标签:方式 成本 -- images size linux off 可见 不能
参考
https://zhuanlan.zhihu.com/p/20768200?refer=auxten
而成本很多时候的体现就是对计算资源的消耗,其中最重要的一个资源就是CPU资源。
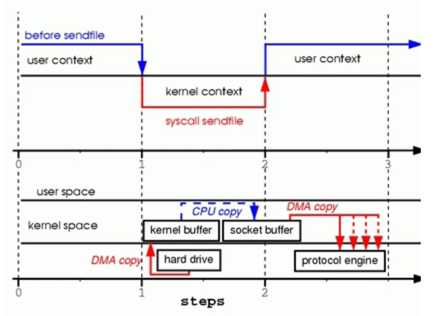
Sendfile(2)在这个时代背景下于2003年前后被加入Linux Kernel,陆续在各大UNIX、Linux、Solaris平台上获得了支持。这个系统内核调用本身被设计出来是用来从磁盘到TCP协议栈拷贝数据用的,但也我们也是可以把它用来做两个文件之间的数据拷贝。
在Linux Kernel 2.6版本中,这个系统调用的原型是这样的:
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count)
参数特别注意的是:in_fd必须是一个支持mmap函数的文件描述符,也就是说必须指向真实文件,不能使socket描述符和管道。
out_fd必须是一个socket描述符。
由此可见sendfile几乎是专门为在网络上传输文件而设计的。
在sendfile(2)出现之前,我们想要把一个文件发送到socket上需要进行如下几个步骤:
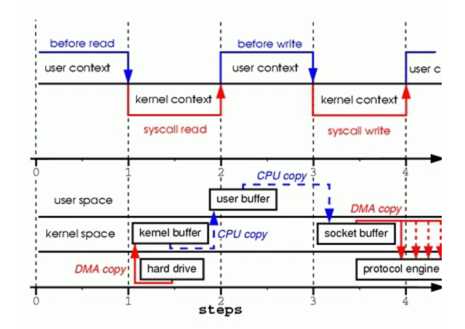
相比sendfile(2),“Read & Write”方式带来的性能损耗主要有两点:
标签:方式 成本 -- images size linux off 可见 不能
原文地址:http://www.cnblogs.com/charlesblc/p/6341605.html