标签:read 避免 ado store 状态 edit pil command body
写在前面:本来想着把表的创建,删除,以及修改一篇搞定的。结果看了一下,东西还是蛮多的,而且也是很多经常使用的操作。所以,就暂且分开处理吧。
特别提醒:在日常不管是创建库、表还是修改字段,删除等操作,建议都加上 [IF NOT EXISTS] | [IF EXISTS] 选项;虽然是可选项,但是还是小心为上,万一你在操作时没有加库名,又操作错了,那你哭都找不到地方。
This chapter explains how to create a table and how to insert data into it. The conventions of creating a table in HIVE is quite similar to creating a table using SQL.
Create Table is a statement used to create a table in Hive. The syntax and example are as follows:
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [ROW FORMAT row_format] [STORED AS file_format]
译注:hive中stored的 file_format目前有:(参考http://blog.csdn.net/yfkiss/article/details/7787742)
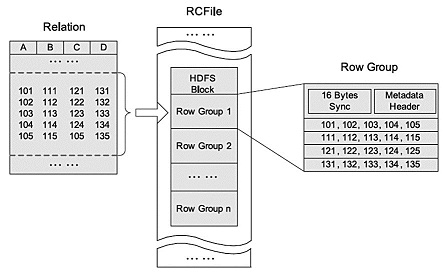
Let us assume you need to create a table named employee using CREATE TABLE statement. The following table lists the fields and their data types in employee table:
| Sr.No | Field Name | Data Type |
|---|---|---|
| 1 | Eid | int |
| 2 | Name | String |
| 3 | Salary | Float |
| 4 | Designation | string |
The following data is a Comment, Row formatted fields such as Field terminator, Lines terminator, and Stored File type.
COMMENT ‘Employee details’ FIELDS TERMINATED BY ‘\t’ LINES TERMINATED BY ‘\n’ STORED IN TEXT FILE
The following query creates a table named employee using the above data.
hive> CREATE TABLE IF NOT EXISTS employee ( eid int, name String, salary String, destination String) COMMENT ‘Employee details’ ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’ LINES TERMINATED BY ‘\n’ STORED AS TEXTFILE;
译注:目前我使用的脚本样例如下:按照dt 字段进行分区,这个后续有一篇专门讲到了分区,你可以先去看看英文版https://www.tutorialspoint.com/hive/hive_partitioning.htm
CREATE TABLE IF NOT EXISTS `snapshot_task_sub` ( `task_sub_id` INT COMMENT ‘任务扩展子表ID‘, `task_id` INT COMMENT ‘任务ID‘, `car_series` INT COMMENT ‘车系ID‘, `series_name` STRING COMMENT ‘车系名称‘, `purchase_amount` INT COMMENT ‘购买数量‘, `price` DOUBLE COMMENT ‘最新投放单价‘, `published_price` DOUBLE COMMENT ‘刊例价‘, `state` TINYINT COMMENT ‘状态 0正常 2删除‘, `create_time` STRING COMMENT ‘创建时间‘, `edit_time` STRING COMMENT ‘修改时间‘, `snap_time` STRING COMMENT ‘快照时间‘ ) COMMENT ‘任务子表天快照表‘ PARTITIONED BY (`dt` STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t‘ STORED AS TEXTFILE ;
If you add the option IF NOT EXISTS, Hive ignores the statement in case the table already exists.
On successful creation of table, you get to see the following response:
OK Time taken: 5.905 seconds hive>
The JDBC program to create a table is given example.
import java.sql.SQLException; import java.sql.Connection; import java.sql.ResultSet; import java.sql.Statement; import java.sql.DriverManager; public class HiveCreateTable { private static String driverName = "org.apache.hadoop.hive.jdbc.HiveDriver"; public static void main(String[] args) throws SQLException { // Register driver and create driver instance Class.forName(driverName); // get connection Connection con = DriverManager.getConnection("jdbc:hive://localhost:10000/userdb", "", ""); // create statement Statement stmt = con.createStatement(); // execute statement stmt.executeQuery("CREATE TABLE IF NOT EXISTS " +" employee ( eid int, name String, " +" salary String, destignation String)" +" COMMENT ‘Employee details’" +" ROW FORMAT DELIMITED" +" FIELDS TERMINATED BY ‘\t’" +" LINES TERMINATED BY ‘\n’" +" STORED AS TEXTFILE;"); System.out.println(“ Table employee created.”); con.close(); } }
Save the program in a file named HiveCreateDb.java. The following commands are used to compile and execute this program.
$ javac HiveCreateDb.java $ java HiveCreateDb
Table employee created.
Generally, after creating a table in SQL, we can insert data using the Insert statement. But in Hive, we can insert data using the LOAD DATA statement.
While inserting data into Hive, it is better to use LOAD DATA to store bulk records. There are two ways to load data: one is from local file system and second is from Hadoop file system.
通常,在SQL中创建表之后,我们可以使用Insert语句插入数据。 但在Hive中,我们可以使用LOAD DATA语句插入数据。
在将数据插入Hive时,最好使用LOAD DATA来存储批量记录。 有两种方式加载数据:一种来自本地文件系统,另一种来自Hadoop文件系统。
The syntax for load data is as follows:
LOAD DATA [LOCAL] INPATH ‘filepath‘ [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
We will insert the following data into the table. It is a text file named sample.txt in /home/user directory.
1201 Gopal 45000 Technical manager 1202 Manisha 45000 Proof reader 1203 Masthanvali 40000 Technical writer 1204 Kiran 40000 Hr Admin 1205 Kranthi 30000 Op Admin
The following query loads the given text into the table.
hive> LOAD DATA LOCAL INPATH ‘/home/user/sample.txt‘ OVERWRITE INTO TABLE employee;
On successful download, you get to see the following response:
OK Time taken: 15.905 seconds hive>
Given below is the JDBC program to load given data into the table.
import java.sql.SQLException; import java.sql.Connection; import java.sql.ResultSet; import java.sql.Statement; import java.sql.DriverManager; public class HiveLoadData { private static String driverName = "org.apache.hadoop.hive.jdbc.HiveDriver"; public static void main(String[] args) throws SQLException { // Register driver and create driver instance Class.forName(driverName); // get connection Connection con = DriverManager.getConnection("jdbc:hive://localhost:10000/userdb", "", ""); // create statement Statement stmt = con.createStatement(); // execute statement stmt.executeQuery("LOAD DATA LOCAL INPATH ‘/home/user/sample.txt‘" + "OVERWRITE INTO TABLE employee;"); System.out.println("Load Data into employee successful"); con.close(); } }
Save the program in a file named HiveLoadData.java. Use the following commands to compile and execute this program.
$ javac HiveLoadData.java
$ java HiveLoadData
Load Data into employee successful
-------------
英文文章地址:https://www.tutorialspoint.com/hive/hive_create_table.htm
Hive - Create Table&Drop Table & ALTER Table(上)
标签:read 避免 ado store 状态 edit pil command body
原文地址:http://www.cnblogs.com/hager/p/6323279.html