标签:类别 解释 分享 不同 img 大型 logs 独立 采集
一些定义/理解:
这一块的东西还是建议看书,书上解释得很清楚,单独提出来可能很难说明白是啥。
知识谱图:力求将关于世界的知识用形式化的语言进行硬编码,计算机可以通过这些形式化语言自动地使用逻辑推理规则来理解声明。
然而依靠硬编码的知识体系面对种种困难,因此人们希望AI系统有自己获取知识的能力。
机器学习:AI系统自己获取知识的能力,即从原始数据中提取模式的能力。
简单的机器学习算法的性能在很大程度上依赖人们给定数据的表示,这些表示给的不准确的话,学习效果就不好。
表示学习(representation learning):使用机器学习来发现表示本身。
学习到的表示往往比手动设计的表示更好,并且只需要最少的人工干预
变化因素(factor of variation):当设计特征或学习特征的算法时,我们的目标通常是分离出能解释观察数据的变化因素。
深度学习让计算机通过较简单概念构建复杂的概念。 (对照书上的实例可以理解比较清楚)
学习数据的正确表示的想法是解释深度学习的一个观点。另一个观点是深度允许计算机学习一个多步骤的计算机程序,表示的每一层可以被认为是并行执行另一组指令后计算机的存储器状态。 第二个观点没理解。
分布式表示(distributed representation) 本书核心 连接机制中的关键概念。这一想法是每个的输入应该由许多特征表示的,并且每个特征应参与许多可能输入的表示。
这个概念还是举个例子比较清楚:假设我们有一个能够识别红色、绿色、或蓝色的汽车、卡车和鸟类的视觉系统。 表示这些输入的其中一个方法是将九个可能的组合:红卡车,红汽车,红鸟,绿卡车等等使用单独的神经元或隐藏单元激活。这需要九个不同的神经元,并且每个神经必须独立地学习颜色和对象身份的概念。改善这种情况的方法之一是使用分布式表示,即用三个神经元描述颜色,三个神经元描述对象身份。这仅仅需要 6 个神经元而不是 9 个,并且描述红色的神经元能够从汽车、卡车和鸟类的图像中学习红色,而不仅仅是从一个特定类别的图像中学习。
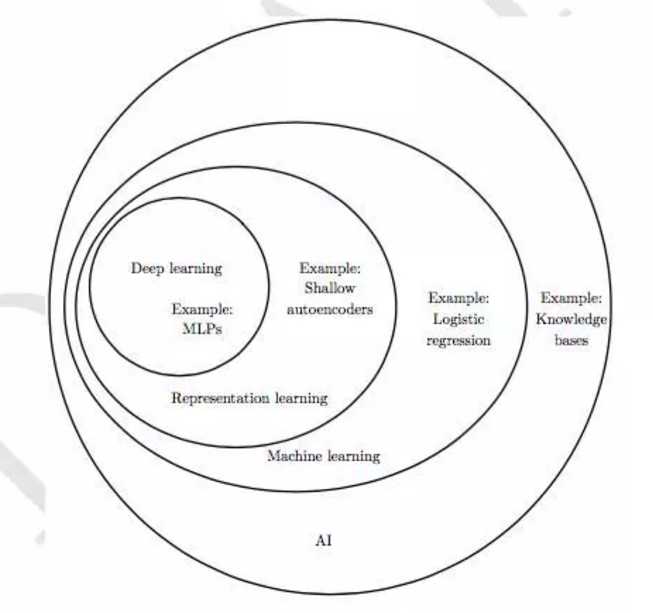
图中表示AI、机器学习、表示学习、深度学习的关系
深度学习的两次浪潮:
控制论(cybernetics)????
连接机制(connectionism)
深度学习成功的理由:
1、 可以使用的数据量不断增大。
并且因为大数据时代的到来,数据更容易被采集。
2、模型的规模不断增大。
连接机制的主要见解之一是,当动物的许多神经元一起工作时会变得聪明。
神经网络的规模小的话不能解决高难度问题是肯定的,比一个水蛭的神经元还少的神经网络不能解决复杂的人工智能是不足为奇的。
规模包括神经节点数量的规模和每个神经节点连接的规模。
截至2016年,一个粗略的经验法则是,监督深度学习算法一般在每类给定约5000标注样本情况下可以实现可接受的性能,当至少有1000万标注样本的数据集用于训练时将达到或超过人类表现。
一些东西:
整流线性单元(rectified linear unit)
ImageNet大型视觉识别挑战(ILSVRC)
雪貂大脑的故事
标签:类别 解释 分享 不同 img 大型 logs 独立 采集
原文地址:http://www.cnblogs.com/zkw159/p/6305836.html