标签:style blog tar color http get
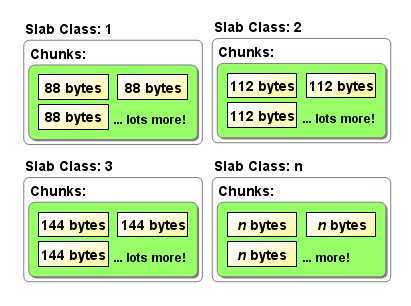
Memcache进程启动,在内存开辟了连续的区域。咱们用上面的图形来举例,这段连续的区域就好像上面的slab1+slab2+slab3+……+slab(n).分配区域相同的构成了slab(分片组)。Slab下面可不直接就是存储区域片(就是图中的chunks)了。而是page,如果一个新的缓存数据要被存放,memcached首先选择一个合适的slab,然后查看该slab是否还有空闲的chunk,如果有则直接存放进去;如果没有则要进行申请。
slab申请内存时以page为单位,所以在放入第一个数据,无论大小为多少,都会有1M大小的page被分配给该slab。申请到page后,slab会将这个page的内存按chunk的大小进行切分,这样就变成了一个chunk的数组,在从这个chunk数组中选择一个用于存储数据。在Page中才是一个个小存储单元——chunks,一个page默认1mb,那么可以放多少个88字节单位的chunks呢?1024*1024/88约等于11915个。如果放入记录是一个100字节的数据,那么在88字节的chunks和112字节的chunks中如何调配呢。答案当然是紧着大的用,不可能将请求过来的数据再做个分解、分离存储、合并读取吧。这样也就带来了一个小问题,还是有空间浪费掉了。112-100=12字节,这12字节就浪费了。
Memcache借助了操作系统的libevent工具做高效的读写。libevent是个程序库,它将Linux的epoll、BSD类操作系统的kqueue等事件处理功能封装成统一的接口。即使对服务器的连接数增加,也能发挥高性能。memcached使用这个libevent库,因此能在Linux、BSD、Solaris等操作系统上发挥其高性能。Memcache号称可以接受任意数量的连接请求。事实真的是这样吗?
**一般来说一个memcahced进程会预先将自己划分为若干个slab,slab得数量是有限得,几个,十几个,或者几十个,这个跟进程配置得内存有关。
**一个slab会有多个page,预先分配1m,不是说只能使用1m,当这 1m的数据满了之后,会重新分配一个page给这个slab。
推荐:对slab,page,chunk解释的较详细:http://tank.blogs.tkiicpp.com/2010/12/14/memcache%E5%86%85%E5%AD%98%E5%88%86%E9%85%8D%E7%AD%96%E7%95%A5/
存储过程分析
假设我们现在往memcache中存储一个缓存记录,首先在使用memcache客户端程序的时候要制定一个初始化的服务机器路由表,比如PHP的客户端程序
$mc = new Memcache();
$mc->addserver(‘192.168.1.110‘,11211);
$mc->addserver(‘192.168.1.120‘,11211);
$mc->addserver(‘192.168.1.130‘,11211);
那么在做存储的时候memcache客户端程序会hash出一个码,之后再根据路由表去将请求转发给memcache服务端,也就是说memcache的客户端程序相当于做了一个类似负载均衡的功能。
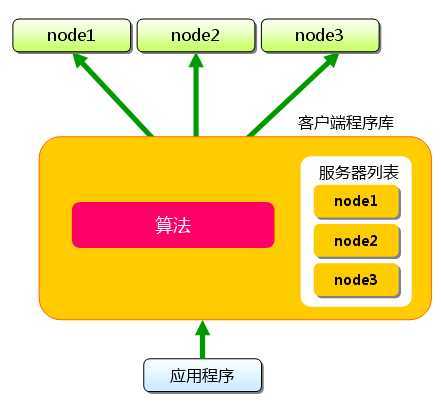
而memcache在server上面的进程仅仅负责监听服务和接受请求、存储数据的作用。分发不归他管。所以这么看的话,散列到每台memcache服务机器,让每台机器分布存储得均匀是客户端代码实现的一个难点。这个时侯Hash散列算法就显得格外重要了吧。
读取过程分析
理解了memcache的存储就不难理解memcache的读取缓存的过程了。在读取的时候也是根据key算出一个hash,之后在算出指定的路由物理机位置,再将请求分发到服务机上。
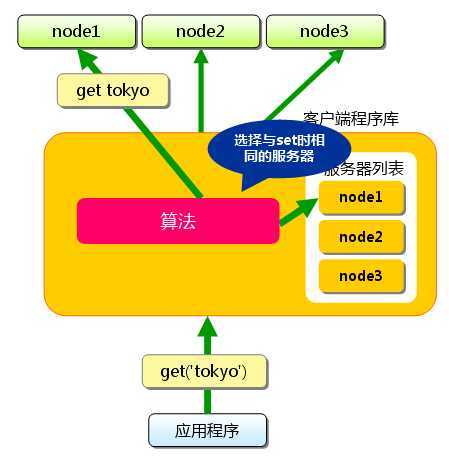
memcache分布式读写的存储方式有利有弊。如果node2宕机了,那么node2的缓存数据就没了,那么还得先从数据库load出来数据,重新根据路由表(此时只有node1和node3),重新请求到一个缓存物理机上,在写到重定向的缓存机器中。灾难恢复已经实现得较为完备。弊端就是维护这么一个高可用缓存,成本有点儿大了。为了存储更多的数据,这样做是否利大于弊,还是得看具体的应用场景再定。
参考博文:
http://www.myexception.cn/program/1586069.html
http://blog.sina.com.cn/s/blog_75a2f94f0101dpag.html
标签:style blog tar color http get
原文地址:http://www.cnblogs.com/leezhxing/p/3716197.html