标签:des style blog http color os io strong
A technique for implementing read-copy update in a shared-memory computing system having two or more processors operatively coupled to a shared memory and to associated incoherent caches that cache copies of data stored in the memory. According to example embodiments disclosed herein, cacheline information for data that has been rendered obsolete due to a data update being performed by one of the processors is recorded. The recorded cacheline information is communicated to one or more of the other processors. The one or more other processors use the communicated cacheline information to flush the obsolete data from all incoherent caches that may be caching such data.
The present disclosure relates to computer systems and methods in which data resources are shared among data consumers while preserving data integrity and consistency relative to each consumer. More particularly, the disclosure concerns an implementation of a mutual exclusion mechanism known as "read-copy update" in a cache-incoherent shared-memory computing environment.
By way of background, read-copy update (also known as "RCU") is a mutual exclusion technique that permits shared data to be accessed for reading without the use of locks, writes to shared memory, memory barriers, atomic instructions, or other computationally expensive synchronization mechanisms, while still permitting the data to be updated (modify, delete, insert, etc.) concurrently. The technique is well suited to both uniprocessor and multiprocessor computing environments wherein the number of read operations (readers) accessing a shared data set is large in comparison to the number of update operations (updaters), and wherein the overhead cost of employing other mutual exclusion techniques (such as locks) for each read operation would be high. By way of example, a network routing table that is updated at most once every few minutes but searched many thousands of times per second is a case where read-side lock acquisition would be quite burdensome.
The read-copy update technique implements data updates in two phases. In the first (initial update) phase, the actual data update is carried out in a manner that temporarily preserves two views of the data being updated. One view is the old (pre-update) data state that is maintained for the benefit of read operations that may have been referencing the data concurrently with the update. The other view is the new (post-update) data state that is seen by operations that access the data following the update. In the second (deferred update) phase, the old data state is removed following a "grace period" that is long enough to ensure that the first group of read operations will no longer maintain references to the pre-update data. The second-phase update operation typically comprises freeing a stale data element to reclaim its memory. In certain RCU implementations, the second-phase update operation may comprise something else, such as changing an operational state according to the first-phase update.
FIGS. 1A-1D?illustrate the use of read-copy update to modify a data element B in a group of data elements A, B and C. The data elements A, B, and C are arranged in a singly-linked list that is traversed in acyclic fashion, with each element containing a pointer to a next element in the list (or a NULL pointer for the last element) in addition to storing some item of data. A global pointer (not shown) is assumed to point to data element A, the first member of the list. Persons skilled in the art will appreciate that the data elements A, B and C can be implemented using any of a variety of conventional programming constructs, including but not limited to, data structures defined by C-language "struct" variables. Moreover, the list itself is a type of data structure.
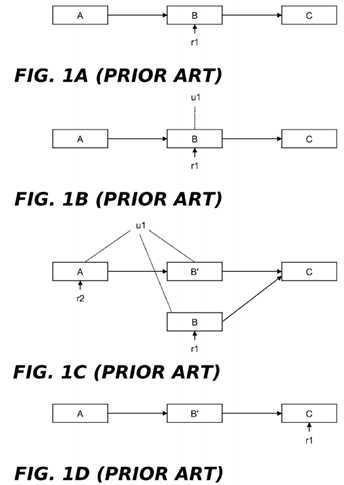
It is assumed that the data element list of?FIGS. 1A-1D?is traversed (without locking) by multiple readers and occasionally updated by updaters that delete, insert or modify data elements in the list. In?FIG. 1A, the data element B is being referenced by a reader r1, as shown by the vertical arrow below the data element. In?FIG. 1B, an updater u1?wishes to update the linked list by modifying data element B. Instead of simply updating this data element without regard to the fact that r1?is referencing it (which might crash r1), u1?preserves B while generating an updated version thereof (shown inFIG. 1C?as data element B′) and inserting it into the linked list. This is done by u1?acquiring an appropriate lock (to exclude other updaters), allocating new memory for B′, copying the contents of B to B′, modifying B′ as needed, updating the pointer from A to B so that it points to B′, and releasing the lock. In current versions of the Linux? kernel, pointer updates performed by updaters can be implemented using the rcu_assign_pointer( ) primitive. As an alternative to locking during the update operation, other techniques such as non-blocking synchronization or a designated update thread could be used to serialize data updates. All subsequent (post update) readers that traverse the linked list, such as the reader r2, will see the effect of the update operation by encountering B′ as they dereference B‘s pointer. On the other hand, the old reader r1?will be unaffected because the original version of B and its pointer to C are retained. Although r1?will now be reading stale data, there are many cases where this can be tolerated, such as when data elements track the state of components external to the computer system (e.g., network connectivity) and must tolerate old data because of communication delays. In current versions of the Linux? kernel, pointer dereferences performed by readers can be implemented using the rcu_dereference( ) primitive.
At some subsequent time following the update, r1?will have continued its traversal of the linked list and moved its reference off of B. In addition, there will be a time at which no other reader process is entitled to access B. It is at this point, representing an expiration of the grace period referred to above, that u1?can free B, as shown in?FIG. 1D.
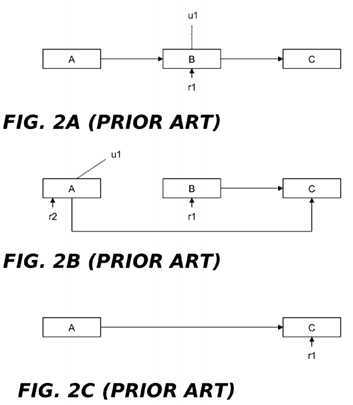
FIGS. 2A-2C?illustrate the use of read-copy update to delete a data element B in a singly-linked list of data elements A, B and C. As shown in?FIG. 2A, a reader r1?is assumed be currently referencing B and an updater u1?wishes to delete B. As shown in?FIG. 2B, the updater u1?updates the pointer from A to B so that A now points to C. In this way, r1?is not disturbed but a subsequent reader r2?sees the effect of the deletion. As shown in?FIG. 2C, r1?will subsequently move its reference off of B, allowing B to be freed following the expiration of a grace period.
In the context of the read-copy update mechanism, a grace period represents the point at which all running tasks (e.g., processes, threads or other work) having access to a data element guarded by read-copy update have passed through a "quiescent state" in which they can no longer maintain references to the data element, assert locks thereon, or make any assumptions about data element state. By convention, for operating system kernel code paths, a context switch, an idle loop, and user mode execution all represent quiescent states for any given CPU running non-preemptible code (as can other operations that will not be listed here). The reason for this is that a non-preemptible kernel will always complete a particular operation (e.g., servicing a system call while running in process context) prior to a context switch.
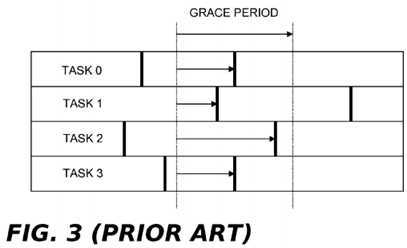
In?FIG. 3, four tasks 0, 1, 2, and 3 running on four separate CPUs are shown to pass periodically through quiescent states (represented by the double vertical bars). The grace period (shown by the dotted vertical lines) encompasses the time frame in which all four tasks that began before the start of the grace period have passed through one quiescent state. If the four tasks 0, 1, 2, and 3 were reader tasks traversing the linked lists of?FIGS. 1A-1D?or?FIGS. 2A-2C, none of these tasks having reference to the old data element B prior to the grace period could maintain a reference thereto following the grace period. All post grace period searches conducted by these tasks would bypass B by following the updated pointers created by the updater.
Grace periods may be synchronous or asynchronous. According to the synchronous technique (e.g., using the synchronize_rcu( ) primitive), an updater performs the first phase update operation, blocks (waits) until the grace period has completed, and then implements the second phase update operation, such as by removing stale data. According to the asynchronous technique (e.g., using the call_rcu( ) primitive), an updater performs the first phase update operation, then specifies the second phase update operation as a callback, and thereafter resumes other processing with the knowledge that the callback will eventually be processed at the end of a grace period. Advantageously, callbacks requested by one or more updaters can be batched (e.g., on callback lists) and processed as a group at the end of the grace period. This allows grace period overhead to be amortized over plural deferred update operations.
Multiprocessor RCU implementations developed to date assume that the underlying hardware system offers cache-coherence and one of a range of memory-ordering models (i.e., from strongly ordered to weakly ordered). However, there have been recent concerns, particularly among vendors offering strongly ordered systems, that cache-incoherent systems will be required in order to continue progress according to Moore‘s Law. Whether or not these concerns have any basis in reality, shared-memory cache-incoherent systems are starting to appear. In some cases, all caches in the system are incoherent. In other cases, the system may have cache-coherent multi-processor "nodes" within a larger cache-incoherent system. In such systems, cache coherence is maintained with respect to a node‘s local memory but not with respect to the memory of other nodes. Although there has been some work extending RCU to shared-nothing systems (i.e., clusters), there has been very little work towards efficient RCU implementations in cache-incoherent shared-memory multiprocessor systems. One of the challenges facing RCU in a cache-incoherent shared-memory environment is the need to accommodate the reuse of memory blocks by updaters. Such reuse can occur, for example, when a memory block associated with stale data is reclaimed at the end of a grace period and then subsequently reused for storing new data. If the memory block is reused before the cachelines containing the stale data are removed from local processor caches, readers dereferencing pointers that should point to the new data may in fact retrieve the old stale data.
One prior-art approach for solving this problem, used in the Blackfin? system from Analog Devices, Inc., is to have the rcu_dereference( ) primitive flush all lines from the executing processor‘s cache. See Linux? v.2.6.39 source code—SSYNC( ) instruction at line 163 of _raw_smp_check_barrier_asm( ) function spanning lines 136-183 of /linux/arch/blackfin/mach-bf561/atomic.S, which is called from smp_check_barrier( ) function spanning lines 59-62 of /linux/arch/blackfin/include/asm/cache.h, which is called from read barrier depends( ) function at line 44 of /linux/arch/blackfin/include/asm/system.h, which is called from "rcu_dereference check( )" spanning lines 327-334 of linux/include/linux/rcupdate.h, which is implemented by rcu_deference( ) at line 519 of linux/include/linux/rcupdate.h. Unfortunately, this approach imposes great overhead on the RCU readers that invoke this primitive, defeating much of the purpose of using RCU in the first place. These developments therefore motivate an RCU implementation that can run efficiently on cache-incoherent systems.
A method, system and computer program product are provided for implementing read-copy update in a shared-memory computing system having two or more processors operatively coupled to a shared memory and to associated incoherent caches that cache copies of data stored in the memory. According to an example embodiment disclosed herein, cacheline information for data that has been rendered obsolete due to a data update being performed by one of the processors is recorded. The recorded cacheline information is communicated to one or more of the other processors. The one or more other processors use the communicated cacheline information to flush the obsolete data from all incoherent caches that may be caching such data.
According to a further embodiment, the recording operation may comprise an updater determining an extent of the obsolete data in the memory during an update operation to identify cachelines that hold such data, and storing the cacheline information either during or after the update operation in a local cache record data structure associated with a processor that is performing the recording operation. According to another embodiment, the local cache record data structure may use one of a non-compression storage technique or a compression storage technique to store the cacheline information. According to another embodiment, the communicate operation may include merging the cacheline information from the local cache record data structure into a global cache record data structure that stores cacheline information merged from two or more local cache record data structures. According to another embodiment, the cacheline information from the local cache record data structure may be merged into the global cache record data structure through a hierarchy of one or more intermediate cache record data structures. According to another embodiment, the flush operation may comprise using the cacheline information stored in the global cache record data structure to identify and flush the obsolete data from all incoherent caches. According to another embodiment, the communicate and flush operations may be respectively performed during first and second grace period phases by each of processor, or by one or more proxy processors that perform such operations on behalf of other processors.
RCU is a way of deferring execution until potentially conflicting actions have completed. As such, RCU‘s two fundamental guarantees are as follows:
1. Any RCU read-side critical section that begins before a given grace period must end before that grace period ends; and
2. Any dereference of an RCU-protected pointer is guaranteed to see the effects of all initialization carried out before that pointer was published (e.g., via rcu_assign_pointer( )).
It is desirable that an RCU implementation for cache-incoherent systems preserve the above guarantees. In addition, RCU read-side primitives will preferably have low overhead and support multiprocessor scalability. The present disclosure proposes a technique that allows RCU to be used in a cache-incoherent system while supporting the foregoing guarantees and desiderata. It does this by having updaters account for cached data that is obsoleted by updates so that such data can be flushed from each incoherent cache that is accessible to readers prior to ending a grace period. According to example embodiments described in more detail below, the foregoing may be achieved by the following operations:
1. Record—An updater (e.g., via the rcu_assign_pointer( ) primitive) records the extent of a newly obsoleted structure that results from a pointer reassignment stemming from the update. Normally, this can be done by considering the old pointer value and the size of the element that it references (for example, using the sizeof( ) operator in the C programming language), but in other cases may require additional actions;
2. Communicate—At the time of the next interaction with RCU‘s grace-period machinery, the aggregate address ranges of all of data structures obsoleted by one or more recent update operations (e.g., via one or more invocations of the rcu_assign_pointer( ) primitive) are communicated to the rest of the cache-incoherent shared-memory system; and
3. Flush—A given invocation of synchronous grace period detection (e.g., via the synchronize_rcu( ) primitive) or asynchronous grace period detection (e.g., via the call_rcu( ) primitive) will not return until the aggregate address ranges of data structures obsoleted by all prior updater invocations have been flushed from the incoherent caches of all processors in the cache-incoherent shared-memory system.
There are a number of options for implementing the foregoing operations. Each will be described in more detail below in the "Example Embodiments" section.
Turning now to the figures, wherein like reference numerals represent like elements in all of the several views,?FIG. 4illustrates an example computing environment in which the grace period processing technique described herein may be implemented. In?FIG. 4, a computing system?2?includes two or more processors?4?1,?4?2?. . .?4?n, a system bus?6, and a program (main) memory?8. There are also cache memories?10?1,?10?2?. . .?10?n?and cache controllers?12?1,?12?2?. . .?12?nrespectively associated with the processors?4?1,?4?2?. . .?4?n. A conventional memory controller?14?is associated with the memory?8. As shown, the memory controller?14?may reside separately from processors?4?2?. . .?4?n?(e.g., as part of a chipset). Alternatively, the memory controller?14?could be provided by plural memory controller instances respectively integrated with the processors?4?2?. . .?4?n?(as is known in the art).
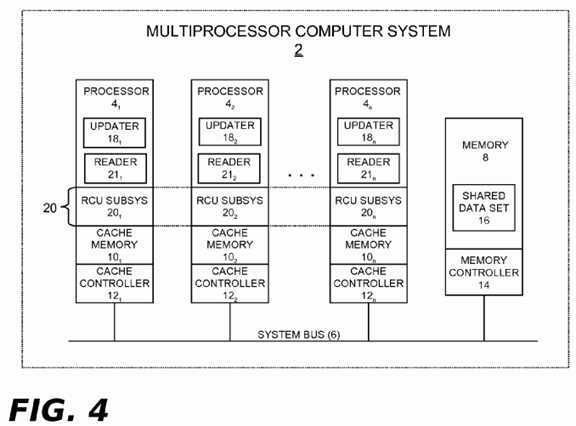
The computing system?2?may represent any type of computing apparatus, including but not limited to, general purpose computers, special purpose computers, portable computing devices, communication and/or media player devices, set-top devices, embedded systems, to name but a few. The processors?4?1,?4?2?. . .?4?n?may each be a single-core CPU device. Alternatively, the processors?4?1,?4?2?. . .?4?n?could represent individual cores within a multi-core CPU device. The processors?4?1,?4?2?. . .?4?n?could also be situated within a node of a distributed multi-node system (e.g., as part of a NUMA system, a cluster, a cloud, etc.).
In some embodiments, the cache controllers?12?1,?12?2?. . .?12?n?will be cache-incoherent relative to the memory?8. As such, they will not support hardware-implemented memory consistency between the memory?8?and the cache‘s?10?1,?10?2?. . .?10n. In other cases, such as in multi-node NUMA embodiments, the memory?8?may be a local node memory and the cache controllers?12?1,?12?2?. . .?12?n?may support cache-coherency relative to that memory. As shown in the alternative computing system?2A of?FIG. 4A, a separate directory cache?17?within a node may be used to cache data stored in the local memory of other nodes, but will do so on a cache-incoherent basis.
Each CPU device embodied by any given processor?4?of?FIGS. 4 and 4A?is operable to execute program instruction logic under the control of a software program stored in the memory?8?(or elsewhere). The memory?8?may comprise any type of tangible storage medium capable of storing data in computer readable form, including but not limited to, any of various types of random access memory (RAM), various flavors of programmable read-only memory (PROM) (such as flash memory), and other types of primary storage.
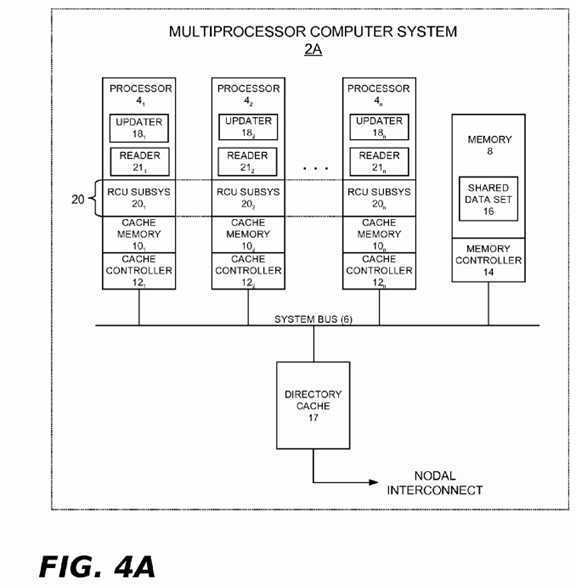
An update operation (updater)?18?may periodically execute within a process, thread, or other execution context (hereinafter "task") on any processor?4?of?FIG. 4?or?4A. Each updater?18?runs from program instructions stored in the memory?8?(or elsewhere) in order to periodically perform updates on a set of shared data?16?that may be stored in the shared memory?8(or elsewhere). Reference numerals?18?1,?18?2?. . .?18?n?illustrate individual data updaters that may periodically execute on the several processors?4?1,?4?2?. . .?4?n. As described in the "Background" section above, the updates performed by an RCU updater can include modifying elements of a linked list, inserting new elements into the list, deleting elements from the list, and other types of operations. To facilitate such updates, the processors?4?of?FIGS. 4 and 4A?are programmed from instructions stored in the memory?8?(or elsewhere) to implement a read-copy update (RCU) subsystem?20?as part of their processor functions. Reference numbers?20?1,?20?2?. . .?20?n?represent individual RCU instances that may periodically execute on the several processors?4?1,?4?2?. . .?4?n. Any given processor?4?in?FIGS. 4 and 4A?may also periodically execute a read operation (reader)?21. Each reader?21?runs from program instructions stored in the memory?8?(or elsewhere) in order to periodically perform read operations on the set of shared data?16?stored in the shared memory?8?(or elsewhere). Reference numerals?21?1,?21?2?. . .?21?n?illustrate individual reader instances that may periodically execute on the several processors?4?1,?4?2?. . .?4?n. Such read operations will typically be performed far more often than updates, this being one of the premises underlying the use of read-copy update. Moreover, it is possible for several of the readers?21?to maintain simultaneous references to one of the shared data elements?16?while an updater?18?updates the same data element. The updaters?18, the RCU subsystem?20, and the readers?21?may run either in operating system code paths or in user application code paths (e.g., in a multi-threaded user application).
During run time, an updater?18?will occasionally perform an update to one of the shared data elements?16?(e.g., using the rcu_assign_pointer( ) primitive). In accordance the philosophy of RCU, a first-phase update is performed in a manner that temporarily preserves a pre-update view of the shared data element for the benefit of readers?21?that may be concurrently referencing the shared data element during the update operation. Following the first-phase update, the updater?18?may register a callback with the RCU subsystem?20?for the deferred destruction of the pre-update view following a grace period (second-phase update). As described in the "Background" section above, this is known as an asynchronous grace period. Alternatively, an updater?18?may perform an update, request a synchronous grace period, and block until the synchronous grace period has elapsed.
The RCU subsystem?20?may be designed to handle asynchronous grace periods, synchronous grace periods, or both. Grace period processing operations may be performed by periodically running the RCU subsystem?20?on each of the several processors?4?1,?4?2?. . .?4?n. Example components of the RCU subsystem?20?are shown in?FIG. 5. These components include an RCU reader API (Application Programming Interface)?22, an RCU updater API?24, a set of grace period detection and callback processing functions?26, and a set of RCU subsystem data structures?28.
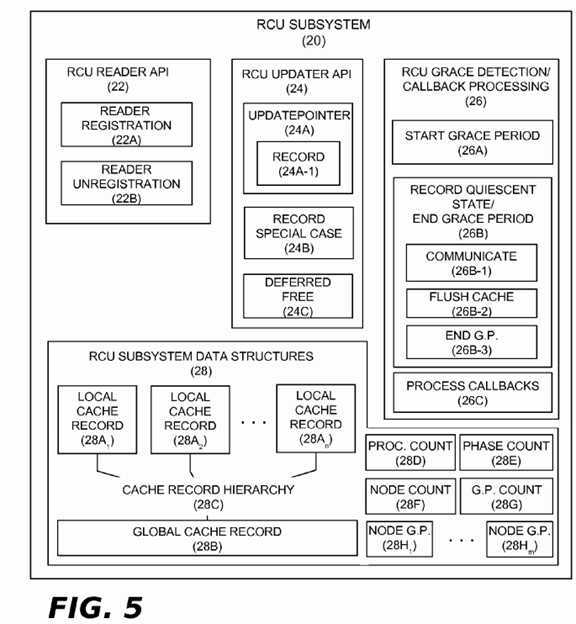
The RCU reader API?22?is conventional in nature and may include a standard reader registration component?22A and a standard reader unregistration component?22B. The reader registration component?22A is called by readers?21?each time they enter an RCU read-side critical section. In an example embodiment, a function name such as "rcu_read_lock( )" may be used when coding the RCU reader registration component?42A in software. This function performs an action (such as incrementing a counter) that indicates to the RCU subsystem?20?that the reader is in an RCU read-side critical section. The reader unregistration component?22B is called by readers?21?each time they leave an RCU read-side critical section. In an example embodiment, a function name such as "rcu_read_unlock( )" may be used when coding the RCU reader unregistration component?42B in software. This function performs an action (such as decrementing a counter) that indicates to the RCU subsystem?20?that the reader has left its RCU read-side critical section.
The RCU updater API?24?includes a pointer update component?24A, a record special case component?24B, and a deferred free component?24C. The update pointer component?24A may be used by updaters?18?at the end of a first-phase RCU update operation (e.g., data structure modification, deletion, and insertion, etc.) to enable new readers to reference the updated data (e.g., using the rcu_dereference pointer( ) primitive). A function name such as "rcu_assign_pointer( )" may be used when coding the pointer update component?24A in software insofar as this component includes the same pointer update logic found in the conventional RCU rcu_assign_pointer( ) primitive. In addition, however, the update pointer component?24A includes a record sub-component?24A-1?whose purpose is to perform the record operation mentioned in the "Introduction" section above in which the extent of a newly obsoleted data structure is recorded. As part of the record operation, the cacheline(s) used to store the obsoleted data structure (cacheline information) must be determined. In the simple case, the record sub-component?24A-1?may ascertain this information using the old pointer being updated and the size of the structure that it references (e.g. using the sizeof( ) C language operator. However, there are a number of complications that can arise:
1. The obsoleted structure might have variable length;
2. The obsoleted structure might be a linked list;
3. The obsoleted structure might be a multilinked graph;
4. the obsoleted structure might be only a portion of a larger linked list or graph.
The first case can be easily handled by the record sub-component?24A-1, which may be implemented as part of an updater‘s update operation. The second and third cases can be handled automatically in languages providing reflection. The last case may require either programmer assistance or a garbage collector that scans a heap region of the memory?8?for orphaned data objects. In the absence of a garbage collector, the programmer would usually be required to traverse the structure in order to free the individual data elements. Therefore, one solution is to require the programmer to traverse the data structure to be freed during a data update and before starting a grace period, and invoking a new API (the record special case component?24B) following the update to record which structures require cache flushing. Example operations of both the record sub-component?24A-1?and the record special case component?24B are described in more detail below.
The deferred free component?24C may be implemented as a suite of conventional RCU primitives that allow an updater to use either asynchronous or synchronous grace periods to facilitate the deferred freeing of memory holding stale data. For asynchronous grace periods, the call_rcu( ), call_rcu_bh( ) and call_rcu_sched( ) primitives represent example functions that may be provided by the deferred free component?24C. For synchronous grace periods, the synchronize_rcu( ), synchronize_rcu_bh( ) and synchronize_rcu_sched( ) primitives represents additional example functions that may be used.
The RCU grace period detection/callback processing functions?26?include several components that support the operations described herein, including a start grace period component?26A and a record quiescent state/end grace period component26B. If asynchronous grace periods are supported, a process callbacks component?26C may also be provided. As its name implies, the start grace period component?26A is used to begin new grace periods. If asynchronous grace periods are supported, the presence of a pending callback, or some threshold number of pending callbacks, or one or more pending callbacks plus some other condition (e.g., low memory), etc., could trigger a new grace period. If synchronous grace periods are supported, an explicit request by an updater?18?could trigger a new grace period. When a new grace period starts, the start grace period component?26A may advance a grace period counter and perform other initialization actions that signify to all of the processors?4?1,?4?2?. . .?4?n?that a new grace period has started. As will be described in more detail below, the start grace period component?26A may also be used to initialize data structures and variables used for the communicate operation mentioned in the "Introduction" section above.
As its name implies, the record quiescent state/end grace period component?26B is used to track processor quiescent states and end a grace period when it is appropriate to do so. As will be described in more detail below, the record quiescent state/end grace period component?26B may also be used to implement the communicate and flush operations mentioned in the "Introduction" section above. The record quiescent state/end grace period component?26B may thus include three sub-components, namely, a communicate sub-component?26B-1, a flush cache sub-component?26B-2, and an end grace period component?26B-3. Example operations of these sub-components will be described in more detail below.
The process callbacks component?26C is conventional in nature and will not be described further herein. Its purpose is to invoke callbacks as they become ready for processing at the end of a grace period. As is known, such callbacks may be accumulated on callback lists that are each associated with a particular grace period. Callbacks that are ripe for processing because their associated grace period has ended are invoked by the process callbacks component?26C. If desired, such processing may be performed in a separate context from the remainder of the RCU subsystem?20, such as in bottom half context (e.g. softirq context) or in the context of a separate kernel thread (e.g., kthread).
The RCU subsystem data structures?28?may include a set of local cache record data structures?28A1,?28A2?. . .?28An. For operating system kernel implementations of the RCU subsystem?20, the local cache record data structures?28A1,?28A2?. . .28An?may be implemented as per-processor data structures, or alternatively as per-node data structures in systems comprising multi-processor nodes. Simple numeric-based assignment relationships between the processors?4?1,?4?2?. . .?4?nand the local cache record data structures?28A1,?28A2?. . .?28An?could also be used, such as two processors per data structure, three processors per data structure, etc. In user-level implementations of the RCU subsystem?20, the local cache record data structures?28A1,?28A2?. . .?28An?could replicated on a per-thread basis or in any other suitable manner.
The local cache record data structures?28A1,?28A2?. . .?28An?are used during the record operation by updaters?18?executing on the various processors?4?1,?4?2?. . .?4?n. They store cacheline information specifying the cacheline(s) that contain data that has been rendered obsolete due to update operations performed by the updaters?18?1,?18?2?. . .?18?n. The manner in which the local cache record data structures?28A1,?28A2?. . .?28An?are implemented depends on the format in which the cacheline information is to be stored.
One approach is to implement each local cache record data structure?28A as a bitmap, with one bit for each cacheline in the system. The record operation may then be performed by setting appropriate bits in one of the local cache record data structures?28A. Subsequently, such bits would be cleared during the communicate operation. This approach is straightforward and has very predictable storage requirements that depend on the size of main memory, the number of bits in each cache line, and the number of local cache record data structures?28A1,?28A2?. . .?28An?that are provided. For example, assuming the local cache record data structures?28A1,?28A2?. . .?28An?are implemented on a per-processor basis, the total amount of memory consumed by the bitmaps is given by equation (1) below. In equation (1), B is the bitmap memory size, N is the number of processors, M is the number of bytes of available memory across the whole system, and C is the number of bytes in each cache line. It is also assumed that there are eight bits per byte:
B=NM/8C?bytes(1)
From equation (1), the amount of bit map memory required for an individual Bi?can be expressed as a fraction of the total amount of bit map memory B divided by the number of processors, as shown in equation (2):
B?i?=B/N=M/8C?bytes/processor(2)
It can be further shown that a point will be reached at which there are so many processors in the system that the total bit map memory consumes all of the available system memory. This is shown in equation (3), which rearranges equation (1) to set B=M and solve for N:
N=8C(B/M)=8C?processors(3)
This means that in a system with C=64-byte cache lines, all available memory would be devoted to the per-processor data structures?28A1,?28A2?. . .?28An?when there are 8*64=512 processors. This is unfortunate given that RCU is used in read-mostly situations, so that the number of bits set for any grace period will often be small. Moreover, if this is a user-level implementation of RCU, the number of threads T may need to be used instead of the number of processors N in the above equations, which will usually result in much greater memory consumption.
One way of reducing the memory required is to have one local cache record data structure?28A shared among a group of processors?4?1,?4?2?. . .?4?n. This approach may be advantageous for multi-node systems. By way of example, if there are four processors assigned to a single local cache record data structure?28A, the number of local cache record data structures?28A1,?28A2?. . .?28An?(and hence the memory required by their bit maps) would be reduced by a factor of four. However, a synchronization mechanism (such as a lock) may be needed to serialize each processor‘s access to the shared local cache record data structure?28A.
Another approach is to use compression techniques. Although there are any number of schemes for compactly representing sets (in this case, sets of cachelines to be flushed), all of them have the shortcoming of being variable length, and all of them have degenerate situations where the amount of memory consumed is far greater than that for the bitmaps. One way to solve this problem is to note that it is always correct (if inefficient) to flush more cachelines than necessary. This insight permits the use of lossy compression techniques on the list of cachelines. One example of a lossy compression technique is to simply pretend that the cachelines are larger than they really are. For example, if a system with 32-byte cache lines was treated as if it had 4096-byte cache lines, the size of the bitmaps decreases by more than two orders of magnitude. Of course, the downside of this approach is that the flush operation can end up flushing up to two orders of magnitude more cache lines than necessary. Another example of a lossy compression technique operates on run-length encoding. A run-length encoding in the present context would comprise a sequence of pairs of integers, where one of the pair is the beginning bit index for the corresponding "run," and the other is the number of bits in the run. For example, the bit string 0xff0000ff would be represented as {0,8}, {24,8}. Lossy compression can be applied to this run-length encoding, resulting in {0,32}. This compression will unnecessarily flush cache lines 8-23, but that will affect only performance, not correctness. Such compression allows a small fixed number of pairs of integers to be allocated, which in turn allows efficient insertion of new bits and efficient scanning. It will be appreciated that there are many other encodings and corresponding compression techniques that may also be used for the local cache record data structures?28A1,?28A2?. . .?28An.
To facilitate the communicate operation, the local cache record data structures?28A1,?28A2?. . .?28An?can be stored at agreed-upon memory addresses that are known by the various the processors?4?1,?4?2?. . .?4?n. During the communicate operation, each processor (or processor group) having an associated incoherent cache would consult all the local cache record data structures?28A1,?28A2?. . .?28An?stored at the agreed-upon memory addresses and then use the cacheline information therein to flush their own local cachelines during the flush operation. This of course requires that synchronization be maintained between a given processor (or processor group) updating its local cache record data structure?28A during the record phase and other processors (or processor groups) accessing the same data structure during the communicate phase. Such synchronization may entail a fair amount of overhead.
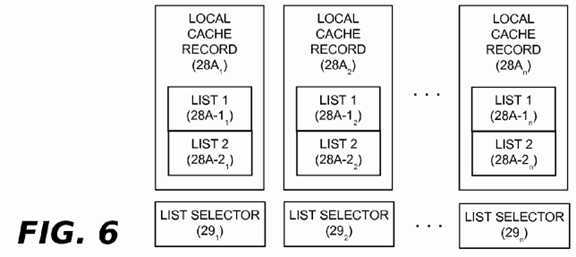
One way of managing the foregoing synchronization overhead would be to have each local cache record data structure28A1,?28A2?. . .?28An?optionally maintain two separate lists of cacheline information. As shown in?FIG. 6, a first list?28A-1could comprise cacheline information that has already been communicated and a second list?28A-2?could be used to accumulate cache lines from ongoing invocations of the record operation. Each processor (or processor group) would then indicate which of its two lists was in effect for the current grace period. This could be done by setting a list selector?29?1,?292?. . .?29?n?that is maintained in association with each local cache record data structure?28A1,?28A2?. . .?28An. As an optimization, each processor (or processor group) could also indicate whether or not its current list was empty. Given that RCU tends to be used in read-mostly situations, the cacheline information lists?28A-1?and?28A-2?will often be empty, and such an indication can avoid the need for useless scanning of empty lists.
An alternative approach is to have each processor (or processor group) implement the communicate operation by consolidating the cacheline information of its local cache record data structure?28A in a global data structure. For example, whenever a processor?4?begins or acknowledges a new grace period, the communicate sub-component?26B-1?may communicate cacheline information in the local cache record data structure?28A by placing this information in an optional global cache record data structure?28B, as shown in?FIG. 5. Each processor (or processor group) may then implement the flush cache component?26B-1?to consult the global cache record data structure?28B use the information therein to flush their local cache(s) before the grace period ends. This approach avoids the N2?complexity of multiple processors (or processor groups) scanning each of the local cache record data structures?28A1,?28A2?. . .?28An?maintained by other processors (or processor groups), but requires a synchronization scheme (e.g., locking) to serialize access to the global cache record data structure?28B.
Hierarchical RCU implementations can mitigate this synchronization overhead in systems having a large number of processors. In hierarchical RCU, a hierarchy of grace period-tracking structures (not shown) is used to record processor quiescent states and track other grace period-related information. Each leaf-position grace period-tracking structure in the hierarchy is shared by a relatively small number of processors to reduce synchronization overhead. When all processors sharing a given leaf-position grace period-tracking structure have recorded a quiescent state, the leaf-position structure merges its own quiescent state information in a branch-position grace period-tracking structure that occupies a next higher level of the hierarchy, and which serves some number of leaf-position structures. Eventually, quiescent states are propagated up through the hierarchy to a root-position grace-period tracking structure, at which point the system may be deemed to have reached a global quiescent state.
In systems implementing hierarchical RCU, the grace-period tracking structure hierarchy can be modified to provide a hierarchy of the cache record data structures?28A (see optional element?28C of?FIG. 5). By way of example, the local cache record data structures?28A1,?28A2?. . .?28An?shown in?FIG. 5?could be incorporated into or otherwise associated with corresponding leaf-position grace period tracking structures. The cacheline information stored therein could then be periodically merged into one or more successive intermediate levels in the cache record data structure hierarchy?28C and until the cacheline information is passed up the hierarchy and ultimately merged into the global cache record data structure26B, which could be incorporated into or otherwise associated with a root-position grace period tracking structure. Managing the cacheline information in this manner can greatly reduce synchronization complexity. Synchronization is only needed among the processors sharing a given leaf-position structure and between the leaf-position and branch-position data structures that need to merge their information into higher level data structures in the hierarchy.
Non-hierarchical RCU implementations can gain a similar effect using only the local cache record data structures?28A1,28A2?. . .?28An?and the global cache record data structure?28B, and by breaking each grace period into two phases. During the first phase, a processor?4?that starts or notices a new grace period may merge cacheline information maintained by its local cache record data structure?28A into the global cache record data structure?28B. Once all of the local cache record data structures?28A1,?28A2?. . .?28An?have been merged, the second phase begins. In the second phase, each processor?4(or processor group) having an associated incoherent cache may flush its cache as it passes through a quiescent state using the cachelines indicated by the global cache record data structure?28B. Once all of the incoherent caches have been flushed, the grace period can end.
It will be appreciated that various alternative methods may be used for the communicate operation in lieu of the above techniques. For example, techniques that pass messages containing cacheline lists among the various processors (or processor groups) may be used, allowing each processor (or processor group) to build a list of cachelines that need to be flushed. It should be also be noted that user-level implementations of the RCU subsystem?20?may benefit from having updaters?18?use only the global cache record data structure?28B to both record cacheline information and communicate it on an application-wide basis (e.g., to all threads within a given user-level application). In that case, the global cache record data structure?28B could be implemented with a pair of lists (e.g., as shown in?FIG. 6), with one list being used for the record/communicate operation and the other list being used for the flush operation during any given grace period.
A first example implementation of the record, communicate and flush operations will now be described with reference toFIGS. 7-11. This implementation assumes there some number of processors?4?1,?4?2?. . .?4?n?that each has an associated incoherent cache?10?1,?10?2?. . .?10?n. Per-processor local cache record data structures?28A1,?28A2?. . .?28An?are used for the record operation, and a single global cache record data structure?28B is used for the communicate and flush operations. The local record data structures?28A1,?28A2?. . .?28An?are implemented in the manner shown in?FIG. 5, with each such data structure being implemented as an array comprising a run-length encoding of cacheline information. As discussed above, the run-length encoding may comprise a set of integer pairs of the form {x,y} in which one integer of each pair is the beginning bit index for the corresponding run and the other integer is the number of bits in the run. A global lock may be used to synchronize access to the global cache record data structure?28B. As shown in?FIG. 5, a processor counter?28D and a grace period phase counter?28E are also used. The processor counter?28D keeps track of the number of processors (or processor groups) that need to perform the communicate and flush operations. The phase counter?28E is used to divide grace period processing into separate defined phases.
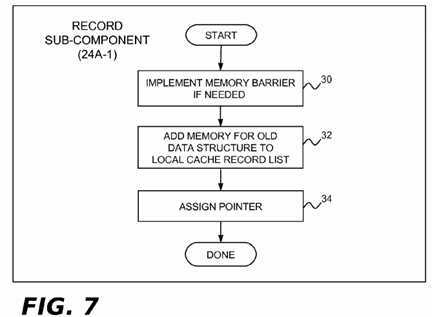
In the present example implementation, the record sub-component?24A-1?of?FIG. 5?may use a modified version of the rcu_assign_pointer( ) primitive found in existing RCU implementations. In current Linux? versions of RCU, the rcu_assign_pointer( ) primitive is a C language macro whose arguments comprise a first pointer "p" and a second pointer "v." The first pointer p references an existing data structure (e.g. a list element being modified or deleted, or marking the location where a new list element will be inserted). The second pointer v is a new pointer that the updater?18?has allocated and initialized to reference a new or different data structure (e.g., a new list element being inserted in a list, a modified version of an existing list element, or a list element that follows a list element being deleted from a list).?FIG. 7?illustrates example operations of the record sub-component?24A-1. Blocks?30?and?34?are found in the existing rcu_assign_pointer( ) primitive, while block?32?is new. In block?30, a write memory barrier instruction (e.g. the smp_wmb( ) barrier primitive used in the Linux? kernel) is conditionally executed if it is necessary to ensure that block?34, which assigns the value of pointer v to pointer p, is seen by other processors as having occurred following the pointer allocation and initialization operations for pointer v that preceded the call to rcu_assign_pointer( ). For example, the memory barrier instruction of block?30?may be needed if pointer v is neither a defined constant (known to the compiler) nor a NULL pointer. Block?32?is unique to the present disclosure. It adds the range of memory for the data structure referenced by pointer p to the run-length encoding in the local cache record data structure?28A assigned to the processor?4?that is performing the update operation, using the value of p as the starting memory address and the C language operator sizeof(*p) to determine the memory extent of the data structure.
In the present example implementation, the record special case component?24B may perform the single operation shown in block?40?of?FIG. 8. It may used in cases where the record sub-component?24A-1?is not able to record the full extent of a data structure that needs to be flushed from cache memory. One example would be where each element of a linked list is itself a linked tree structure. When such a list element is modified, an updater?18?could perform an update operation that ends with an invocation of the record sub-component?24A-1. The updater?18?could then traverse the remaining linked tree structure elements linked to the modified list element, following the pointer to each element, determining its size, and invoking the record special case component?24B to flush such element from cache memory. The record special case component24B may be implemented as a function whose parameters are "*pp" (the data structure referenced by pointer p) and "size_t_s" (the data structure size). Block?40?adds the range of memory for the data structure referenced by pointer p to the appropriate run-length encoding, using the value of p as the starting memory address and the value of s to determine the memory extent of the data structure. Again, the run-length encoding that is updated by block?32?will be in the local cache record data structure?28A assigned to the processor?4?that is performing the update operation.
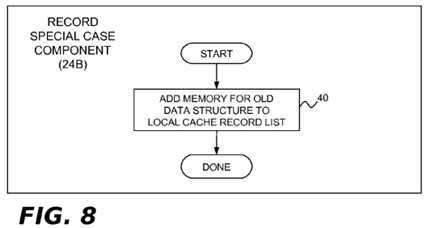
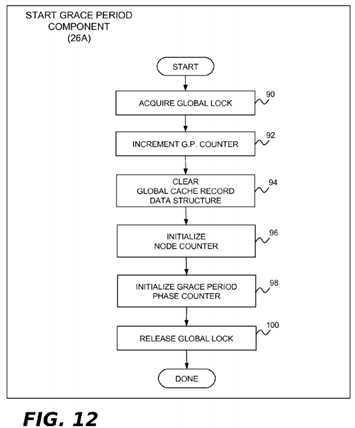
In the present example implementation, the start grace period component?26A is implemented by the processor?4?that starts a new grace period. This component may perform the operations shown in?FIG. 9?in order to initialize the global cache record?28B for use during a new grace period. In block?50, the lock for the global cache record data structure?28B is acquired. Block?52?clears the global cache record data structure?28B, emptying it of all previous run-length encodings. In block?54, the processor counter?28D is initialized to a value representing the total number of processors?4?1,?4?2?. . .?4?n?in the system (e.g., the system?2?of?FIG. 4). In block?56, the phase counter is initialized to phase?1, which is the phase during which the communicate operations are performed. Block?58?releases the lock for the global cache record data structure28B.
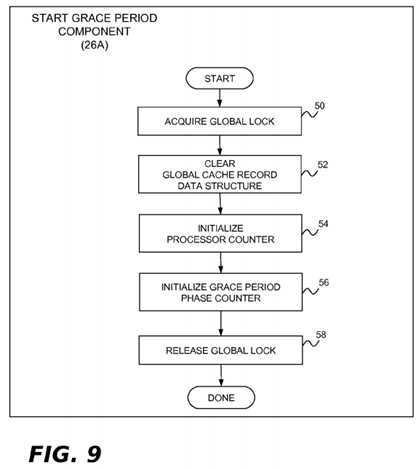
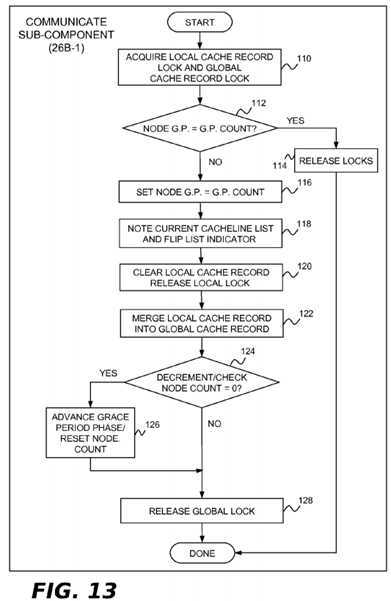
In the present example implementation, the communicate sub-component?26B-1?is invoked by each processor?4?when it notices that a new grace period has started. This component may perform the operations shown in?FIG. 10?to communicate cacheline information from the processor‘s local cache record data structure?28A to the global cache record data structure28B. In block?60, the lock for the global cache record data structure?28B is acquired. In block?62, the run-length encoding in the processor‘s assigned local cache record data structure?28A is merged into the global cache record data structure?28B. In block?64, the processor counter?28D is decremented and tested to see if this is the last processor performing the communicate operation for the current grace period. If it is, block?66?advances the phase counter to phase?2?and resets the processor counter?28D. Following block?66, or if there are more processors that need to invoke the communicate sub-component?26B-1?for this grace period, block?68?is implemented and the lock for the global cache record data structure?28B is released. Block?70?is then performed to clear the local cache record data structure?28A that was just merged into the global cache record data structure?28B.
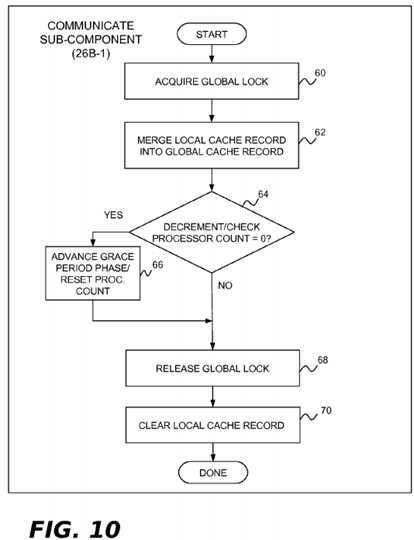
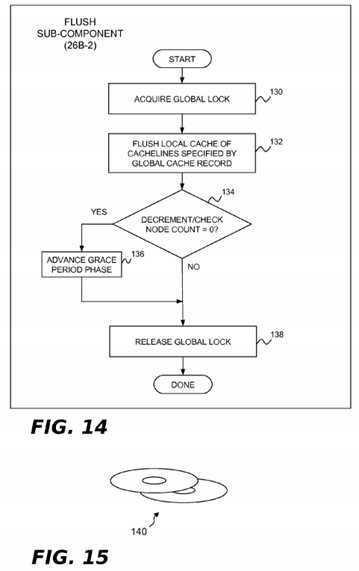
In the present example implementation, the flush sub-component?26B-2?is invoked by each processor?4?when it has passed through a quiescent state since the beginning of the current grace period and notices that all processors have completed phase?1?of the grace period and phase?2?has been reached (e.g., by checking the phase counter?28E). This component may perform the operations shown in?FIG. 11?to flush cachelines identified by the global cache record data structure?28B from the processor‘s associated incoherent caches. In block?80, the lock for the global cache record data structure?28B is acquired. In block?82, the actual cache flush operation is performed. In block?84, the processor counter?28D is decremented and tested to see if this is the last processor performing the flush operation for the current grace period. If it is, block?86?advances the phase counter to phase?3. Following block?86, or if there are more processors that need to perform the flush operation for this grace period, block?88?is implemented and the lock for the global cache record data structure?28B is released.
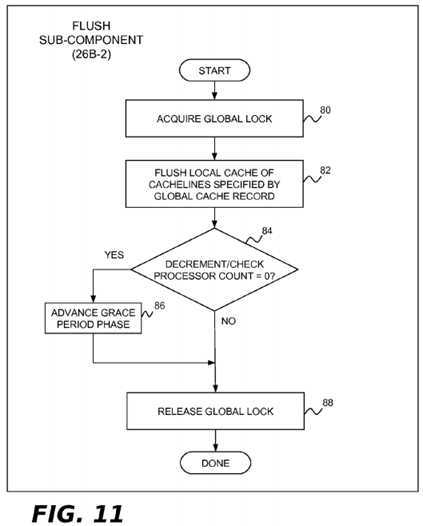
At this point, the end grace period sub-component?26B-3?can end the current grace period. Normal callback processing may then be performed by the process callbacks component?26C (if asynchronous grace periods are supported). Updaters18?using synchronous grace periods may likewise free memory blocks associated with synchronous updates.
A second implementation of the record, communicate and flush operations will now be described with reference to?FIGS. 12-17. This implementation assumes the processors?4?1,?4?2?. . .?4?n?are grouped into nodes (or other groupings). As previously discussed, the cache?10?of each processor?4?in a given node may be cache-incoherent or cache-coherent. If per-processor processor caches?10?are coherent, then it is assumed that there is at least one per-node cache that is incoherent (such as the directory cache?17?of?FIG. 4A). In this implementation, the processors?4?1,?4?2?. . .?4?n?within a node may share a single local cache record data structure?28A for the record operation. Each processor?4?will access the local cache record data structure?28A when an updater?18?performs the record operation. However, only one processor?4?needs to perform the communicate operation on behalf of the other node processors, thereby acting as a proxy processor with respect to this operation. Insofar as local cache record data structure?28A is accessed by plural processors?4?1,?4?2?. . .?4?n, a synchronization technique is needed to serialize access to this data structure. One technique is simply use a lock that must be acquired by each processor?4?performing the record operation and by whichever processor is performing the communicate operation. Alternatively, the local cache record data structure?28A could be implemented in the manner shown in?FIG. 6, with two cacheline lists?28A-1?and?28A-2. During any give grace period, one cacheline list?28A-1?or?28A-2?would be used by processors?4?1,?4?2?. . .?4?n?that are performing the record operation and the other cacheline list would be used by the processor?4?that performs the record operation. The list selector?29?shown in?FIG. 6?could be used to identify which cacheline list?28A-1?or?28A-2?is to be used for the record operation. The processor?4?that performs the communicate operation could be responsible for updating the list selector?29?to swap the cacheline lists. A lock would be acquired by each processor?4?that accesses the local cache record data structure?28A. However, the processor?4?that performs the communicate operation could drop the lock after updating the list selector?29?insofar as the communicate operation would be merging one cacheline list?28A-1?or?28A-2?while the record operations are using the other cacheline list.
As shown in?FIG. 5, a node counter?28F, a global grace period counter?28G, and a set of per-node grace period counters28H1?. . .?28Hm?may be used in addition to the grace period phase counter?28E. The processor counter?28D may or may not be needed, as described in more detail below in connection with the flush sub-component?26B-2. The node counter?28D keeps track of the number of nodes that need to perform the communicate and flush operations. The global grace period counter?28E tracks system-wide grace periods and is used determine which processor?4?in a given node will perform the communicate operation. For example, the first node processor?4?to notice the start of a new grace period may act as the node‘s designated communicator. Each node grace period counter?28H is set on behalf of each node by the processor?4that performs the communicate operation on behalf of the node. This advises other node processors that the communicate operation has already been performed for the current grace period.
In the present example implementation, the record sub-component?24A-1?may be implemented in the manner shown in?FIG. 7, except that block?32?uses the list indicator?29?for the node‘s local cache record data structure?28A to determine which cacheline list?28A-1?or?28A-2?to use for the record operation. Similarly, the record special case component?24B may be implemented in the manner shown in?FIG. 8, except that block?40?will also use the list selector?29?to record cacheline information into the correct cacheline list. The start grace period component?26A, the communicate sub-component?26B-1and the flush sub-component?26B-2?are all modified for the present implementation, as will now be discussed.
The start grace period component?26A for the present example implementation may perform the operations shown in?FIG. 12. In block?90, the lock for the global cache record data structure?28B is acquired. Block?92?increments the grace period counter?28G and block?94?clears the global cache record data structure?28B, emptying it of all previous run-length encodings. In block?96, the node counter?28F is initialized to a value representing the total number of nodes in the system (e.g., the system?2?of?FIG. 4A). In block?98, the phase counter is initialized to phase?1, which is the phase during which the communicate operations are performed. Block?100?releases the lock for the global cache record data structure?28B.
The communicate sub-component?26B-1?for the present example implementation may perform the operations shown in?FIG. 13?to communicate cacheline information from a node‘s local cache record data structure?28A to the global cache record data structure?28B. In block?110, the locks for the local cache record data structure?28A and the global cache record data structure?28B is acquired. In block?112, a check is made to determine if the node grace period counter?28H has been updated to the same value as the global grace period counter?28G. If it has, then another node processor has already performed the communicate operation and processing can terminate. If the grace period counts are not equal in block?112, it means that the current processor?4?is the first processor to perform the communicate operation for the node. This is indicated in block?116?by setting the node grace period counter?28H equal to the global grace period counter?28G. In block118, the current cacheline list?28A-1?or?28A-2?of the node‘s local cache record data structure?28A is noted and the list selector?29?is flipped so that subsequent record operations will start using the other cacheline list. In block?120, the cacheline list?28A-1?or?28A-2?that was noted in block?118?is cleared and the lock for the node‘s local cache record data structure is released. As stated above, this lock is no longer needed because the record operations are now using the other cacheline list. In block?122, the cacheline list?28A-1?or?28A-2?that was noted in block?118?is merged into the global cache record data structure?28B. In block?124, the node counter?28F is decremented and tested to see if this is the last node performing the communicate operation for the current grace period. If it is, block?126?advances the phase counter to phase2?and resets the node counter?28F. Following block?126, or if there are more nodes that need to invoke the communicate sub-component?26B-1?for this grace period, block?128?is implemented and the lock for the global cache record data structure?28B is released.
The flush sub-component?26B-2?for the present example implementation may perform the operations shown in?FIG. 14?to flush cachelines identified by the global cache record data structure?28B from the incoherent cache(s) of each node. In block?130, the lock for the global cache record data structure?28B is acquired. In block?132, the actual cache flush operation is performed. In this implementation, the processor?4?that invokes the flush sub-component?26B-2?may flush its own local cache (if it is non-coherent) and may also act as a proxy processor on behalf of other node processors to clear their caches as well, together with any incoherent directory cache that may be present in the node. For example, if there are multiple processors?4?on a given cache-coherent node, most hardware configurations will permit a given processor to flush all copies of a given cache line from the node, including those held in other processor‘s caches. One way to handle this would be for a processor to write to the cache line to flush it from the other processor‘s caches, then execute the instructions required to flush it from its own cache and from all shared caches. In such cases, only one processor in a given node need do any flushing for a given grace period. A shared indicator could be used to allow subsequent processors in the same node to omit cache flushing for the current grace period. For example, a second set of the per-node grace period counters?28H1?. . .?28Hm?could be used for this purpose. Although not shown in?FIG. 14, such counters could be manipulated by the first node processor to perform the flush operation on behalf of its node peers using the same processing shown in blocks?112?and?116?of?FIG. 13. Returning now to?FIG. 14, block?134?decrements the node counter?28F and tests it to see if this is the last node performing the flush operation for the current grace period. If it is, block?136advances the phase counter to phase?3. Following block?136, or if there are more nodes that need to perform the flush operation for this grace period, block?138?is implemented and the lock for the global cache record data structure?28B is released.
At this point, the end grace period sub-component?26B-3?can end the current grace period. Normal callback processing may then be performed by the process callbacks component?26C (if asynchronous grace periods are supported). Updaters18?using synchronous grace periods may likewise free memory blocks associated with synchronous updates.
Accordingly, an RCU implementation for non-cache-coherent systems has been disclosed. It will be appreciated that the foregoing concepts may be variously embodied in any of a data processing system, a machine implemented method, and a computer program product in which programming logic is provided by one or more machine-useable storage media for use in controlling a data processing system to perform the required functions. Example embodiments of a data processing system and machine implemented method were previously described in connection with?FIGS. 4-14. With respect to a computer program product, digitally encoded program instructions may be stored on one or more computer-readable data storage media for use in controlling a computer or other digital machine or device to perform the required functions. The program instructions may be embodied as machine language code that is ready for loading and execution by the machine apparatus, or the program instructions may comprise a higher level language that can be assembled, compiled or interpreted into machine language. Example languages include, but are not limited to C, C++, assembly, to name but a few. When implemented on a machine comprising a processor, the program instructions combine with the processor to provide a particular machine that operates analogously to specific logic circuits, which themselves could be used to implement the disclosed subject matter.
SRC=https://www.google.com/patents/US20140089596
Read-Copy Update Implementation For Non-Cache-Coherent Systems,布布扣,bubuko.com
Read-Copy Update Implementation For Non-Cache-Coherent Systems
标签:des style blog http color os io strong
原文地址:http://www.cnblogs.com/coryxie/p/3922700.html