HuffmanNode *leaf=huffman_node_array_backup[i]; 47 //printf("node index and count: %d , ", i); 48 //printf("%d ",leaf->data_8bit_count); 49 while(leaf->parent!=NULL){ 50 HuffmanNode *parent=leaf->parent; 51 if(parent->left_child==leaf){ 52 53 encode_temp[start_temp--]=‘0‘;//printf("0"); 54 55 }else if(parent->right_child==leaf){ 56 57 encode_temp[start_temp--]=‘1‘;//printf("1"); 58 59 }else{ 60 61 printf("the huffman tree we reference seems not correct\n"); 62 exit(0); 63 64 } 65 66 leaf=leaf->parent; 67 } 68 69 /** I have make a low level error to use dat_8bit_count which cause error*/ 70 long huffman_encode_array_index=huffman_node_array_backup[i]->data_8bit; 71 72 huffman_encode_array[huffman_encode_array_index].encode=(char *)malloc((259-start_temp)*sizeof(char)); 73 if(huffman_encode_array[huffman_encode_array_index].encode==NULL){ 74 printf("huffman_encode: malloc failed\n"); 75 exit(0); 76 } 77 78 huffman_encode_array[huffman_encode_array_index].length_of_encode=259-start_temp; 79 memcpy(huffman_encode_array[huffman_encode_array_index].encode, encode_temp+start_temp+1, 259-start_temp); 80 81 } 82 83 if(huffman_node_array_backup!=NULL){ 84 free(huffman_node_array_backup); 85 huffman_node_array_backup=NULL; 86 } 87 88 return 1; 89 }
?huffman解码功能由两个函数承担,我们先看其中的一个函数huffman_decode_internal()。我们知道,解码的大概流程是:先把磁盘里的压缩文件读入内存中,然后遍历内存中的bit,根据bit的值从哈夫曼树跟结点一直往下走,直至叶子结点,我们便解析出了一个unsigned char类型的数据。当然从根结点到叶子结点是一步一步走下来的,而这其中的“每走一步”的功能便是由下面这个函数来实现的。此函数的第一个参数是一个指针,指针的内容又是一个指向HuffmanNode的指针,该指针也即*huffman_tree_current_root表示当前已经走到了某个特定的结点上,direction表示方向,其值是根据压缩文件里面的bit值而得到的,bit是0则direction便是0,否则是1.direction代码了从当前位置*huffman_tree_current_root处应该往哪个方向走。当然在本文中0意味着往左走,1意味着往右走。
?当然每走一步,就会走到一个新的位置处,该位置可能是非叶子结点,也可能是叶子结点。如果走了一步后发现还是非叶子结点,则函数会返回到调用的函数里面,而调用者会继续读内存中的bit,并根据其值来决定下一步的走法。如果是叶子结点,则返回1给调用者,这时候调用者根据返回值1判断当前已经解析出了一个unsigned char,于是便会把这个解析出来的unsigned char写入另外一个内存缓冲区里,解析出unsigned char后,调用者会继续读压缩文件内存中的bit并一直按照这个方法走下去。这里所说的调用者函数便是下面将要介绍的huffman_decode()函数。
1 int huffman_decode_internal(HuffmanNode **huffman_tree_current_root, long direction){ 2 /** 3 ** check error for argument 4 */ 5 if(huffman_tree_current_root==NULL || *huffman_tree_current_root==NULL || !(direction==0 || direction==1)){ 6 printf("huffman_decode_internal: argument error\n"); 7 exit(0); 8 } 9 10 if(direction==0){ 11 (*huffman_tree_current_root)=(*huffman_tree_current_root)->left_child; 12 if((*huffman_tree_current_root)->left_child==NULL && 13 (*huffman_tree_current_root)->right_child==NULL){ 14 return 1; 15 }else{ 16 return 0; 17 } 18 }else if(direction==1){ 19 (*huffman_tree_current_root)=(*huffman_tree_current_root)->right_child; 20 if((*huffman_tree_current_root)->left_child==NULL && 21 (*huffman_tree_current_root)->right_child==NULL){ 22 return 1; 23 }else{ 24 return 0; 25 } 26 }else{ 27 printf("\ndirection error: %ld\n",direction); 28 exit(0); 29 } 30 31 }
huffman_decode函数会被它的调用者多次反复调用,直至压缩文件被处理完毕。第一个参数huffman_tree_root是重建出来的哈夫曼树的根结点指针,重建的动作由huffman_decode()的调用者函数负责构造,然后直接以参数的形式传递给huffman_decode()。第二个参数last_stop_at实际上就是传递给huffman_decode_interanl()函数的第一个参数,也即负责记录当前走到哈夫曼树的哪一个结点上了。encode_buffer是一个内存缓冲区,huffman_decode()的调用者函数会把压缩文件分块读入encode_buffer所代表的内存缓冲区中,并作为参数传递给huffman_decode()函数来做相应的解码工作。解码的结果会写到第四个参数decode_buffer所代表的内存缓冲区中。
这里有一点需要读者特别注意的地方,前文我们说过,经过压缩的后的文件所包含的有效的bit数量不一定是8的整数倍,这也就意味着压缩文件中最后一块被读入内存缓冲区encode_buffer中的数据需要特别处理,具体来说是该块缓冲区的最后一个字节需要特殊处理。压缩文件头里会记录最后一个字节有多少个有效bit数量,按照这个数量来处理就行了。
1 int huffman_decode(HuffmanNode *huffman_tree_root, HuffmanNode **last_stop_at, EncodeBuffer *encode_buffer, DecodeBuffer *decode_buffer){ 2 3 /** 4 ** check error for argument 5 */ 6 if(NULL==last_stop_at || encode_buffer==NULL || decode_buffer==NULL){ 7 printf("huffman_decode: argument error\n"); 8 exit(0); 9 } 10 11 long not_full_byte=0; 12 long bits_num_ofLastByte=0; 13 if(encode_buffer->bits_num_lastbytes>0){ 14 not_full_byte=1; 15 bits_num_ofLastByte=encode_buffer->bits_num_lastbytes; 16 } 17 18 if(*last_stop_at==NULL){ 19 *last_stop_at=huffman_tree_root; 20 } 21 22 if(decode_buffer->size!=0){ 23 decode_buffer->size=0; 24 } 25 26 long buffer_size_real=0; 27 buffer_size_real=encode_buffer->size; 28 29 unsigned char * ptr_current_buffer=encode_buffer->buffer; 30 unsigned char * ptr_endOf_real_buffer=encode_buffer->buffer+buffer_size_real-1; 31 long return_value=-1; 32 for(;ptr_current_buffer<=ptr_endOf_real_buffer;ptr_current_buffer++){ 33 34 unsigned char temp=*ptr_current_buffer; 35 for(long i=0;i<8;i++){ 36 unsigned char bit_for_test=0x80; 37 bit_for_test=bit_for_test>>i; 38 long direction; 39 if(bit_for_test&temp){ direction=1;} 40 else{ direction=0;} 41 return_value=huffman_decode_internal(last_stop_at,direction); 42 if(return_value==1){ 43 decode_buffer->buffer[decode_buffer->size]=(*last_stop_at)->data_8bit; 44 (decode_buffer->size)+=1; 45 46 (*last_stop_at)=huffman_tree_root; 47 } 48 } 49 50 } 51 52 if(not_full_byte==1){ 53 unsigned char temp=(encode_buffer->buffer[encode_buffer->size]); 54 for(long i=0;i<bits_num_ofLastByte;i++){ 55 unsigned char bit_for_test=0x80; 56 bit_for_test=bit_for_test>>i; 57 long direction; 58 if(bit_for_test&temp){direction=1;} 59 else{direction=0;} 60 return_value=huffman_decode_internal(last_stop_at,direction); 61 if(return_value==1){ 62 decode_buffer->buffer[decode_buffer->size]=(*last_stop_at)->data_8bit; 63 (decode_buffer->size)+=1; 64 65 (*last_stop_at)=huffman_tree_root; 66 } 67 } 68 } 69 return 1; 70 }
?前文所述业务逻辑部分有几个关于文件操作、位操作等函数功能比较简单,在这里略去,我们只对比较重要的几个函数做一个简要的分析。下面的这个Jcompress函数便是用来实现压缩功能的业务逻辑的。它只有一个参数,便是打算压缩的那个文件的名称,当然它可以是任意格式的。该函数的执行步骤包括:
?这个函数里面定义了两个重要的变量:num_ofbits_write和num_ofbits_write_per_while,前者记录截止当前累计写入内存缓冲区中的bit数量,而后者记录的是每一次fread读入的数据块所对应的经压缩后的bit数量。前文我们说过,每一次fread的数据块处理后得到的bit数量不一定是8的倍数,然后我们把余数写入到缓冲区的开头。那么下一次fread的数据对应的经处理后的bit怎么避免覆盖上一次fread产生的不能整除8的那几个bit呢?我们只需要在while循环开头处使用(num_ofbits_write+1)除以8得到一个偏移量,然后在这个偏移量的后面接着写数据就行了。至此为止压缩过程已经分析完毕,其代码如下所示:
1 int Jcompress(char *src_name){ 2 /** 3 ** check argument 4 **/ 5 if(src_name==NULL){ 6 printf("Jcompress: argument error\n"); 7 exit(0); 8 } 9 printf("******************Jcompress begin to execute************\n"); 10 printf("source file name : %s\n",src_name); 11 char *dst_name=(char *)malloc(strlen(src_name)+6+1); 12 memcpy(dst_name,src_name,strlen(src_name)); 13 char *cur0=dst_name+strlen(src_name); 14 memcpy(cur0,".jcprs",6); 15 *(cur0+6)=‘\0‘; 16 printf("compress file name: %s\n",dst_name); 17 FILE *src_fp=NULL; 18 FILE *dst_fp=NULL; 19 open_file(src_name,&src_fp); 20 creat_file(dst_name,&dst_fp); 21 22 HuffmanNode **huffman_node_array=(HuffmanNode **)malloc(257*sizeof(HuffmanNode *)); 23 if(huffman_node_array==NULL){ 24 printf("Jcompress: malloc failed\n"); 25 exit(0); 26 } 27 long huffman_node_num=0; 28 make_uchar_weight(src_fp,huffman_node_array,&huffman_node_num); 29 30 HuffmanEncode *encode_array=(HuffmanEncode *)malloc(257*sizeof(HuffmanEncode)); 31 if(encode_array==NULL){ 32 printf("Jcompress: malloc failed\n"); 33 exit(0); 34 } 35 for(long i=0;i<257;i++){ 36 encode_array[i].encode=NULL; 37 encode_array[i].length_of_encode=0; 38 } 39 huffman_encode(huffman_node_array, huffman_node_num, encode_array); 40 41 /** 42 ** begin to deal with the header of the compress file, later the uncompress routine 43 ** can read the header and restore the huffman tree then uncompress the file 44 */ 45 46 47 CompressFileHeader CFH; 48 CFH.length_of_author_name=8; 49 CFH.author_name="zhangjun"; 50 CFH.routine_name_length=9; 51 CFH.routine_name="Jcompress"; 52 CFH.suffix_length=5; 53 CFH.suffix="jcprs"; 54 CFH.file_name_length=strlen(src_name); 55 CFH.bits_of_lastByte=0x00; 56 57 long length_of_header1=0; 58 long length_of_header2=0; 59 char *cur=src_name; 60 while(cur[length_of_header1++]!=‘\0‘); 61 length_of_header1+=2*sizeof(long)+9+10+6+1; 62 length_of_header2=length_of_header1; 63 64 for(long i=0;i<256;i++){ 65 if(encode_array[i].length_of_encode==0){ 66 length_of_header2=length_of_header2+1; 67 } 68 else if(encode_array[i].length_of_encode>0){ 69 length_of_header2=length_of_header2+1+ 70 encode_array[i].length_of_encode; 71 } 72 } 73 74 unsigned char *buffer_for_header=(unsigned char*)malloc(sizeof(unsigned char)*length_of_header2); 75 76 if(buffer_for_header==NULL){ 77 printf("Jcompress:malloc failed for buffer_for_header\n"); 78 exit(0); 79 } 80 81 unsigned char *ptr=buffer_for_header; 82 *((long *)ptr)=length_of_header1; 83 *((long *)(ptr+sizeof(long)))=length_of_header2; 84 ptr+=2*sizeof(long); 85 *(ptr++)=(unsigned char)CFH.length_of_author_name; 86 *(ptr++)=(unsigned char)CFH.routine_name_length; 87 *(ptr++)=(unsigned char)CFH.suffix_length; 88 *(ptr++)=(unsigned char)CFH.file_name_length; 89 *(ptr++)=(unsigned char)CFH.bits_of_lastByte; 90 91 char *ch="zhangjunJcompressjcprs"; 92 memcpy(ptr,ch,22); 93 ptr+=22; 94 memcpy(ptr,src_name,CFH.file_name_length); 95 ptr+=CFH.file_name_length; 96 97 for(long i=0;i<256;i++){ 98 if(encode_array[i].length_of_encode==0){ 99 *ptr=0x00; 100 ptr+=1; 101 }else{ 102 *ptr=encode_array[i].length_of_encode; 103 ptr++; 104 memcpy(ptr,encode_array[i].encode,encode_array[i].length_of_encode); 105 ptr+=encode_array[i].length_of_encode; 106 } 107 } 108 109 long temp=fwrite(buffer_for_header,length_of_header2,1,dst_fp); 110 if(temp!=1){ 111 printf("Jcompress: fwrite for compress file header error\n"); 112 exit(0); 113 } 114 115 EncodeBuffer *encode_buffer=(EncodeBuffer *)malloc(sizeof(EncodeBuffer)); 116 if(encode_buffer==NULL){ 117 printf("Jcompress: malloc failed\n"); 118 exit(0); 119 } 120 121 encode_buffer->bits_num_lastbytes=0; 122 encode_buffer->buffer=NULL; 123 encode_buffer->size=0; 124 const long fread_buffer_size=4*1024*1024; 125 const long encode_buffer_size=32*fread_buffer_size; 126 encode_buffer->buffer=(unsigned char *)malloc(encode_buffer_size*sizeof(unsigned char)); 127 if(encode_buffer->buffer==NULL){ 128 printf("Jcompress: malloc failed\n"); 129 exit(0); 130 } 131 132 unsigned char * fread_buffer=(unsigned char *)malloc(fread_buffer_size*sizeof(unsigned char)); 133 if(fread_buffer==NULL){ 134 printf("Jcompress: malloc failed\n"); 135 exit(0); 136 } 137 138 139 140 long read_bytes=0; 141 fseek(src_fp,0L, SEEK_SET); 142 /**I have made an error define num_ofbits_write as long which cause bigger file compress wrongly*/ 143 long long num_ofbits_write=-1; 144 while((read_bytes=fread(fread_buffer,sizeof(unsigned char),fread_buffer_size,src_fp))!=0){ 145 unsigned char *ptr=fread_buffer; 146 unsigned char *ptr_end=fread_buffer+read_bytes; 147 long num_ofbits_write_per_while=-1; 148 if(num_ofbits_write>=0){ 149 num_ofbits_write_per_while+=(num_ofbits_write+1)%8; 150 } 151 for(;ptr!=ptr_end;ptr++){ 152 long index=(long)(*ptr); 153 if(encode_array[index].length_of_encode<=0){ 154 printf("Jcompress : encode_array not correct\n"); 155 exit(0); 156 } 157 158 for(long i=0;i<encode_array[index].length_of_encode;i++){ 159 num_ofbits_write++; 160 num_ofbits_write_per_while++; 161 long byte_index=num_ofbits_write_per_while/8; 162 long bit_index=num_ofbits_write%8; 163 long flag=(long)(encode_array[index].encode[i]-‘0‘); 164 bit_set((encode_buffer->buffer)+byte_index, bit_index, flag); 165 166 } 167 } 168 169 encode_buffer->size=((num_ofbits_write_per_while+1)/8); 170 encode_buffer->bits_num_lastbytes=((num_ofbits_write+1)%8); 171 long fwrite_size=encode_buffer->size; 172 long real_write_num=fwrite(encode_buffer->buffer,sizeof(unsigned char),fwrite_size,dst_fp); 173 if(real_write_num!=fwrite_size){ 174 printf("Jcompress : fwrite error\n"); 175 exit(0); 176 } 177 if(encode_buffer->bits_num_lastbytes>0){ 178 *(encode_buffer->buffer)=*(encode_buffer->buffer+encode_buffer->size); 179 } 180 181 182 } 183 184 if((num_ofbits_write+1)%8!=0){ 185 long temp=fwrite(encode_buffer->buffer,sizeof(unsigned char),1,dst_fp); 186 if(temp!=1){ 187 printf("Jcompress: fwrite error\n"); 188 exit(0); 189 } 190 CFH.bits_of_lastByte=(num_ofbits_write+1)%8; 191 } 192 193 /** 194 ** now set the correct bits_of_lastByte of the compress file header 195 */ 196 197 198 *(buffer_for_header+2*sizeof(long)+4)=CFH.bits_of_lastByte; 199 fseek(dst_fp,0L, SEEK_SET); 200 long temp0=fwrite(buffer_for_header,1,2*sizeof(long)+5,dst_fp); 201 if(temp0!=(2*sizeof(long)+5)){ 202 printf("Jcompress: fwrite error\n"); 203 exit(0); 204 } 205 206 printf("Jcompress: succeed\n"); 207 208 return 1; 209 }
restore_huffman_tree()根据参数huffman_encode_array存储的编码表来重建哈夫曼树,重建的哈夫曼树根结点的指针存储在huffman_tree_root所指向的内存中。重建的过程也很简单,对于每一个usigned char,根据其编码,从哈夫曼树跟结点一遍走一遍构造子结点,便可以非常自然地重现哈夫曼树。这颗哈夫曼树在后文解压缩的时候会使用到。
1 int restore_huffman_tree(HuffmanNode **huffman_tree_root, HuffmanEncode *huffman_encode_array){ 2 /** 3 ** check error for argument 4 */ 5 if(huffman_tree_root==NULL || huffman_encode_array==NULL){ 6 printf("restore_huffman_tree: argument error\n"); 7 exit(0); 8 } 9 10 long valid_encode_num=0; 11 for(long i=0;i<256;i++){ 12 if(huffman_encode_array[i].length_of_encode>0){ 13 valid_encode_num+=1; 14 } 15 } 16 17 HuffmanNode *huffman_nodes=(HuffmanNode *)malloc(sizeof(HuffmanNode)*(valid_encode_num*2-1)); 18 19 if(huffman_nodes==NULL){ 20 printf("\nrestore_huffman_tree: malloc failed\n"); 21 exit(0); 22 } 23 24 25 for(long i=0;i<valid_encode_num*2-1;i++){ 26 huffman_nodes[i].left_child=NULL; 27 huffman_nodes[i].right_child=NULL; 28 huffman_nodes[i].parent=NULL; 29 } 30 31 32 long huffman_nodes_index=0; 33 (*huffman_tree_root)=&(huffman_nodes[huffman_nodes_index++]); 34 35 for(long i=0;i<256;i++){ 36 if(huffman_encode_array[i].length_of_encode>0){ 37 HuffmanNode *current=(*huffman_tree_root); 38 for(long j=0;j<huffman_encode_array[i].length_of_encode;j++){ 39 if(huffman_encode_array[i].encode[j]==‘0‘){ 40 41 if(current->left_child!=NULL) current=current->left_child; 42 else{ 43 current->left_child=&(huffman_nodes[huffman_nodes_index++]); 44 current->left_child->parent=current; 45 current=current->left_child; 46 } 47 48 }else if(huffman_encode_array[i].encode[j]==‘1‘){ 49 50 if(current->right_child!=NULL) current=current->right_child; 51 else{ 52 current->right_child=&(huffman_nodes[huffman_nodes_index++]); 53 current->right_child->parent=current; 54 current=current->right_child; 55 } 56 57 }else{ 58 printf("restore_huffman_tree: encode array error\n"); 59 exit(0); 60 } 61 } 62 current->data_8bit=(unsigned char)i; 63 64 } 65 } 66 return 1; 67 68 }
JparseHead()函数负责在解压缩的过程当中分析压缩文件的头部,解析出一些必要的信息,包括:编码表,最后一个字节有效bit数量等。函数的第一个参数是一个文件指针的指针,fp是由调用者在打开压缩文件后得到的并将它作为参数传递给JparseHead. 第二个参数存储JparseHead()得到的编码表,该编码表会被传递给restore_huffman_tree()以重建哈夫曼树。file_name存储的是一个指针,该指针指向解析出的原始文件名称,最后一个参数last_bits存储的便是解析出来的最后一个字节包含的有效bit数量。各种必要的信息都是按照特定的顺序存储在压缩文件的头部,把它们解析出来是一件很自然的事情,详情见下面的代码:
1 int JparseHead(FILE **fp, HuffmanEncode *huffman_encode_array, char **file_name, long *last_bits){ 2 /** 3 ** check error for argument 4 */ 5 if(fp==NULL || *fp==NULL || huffman_encode_array==NULL || file_name==NULL || last_bits==NULL){ 6 printf("JparseHead: argument error\n"); 7 exit(0); 8 } 9 long sizeof_header1=0; 10 long sizeof_header2=0; 11 12 unsigned char *buffer=(unsigned char* )malloc(sizeof(long)*2); 13 long read_num=fread(buffer,sizeof(long),2,*fp); 14 if(read_num!=2){ 15 printf("JparseHead: read first two long of header failed\n"); 16 exit(0); 17 } 18 sizeof_header1=*((long *)buffer); 19 sizeof_header2=*((long *)(buffer+sizeof(long))); 20 21 if(buffer!=NULL){ 22 free(buffer); 23 buffer=NULL; 24 } 25 /** I have make a silly error to use sizeof(sizeof_header2) which take lots of time to debug*/ 26 unsigned char *buffer_header=(unsigned char *)malloc(sizeof(unsigned char)*sizeof_header2); 27 28 if(buffer_header==NULL){ 29 printf("JparseHead: malloc for buffer_header failed\n"); 30 exit(0); 31 } 32 33 fseek(*fp,0L, SEEK_SET); 34 35 read_num=fread(buffer_header,sizeof(unsigned char),sizeof_header2,*fp); 36 37 if(read_num!=sizeof_header2){ 38 printf("JparseHead: fread failed\n"); 39 exit(0); 40 } 41 42 unsigned char * ptr_header1=buffer_header; 43 unsigned char * ptr_header1_end=buffer_header+sizeof_header1; 44 45 unsigned char * ptr_header2=buffer_header+sizeof_header1; 46 unsigned char * ptr_header2_end=buffer_header+sizeof_header2; 47 48 ptr_header1+=sizeof(long)*2; 49 50 long length_of_author_name=*(ptr_header1); 51 long length_of_routine_name=*(ptr_header1+1); 52 long length_of_suffix=*(ptr_header1+2); 53 long length_of_file_name=*(ptr_header1+3); 54 long length_of_lastbits=*(ptr_header1+4); 55 ptr_header1+=5; 56 57 *last_bits=length_of_lastbits; 58 59 printf("\nJcompress author: "); 60 unsigned char *ptr=NULL; 61 long i=0; 62 for(i=1,ptr=ptr_header1;i<=length_of_author_name;ptr++,i++){ 63 printf("%c",*ptr); 64 } 65 printf("\ncompress routine is: "); 66 for(long i=1;i<=length_of_routine_name;ptr++,i++){ 67 printf("%c",*ptr); 68 } 69 printf("\ncompress suffix is: "); 70 for(long i=1;i<=length_of_suffix;ptr++,i++){ 71 printf("%c",*ptr); 72 } 73 74 (*file_name)=(char *)malloc(sizeof(char)*(length_of_file_name+1)); 75 if(file_name==NULL){ 76 printf("JparseHeader: malloc failed\n"); 77 exit(0); 78 } 79 memcpy((*file_name),ptr,length_of_file_name); 80 (*file_name)[length_of_file_name]=‘\0‘; 81 82 printf("\noriginal file name is: "); 83 for(long i=1;i<=length_of_file_name;ptr++,i++){ 84 printf("%c",*ptr); 85 } 86 printf("\n"); 87 long index=-1; 88 unsigned char *cur=ptr_header2; 89 while(cur<ptr_header2_end){ 90 index++; 91 if(*cur==0x00){ 92 cur++; 93 }else{ 94 huffman_encode_array[index].encode=(char *)malloc((*cur)*sizeof(char)); 95 if(huffman_encode_array[index].encode==NULL){ 96 printf("JparseHead: malloc failed\n"); 97 exit(0); 98 } 99 huffman_encode_array[index].length_of_encode=*cur; 100 memcpy(huffman_encode_array[index].encode,cur+1,*cur); 101 cur=cur+1+huffman_encode_array[index].length_of_encode; 102 103 } 104 105 } 106 107 if(buffer_header!=NULL){ 108 free(buffer_header); 109 buffer_header=NULL; 110 } 111 112 return 1; 113 }
JUnCompress()是本文要介绍的最后一个函数,它是用来解压缩文件的,该函数的实现基于上文介绍的JparseHead()和restore_huffman_tree()函数。其参数src_name存储的是待解压缩的文件的名称。在介绍完前文的一系列函数之后在回过头来看JUnCompress()的代码,其逻辑也比较清晰易懂。它首先调用JparseHead()函数来解析压缩文件的头部,解析出来的哈夫曼编码表交给restore_huffman_tree()来重建哈夫曼树。再往下是一个while循环,该循环不断地调用fread函数来读磁盘中的压缩文件。每读一块交交给huffman_decode()函数来解码,解码而得的数据会被存储到一个新的磁盘文件里。同样在这里也要注意读入的压缩文件bit数量不能被8整除的情况。
1 int JUnCompress(char *src_name){ 2 /** 3 ** check error for argument 4 */ 5 6 if(access(src_name,0)!=0){ 7 printf("file not exist\n"); 8 exit(0); 9 } 10 printf("\n******************UnCompress file begin******************\n"); 11 printf("compress file name is: %s\n",src_name); 12 FILE *ptr_src=NULL; 13 open_file(src_name,&ptr_src); 14 long compress_file_size=0; 15 fseek(ptr_src,0L,SEEK_END); 16 compress_file_size=ftell(ptr_src); 17 if(compress_file_size==-1){ 18 printf("compress file too big to display its size(bigger than 2.1G)\nbut Jcompress will run normally\n"); 19 }else{ 20 printf("compress file size: %ld bytes\n",compress_file_size); 21 } 22 fseek(ptr_src,0L, SEEK_SET); 23 24 long last_bits=0; 25 char *file_name=NULL; 26 HuffmanEncode *huffman_encode_array=(HuffmanEncode *)malloc(sizeof(HuffmanEncode)*256); 27 28 if(huffman_encode_array==NULL){ 29 printf("JUnCompress: malloc huffman_encode_array failed\n"); 30 exit(0); 31 } 32 33 for(int i=0;i<256;i++){ 34 huffman_encode_array[i].encode=NULL; 35 huffman_encode_array[i].length_of_encode=0; 36 } 37 38 JparseHead(&ptr_src,huffman_encode_array,&file_name,&last_bits); 39 HuffmanNode *huffman_tree_root=NULL; 40 restore_huffman_tree(&huffman_tree_root,huffman_encode_array); 41 42 //test_traverse_prlong long_hfmtree(huffman_tree_root,-1); 43 FILE *ptr_dst=NULL; 44 create_Uncompress_file(file_name,&ptr_dst); 45 46 EncodeBuffer *encode_buffer=(EncodeBuffer *)malloc(sizeof(EncodeBuffer)); 47 DecodeBuffer *decode_buffer=(DecodeBuffer *)malloc(sizeof(DecodeBuffer)); 48 if(encode_buffer==NULL || decode_buffer==NULL){ 49 printf("JUnCompress: encode/decode buffer malloc failed\n"); 50 exit(0); 51 } 52 53 encode_buffer->bits_num_lastbytes=0; 54 encode_buffer->buffer=NULL; 55 encode_buffer->size=0; 56 57 const long enbuffer_size=8*1024*1024; 58 const long debuffer_size=10*enbuffer_size; 59 encode_buffer->buffer=(unsigned char *)malloc(enbuffer_size*sizeof(unsigned char)); 60 if(encode_buffer->buffer==NULL){ 61 printf("JUnCompress: EncodeBuffer->buffer malloc failed\n"); 62 exit(0); 63 } 64 65 decode_buffer->size=0; 66 decode_buffer->buffer=(unsigned char *)malloc(debuffer_size*sizeof(unsigned char)); 67 if(decode_buffer->buffer==NULL){ 68 printf("JUnCompress: EncodeBuffer->buffer malloc failed\n"); 69 exit(0); 70 } 71 72 long long read_compress_file_size=0; 73 long read_bytes=0; 74 HuffmanNode *last_stop_at=NULL; 75 while((read_bytes=fread(encode_buffer->buffer,sizeof(unsigned char),enbuffer_size,ptr_src))!=0){ 76 read_compress_file_size+=read_bytes; 77 if(read_compress_file_size==compress_file_size){ 78 if(last_bits>0){ 79 encode_buffer->bits_num_lastbytes=last_bits; 80 encode_buffer->size=read_bytes-1; 81 }else{ 82 encode_buffer->bits_num_lastbytes=0; 83 encode_buffer->size=read_bytes; 84 } 85 }else{ 86 encode_buffer->bits_num_lastbytes=0; 87 encode_buffer->size=read_bytes; 88 } 89 90 huffman_decode(huffman_tree_root,&last_stop_at,encode_buffer,decode_buffer); 91 long write_bytes=fwrite(decode_buffer->buffer,sizeof(unsigned char),decode_buffer->size,ptr_dst); 92 if(write_bytes!=decode_buffer->size){ 93 printf("JUnCompress: fwrite failed\n"); 94 exit(0); 95 } 96 97 } 98 99 printf("UnCompress file succeed\n"); 100 101 return 1; 102 }
?至此,本文就已经叙述完毕,完整的Jcompress小程序代码,读者可以到笔者的github上面下载,下载链接在文章开头处的前言里面。如果读者对本文有什么疑问,可以在评论里面提出,我如果看见了会及时回答。另外本文如有欠缺或者瑕疵之类的,也请读者不吝赐教。希望我们大家一起学习、一起进步。如果对本文有疑问的话也可以通过微博私信的方式与笔者联系提出,微博地址:http://weibo.com/junhuster
Jcompress: 一款基于huffman编码和最小堆的压缩、解压缩小程序
标签:insert const erro 提取 统计 改变 联系 处理器 个人
原文地址:http://www.cnblogs.com/junhuster/p/junhuster.html