标签:ima text logs 技术分享 ext twitter 方向 记忆力 数据
从1月13号信誓旦旦的付款了第一位的纳米学位到今天已经一周多的时间了,可以发现自己在完成任务的时候更多的在乎的是不是时间上达到了要求,而没有过多的关注于实质的内容。有时候看到课程的小节数很多就有一种畏惧感和烦躁的心情,逐渐的说服自己取放弃,这其实是一种观念上的偏差。可能是因为自己的性格比较急躁,很多事情都想要迅速的完成并且还能够保证质量,但是实际来说,只要方法得当,最后的成果总会和你投入的时间成正比,放平心态,一步一步慢慢来。
下面对第一课所学的内容做一个梳理和总结。
研究方法 数据可视化 集中趋势 可变性 归一化 正态分布 抽样分布 估计 假设检验 t检验

BBC测量记忆力的实验: 定义抽象概念,将一个抽象概念转化成为一个具有实际操作性,可测性的变量
样本与全体的不同,样本能够估计整体统计值,但是样本一定会带有一定的误差,需要进行相关的分析和处理,样本偏差,抽样分布的结果可以确定某一样本在整体中所占的位置,z值和t值来表示某一个特定值与平均值的差异

例子:安慰剂实验检测 单盲与双盲的实验不同
金色拱门理论:Mcdonald 开M的两个国家都没有参战,关性不代表因果关系
数据可视化:
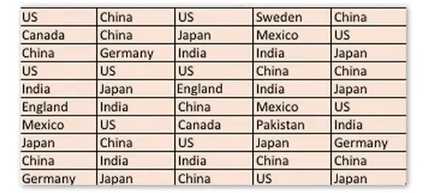
原始的数据集合 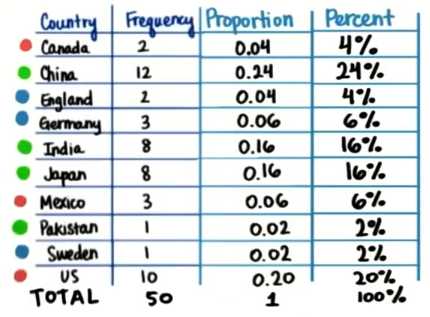
经过初步整理的数据集合
例子:对Udacity学生的来源进行统计分析,
组距,频率,相对频率,百分比,占比,数值型的数据or类别性的数据,正偏斜分布(频率低的值在X轴正方向)
3.集中趋势:
众数,中位数,平均值
4.差异值:
极差,偏差,平均偏差和,标准差,方差,4分之1值,样本标准差(贝塞尔校正)
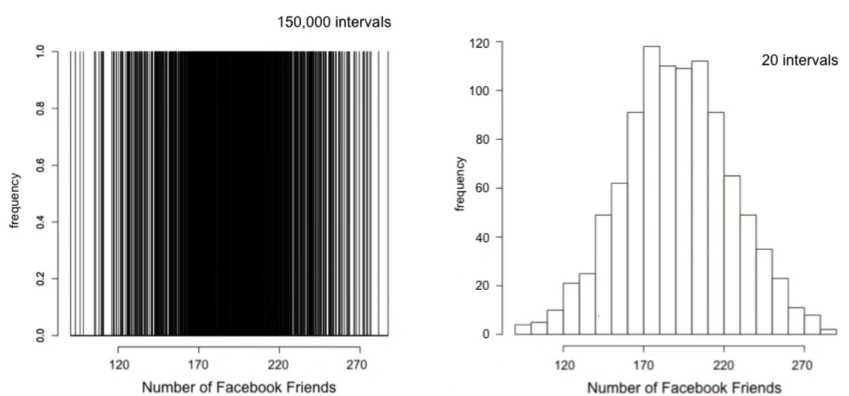
5.归一化:
利用相对频率引出概率密度函数正态分布的概念
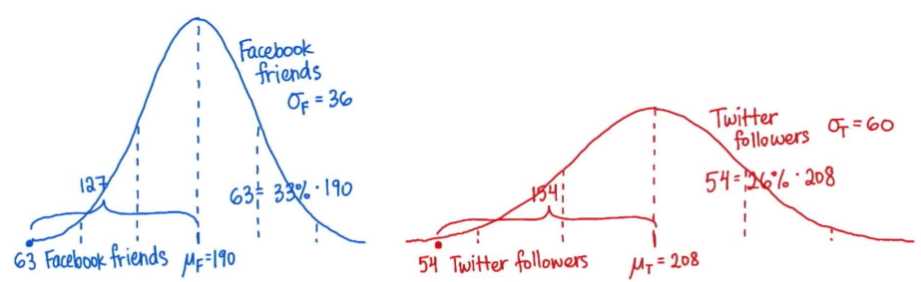
例子:Andy的Facebook katie的Twitter 归一化是为了比较不同参考体系下的两个个体 转换为z值进行相关比较
6.正态分布:
7.抽样分布:
例子:四面体骰子,投掷两次,
t分布 如何引出t分布分概念,是否能够将σ做为已知量带入计算,t分布根据自由度的不同进行区分,自由度越大的t分布越接近于正态分布
标签:ima text logs 技术分享 ext twitter 方向 记忆力 数据
原文地址:http://www.cnblogs.com/kong-xy/p/6336497.html