标签:select lov 关系 win replica check running health alt
资源组是由一个或多个资源组成的组,WSFC的故障转移是以资源组为单位的,资源组中的资源是相互依赖的,相互关联。一个资源所依赖的其他资源必须和该资源处于同一个资源组,跨资源组的依赖关系是不存在的。在任何时候,每个资源组都仅属于集群中的一个结点,该结点就是资源组的活跃结点,由活跃结点为应用程序提供服务。AlwaysOn的故障转移特性建立在WSFC的健康检测和故障转移的特性之上,因此,AlwaysOn和故障转移集群有了不可分割的关系,理解他们的关系,有助于维护更好的维护AlwaysOn。
一,可用性组是集群的资源组
AlwaysOn的可用性组(Availability Group)是集群的资源组,其资源类型是“SQL Server Availability Group”,由于,WSFC的故障转移是以资源组为单位的,因此,AlwaysOn的每次故障转移都会将整个可用性组里的数据库一起转移。
1,查看集群的资源组
打开故障转移集群管理器(Failover Cluster Manager),选中集群结点,点开Roles,集群的每个角色就是一个资源组,在右边的资源组监控器面板中,能够看到创建成功的可用性组 TestAG,角色类型(Type)是Other;

2,资源组的故障转移属性
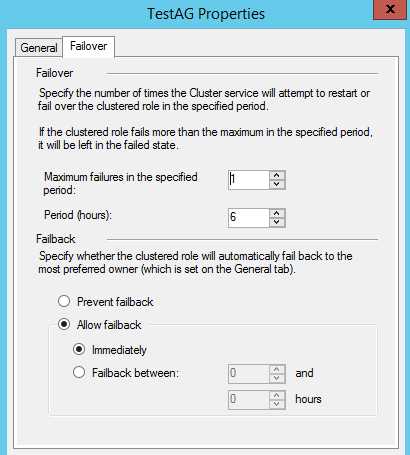
右击角色的属性,在Failover Tab中,查看集群的故障转移属性的设置,默认设置如下图:
两者的区别是:
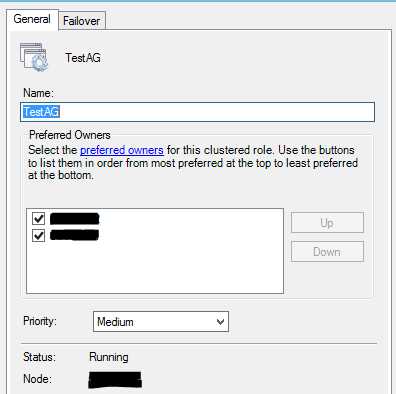
3,切换到General Tab
首选结点(Preferred Owners)选项的默认设置是勾选集群中的所有结点,优先顺序是从上到下,第一个勾选的结点是最优先结点(Most Preferred Owners)。
在发生故障转移之后,如果最优先结点恢复健康,那么故障恢复(Failback)将资源组移回到最优先选结点;
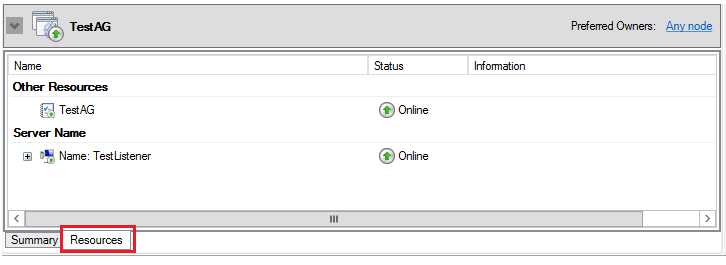
二,集群资源的属性
由于AlwaysOn 可用性组建立在故障转移集群之上,Windows 集群负责监控AlwaysOn 可用性组的健康状况。点击角色TestAG下方面板Resource选项卡,能够看到该资源组拥有两个资源:可用性组TestAG和Listener。每个资源,都有Status标识该资源的健康状态。
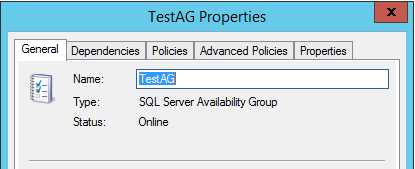
1,SQL Server 可用性组资源的属性
TestAG资源的类型是SQL Server Availability Group,状态是Online
2,切换到Dependencies Tab,查看资源的依赖关系
资源组中的资源是相互依赖的,一个资源所依赖的其他资源必须和该资源处于同一个资源组,跨资源组的依赖关系是不存在的。资源TestAG 和 资源Server Name之间是“and”的关系,这就是说,只有这两个资源都处于Online状态之后,整个资源组才处于可用的Online状态。
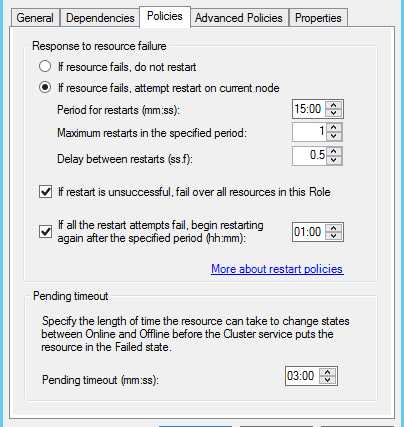
3,切换到Policies Tab,查看资源出现故障时,集群监控器的响应策略
该选项卡的选项决定了资源发生故障转移时的行为,建议保留其默认设置,默认设置是当资源出现故障时,会在15分钟内尝试在当前结点重启(一般是立即尝试重启,不需要等待15分钟),第一次尝试重启失败,就会将整个资源组转移到其他的结点上。
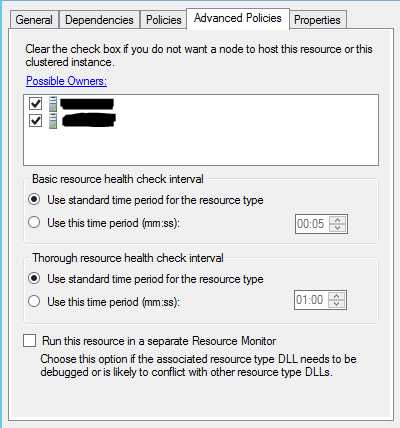
4,切换到Advanced Policies Tab
配置持有资源的集群结点,配置资源监控器(Resource Monitor)检测资源健康的时间间隔,WSFC为了检测每个资源是否工作正常,会使用不同的时间间隔来做两种不同程度的检查,对于SQL Server可用组资源类型:
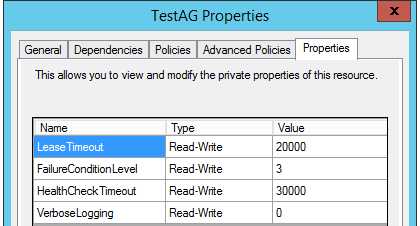
5,切换到Properties Tab
查看和配置资源的私有属性,可用性组HealthCheckTimeout属性默认设置:30000ms,这就是说,每30s,资源监控器都会对资源进行一次健康检测;
三,集群资源的健康检测
集群中的每个资源都有一个资源类型,WSFC根据不同类型的资源,使用不同的方式进行Isalive和Looksalive检查,一般会把SQL Server Availability Group资源类型配置成“If resource fails, attempt restart on current node” 和 “If restart is unsuccessufll, fail over all resources in this service or application”模式,即在资源的Policies 选项卡中勾选相应的选项:
Looksalive检查:WSFC检查活跃结点的SQL Server服务(Service Name 是 MSSQLServer)是否处于“启动状态”,根据SQL Server Availability Group资源的Advance Polices 选项卡中的设置,这个检查默认每5s做一次;
Isalive检查:WSFC连接活跃结点,并在活跃结点中执行TSQL查询语句(select @@ServerName),如果活跃结点返回查询的结果,那么Isalive检查成功;如果活跃结点的SQL Server实例连接不上,或没有返回查询结果,那么Isalive检查失败,根据SQL Server Availability Group资源的Advance Polices选项卡中的设置,这个检查默认每30s做一次。
每执行6次Looksalive检查,就会执行一次Isalive检查,WSFC之所以需要对SQL Server 可用性组执行Isalive检查,是因为即使SQL Server 服务处于正在运行(Running)状态,也不能说明SQL Server 可以响应应用程序的请求,有时,可能整个SQL Server实例已经挂起,但是SQL Server服务的状态还是Running,所以需要Isalive 检查深入检查SQL Server的状态。此外,一旦looksalive检查失败,WSFC就会立即执行Isalive检查。
如果Isalive检查失败,WSFC会根据设置,重试3~5次Isalive检查。如果这些检查都失败了,WSFC就根据Polices选项卡中的设置进行故障转移,由集群仲裁选举出新的主副本(Primary Replica),Listener将SQL Server实例名和IP地址指向集群中新的主副本,由其该结点为应用程序继续提供服务,切换的过程是透明的。根据故障转移模式的不同,分为自动故障转移,手动故障转移和强制故障转移,详细信息请阅读《部署AlwaysOn第二步:配置AlwaysOn,创建可用性组》。
参考文档:
《SQL Server 2012 实施与管理实战指南》第二章
标签:select lov 关系 win replica check running health alt
原文地址:http://www.cnblogs.com/ljhdo/p/4533385.html