标签:动态 行合并 body 分布式 分享 管理 分配 服务器 一致性
避嫌声明:所有图文都是根据自己的理解原创,且已离开这家公司三年以上,不存在保密协议,写此文只是用来分享知识、探究不足。
牢骚:本来想弄个ppt交互展示的,不过我的js权限还没批。。。
关系型数据库处理永久、稳定的数据,内存数据库就是将其数据放在内存中,活动事务只与内存数据打交道,重新设计了体系结构并且在数据缓存、快速算法、并行操作方面也进行了相应的改进,所以数据处理速度比磁盘数据库要快很多,一般都在10倍以上。但它不容易恢复,可能暂时不一致或非绝对正确的,要求较大的内存量,而64位操作系统可以支持更大的地址(2T),为内存数据库的实现提供了可能。
计算密集型是指,每个请求的命令中,大都包含不同的参数值,很难重用前一次计算的结果,所以要按照约定的业务逻辑重新计算,并按照约定的格式返回数据,且计算在总耗时中占比较大。
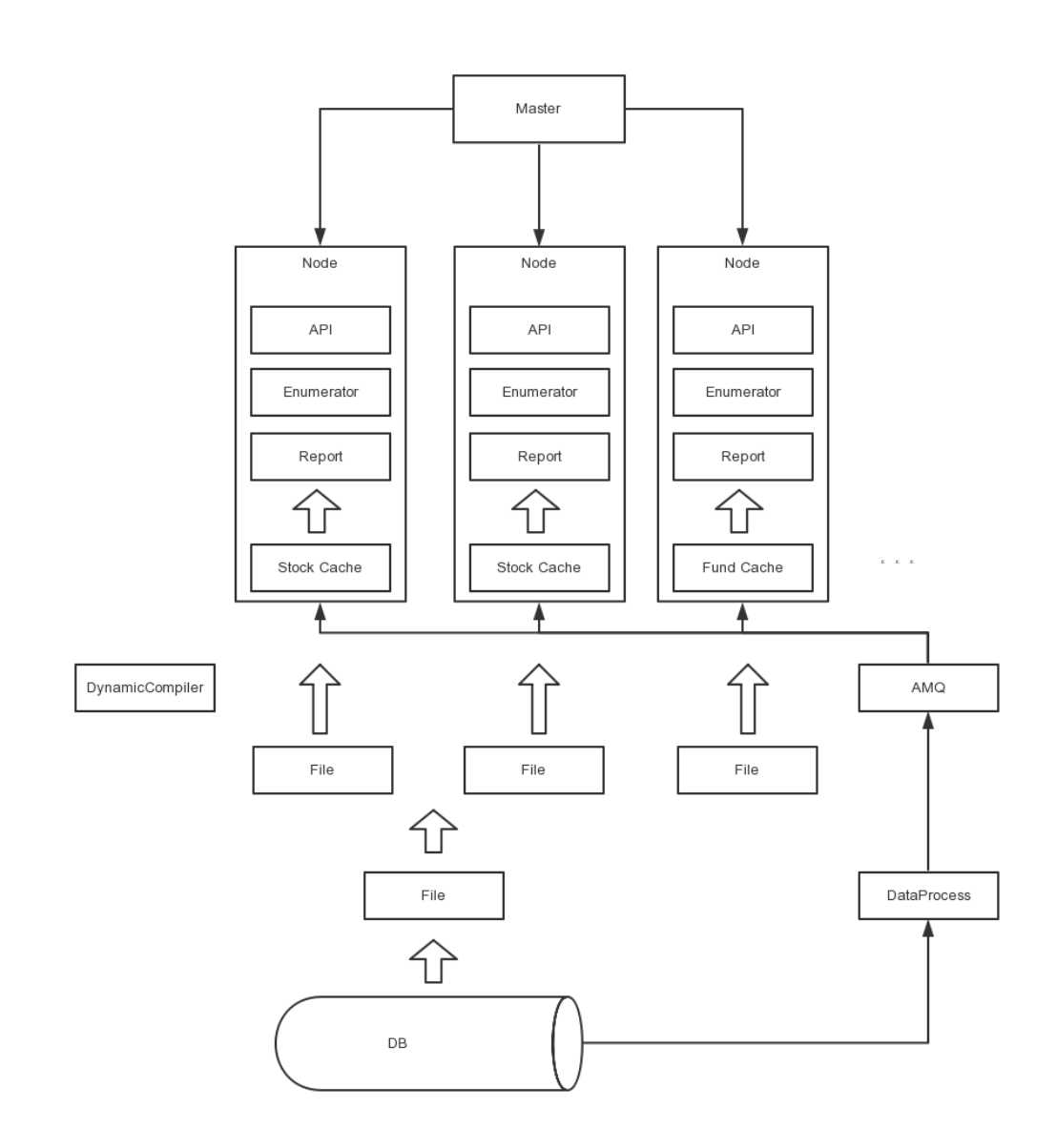
数据存储在DB中,直接访问数据库。但数据库压力太大,系统瓶颈明显。
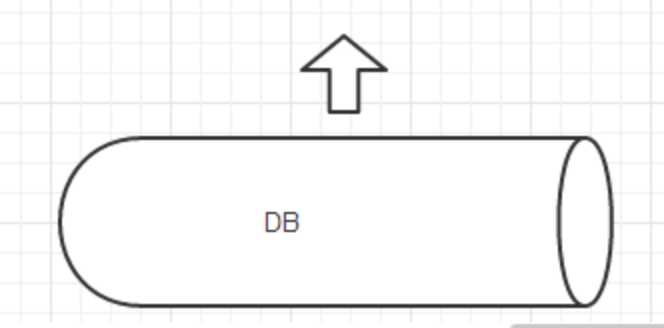
将DB中的数据加载到节点的内存中,并定时从数据更新日志库中读取来更新内存的数据,极大减轻数据库的压力。
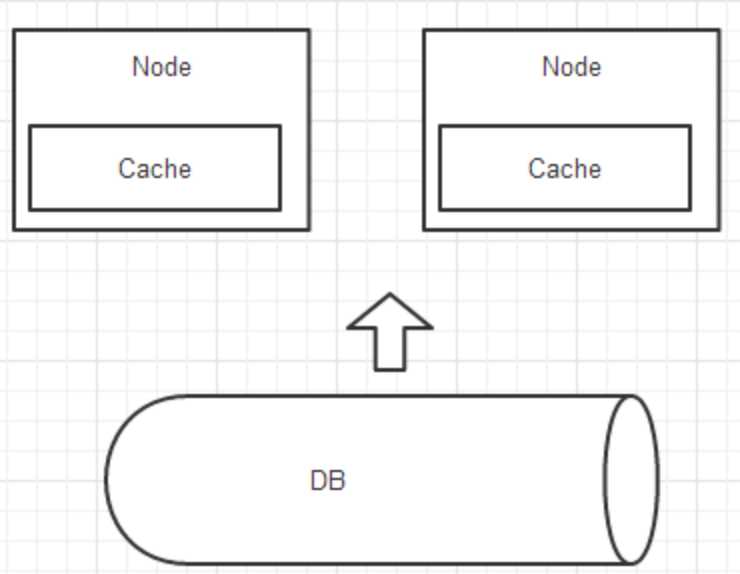
但随着数据的膨胀,节点启动加载慢,升级时间长,宕机恢复难等。
每天晚上从DB读取数据,生成带有数据同步标识的数据文件,分发到各个服务器节点。节点启动时,直接从本地数据文件加载,大大提高了启动速度。
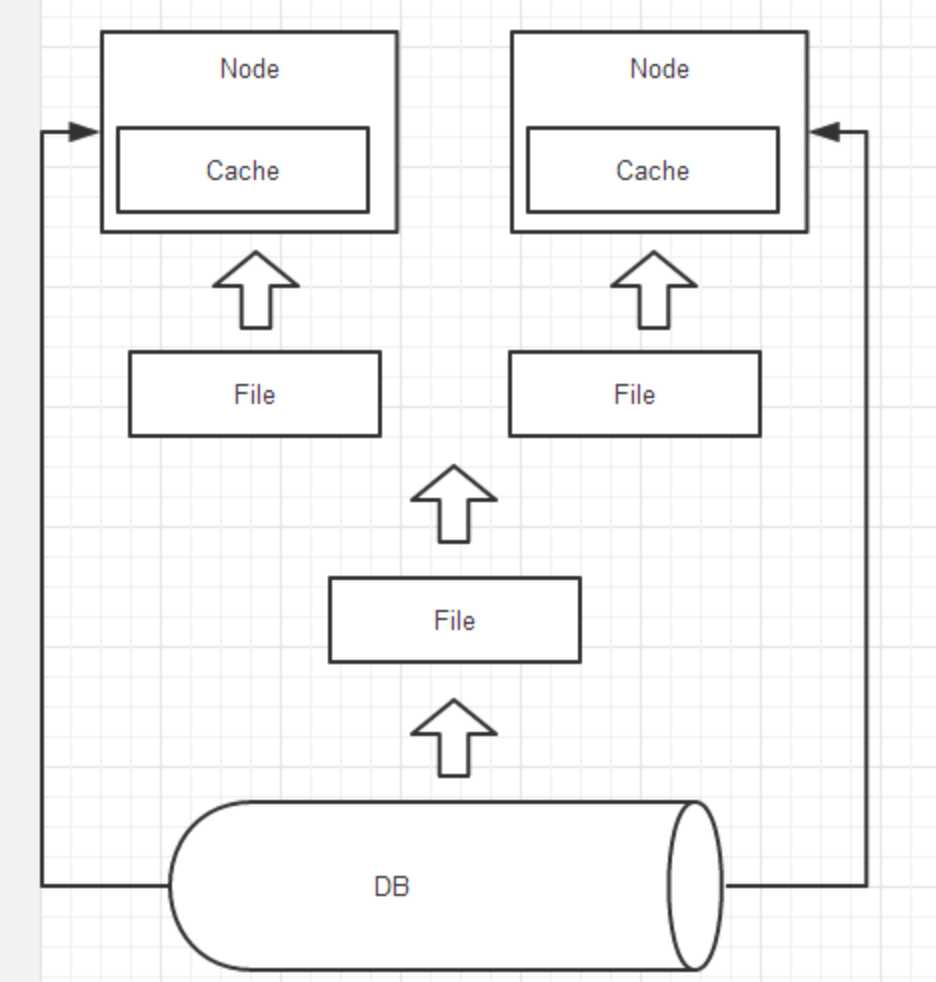
但随着DB中数据的更新,实例间数据不一致性严重。
通过DP服务定时监控数据更新日志库中的记录,通过AMQ发布给订阅的每个节点,节点根据当前同步的标识决定是否处理消息记录,根据消息记录的属性执行具体的增删改操作,使得数据的一致性较好。
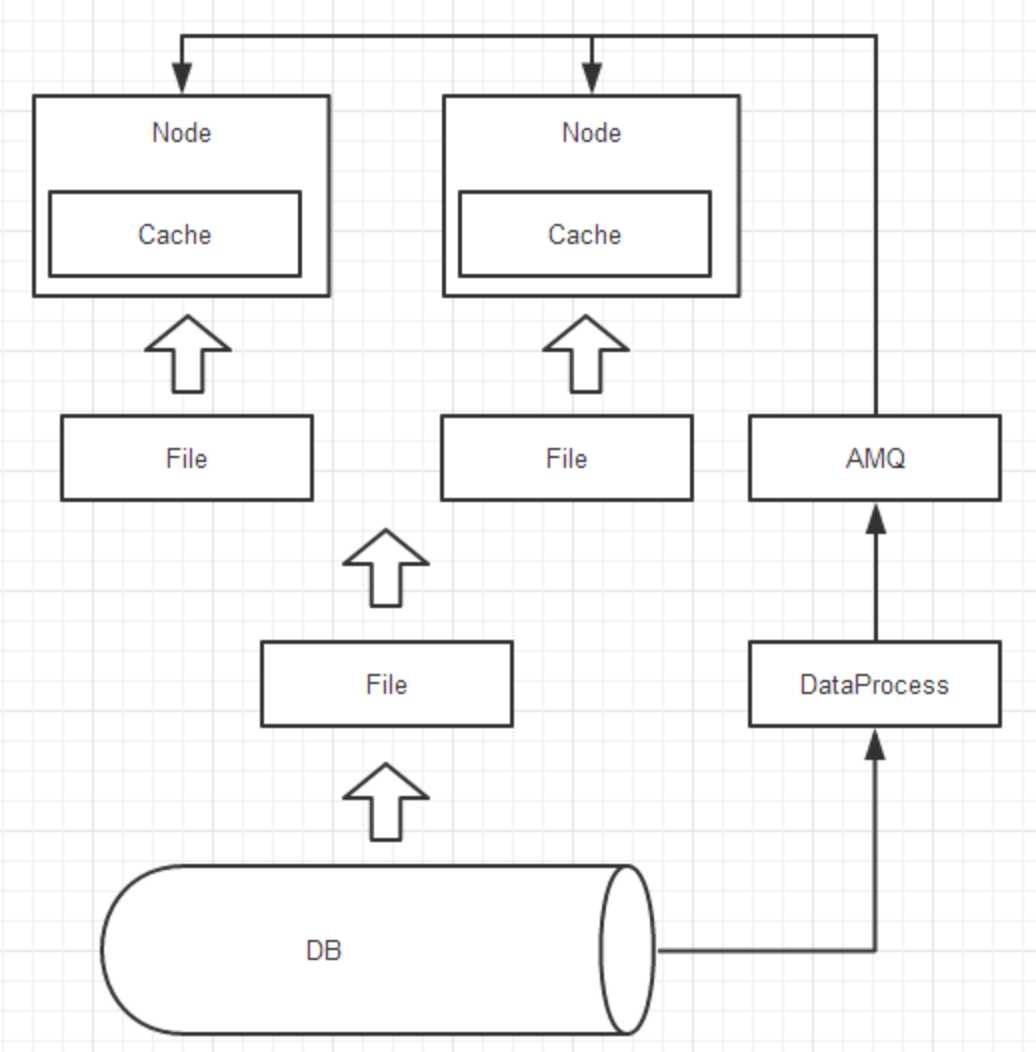
但单个节点内存过大,大数据量时仍会变慢,卡顿现象频繁且耗时较长。
按照业务将数据拆分到不同的节点上,通过管理节点分配任务,使得内存大小可控,卡顿频率和耗时明显减少。
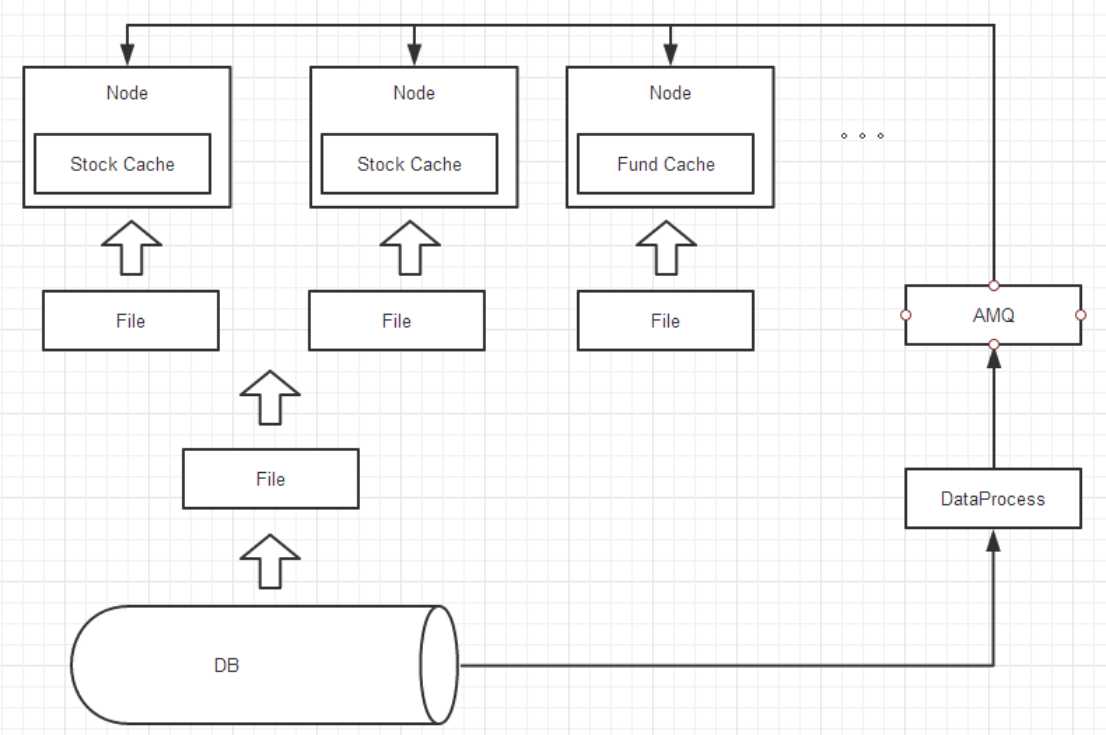
但生产bug、业务逻辑变更或新增需求时,只能重启服务,不够灵敏,可维护性差。
利用CodeDom实现动态编译,在运行时增加或修改业务逻辑。
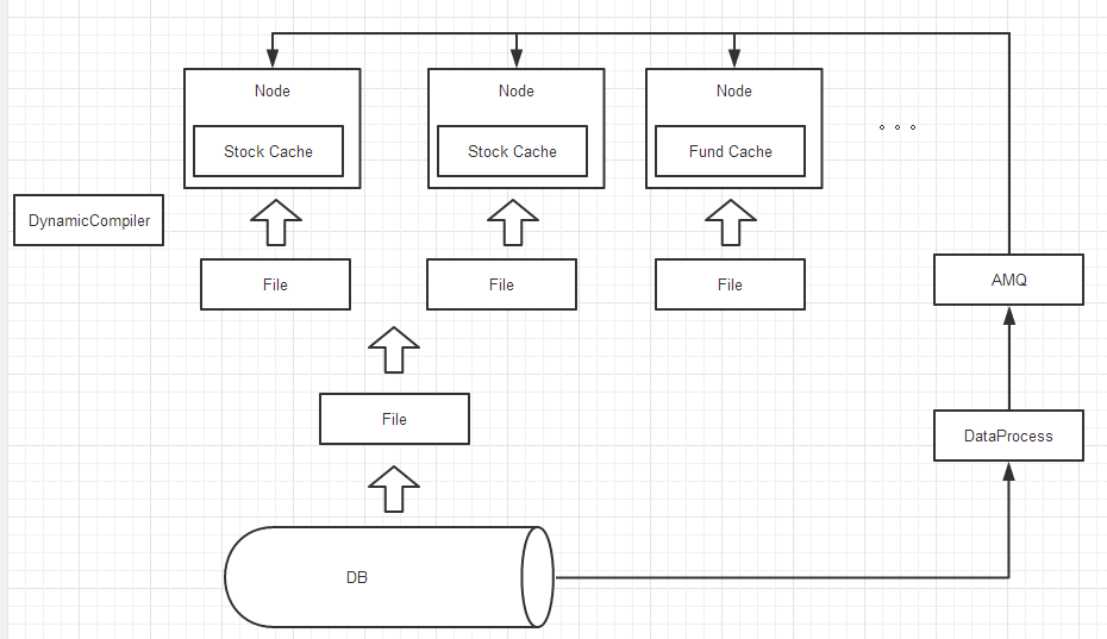
另外,可以为每个节点对应一个独立的DataProcess。
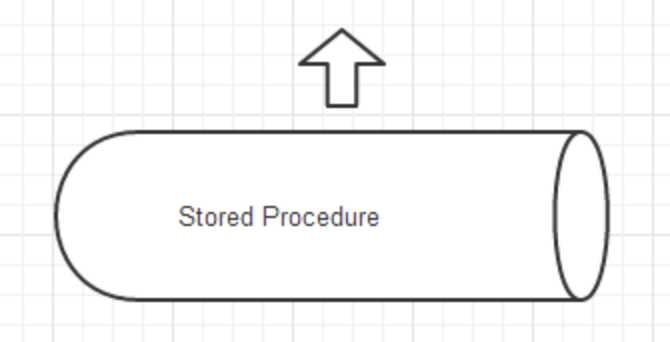
将业务逻辑写到存储过程中,难以维护,请求排队现象严重。
通过缓存节点的中间层对外提供服务,在缓存数据的基础上,提供:获取单个运算结果的API(对外),获取数据集合的Enumerator(对内),获取数据运算结果集合的Report(对外),内存读取速度较快。
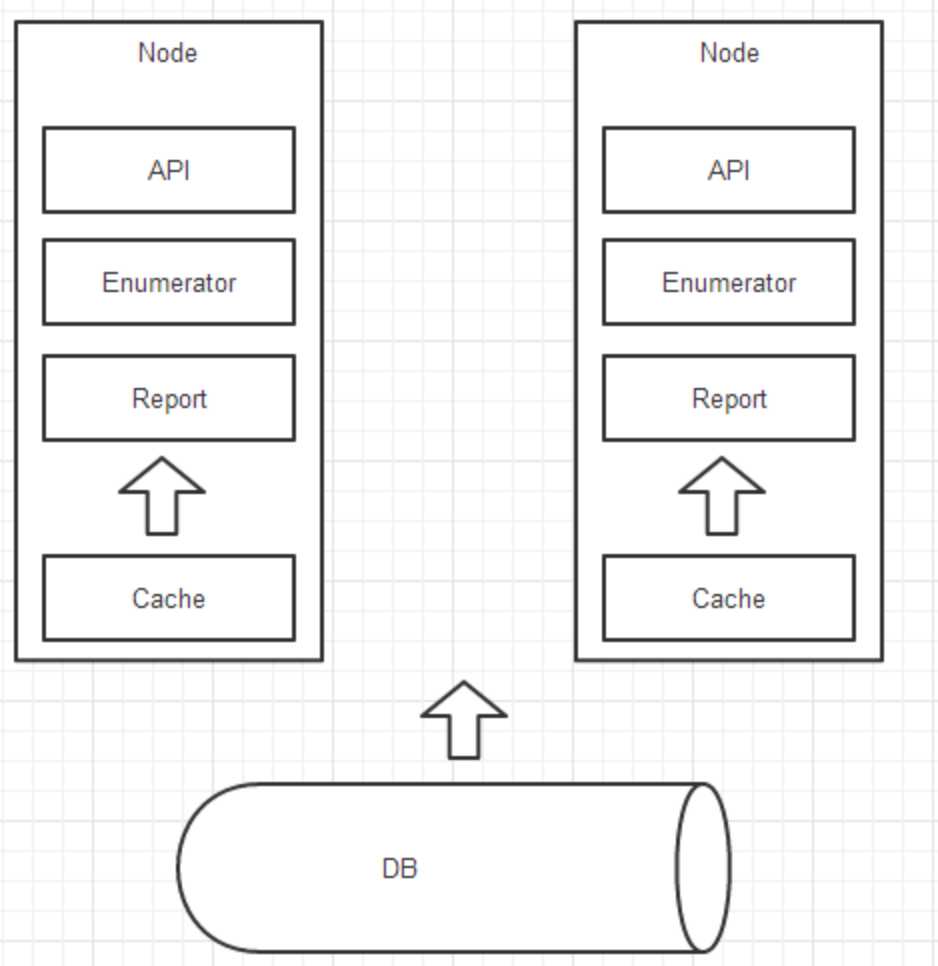
但很难有效的负载均衡,无法高效并行。
通过Master节点,将请求分给对应的若干工作节点并行处理,再对结果进行合并和归纳,返回给客户端,实现高效并行处理。
延伸:数据运算的耗时,大都在查找、比较、排序、序列化、压缩、加密处理等,根据性能分析逐个调优。
当内存越大时,二代回收耗费几秒甚至十几秒,会挂起所有线程而使节点在这段时间内不能正常工作。
1.可设置多核并发的Server GC模式,为每个核创建单独的大小堆和GC线程,减少回收的粒度和影响。
2.监控将要发生回收的工作节点,通知Mater并暂停该工作节点提供服务,直至GC完成。
1.运行时内存的增加,主要是因为创建了很多临时对象。所以,要尽量少用Linq,尽量避免创建不必要的对象。
2.频繁使用的字符串可尝试采用驻留机制。
3.将不常用的历史数据以文件方式存储和更新而不放入内存。
4.业务拆分减少每个节点要加载的数据。
5.尽量避免创建大对象,必要时通过弱引用+延迟加载处理大对象。
标签:动态 行合并 body 分布式 分享 管理 分配 服务器 一致性
原文地址:http://www.cnblogs.com/Leo_wl/p/6338067.html