标签:img 规模 性能 可能性 解释 上交 机器 image 颜色
1、课程主要内容
上节课中将到了各式各样的的机器学习种类,

这节课主要说明一下学习为什么是可行的;
(1)、在不加限制的数据集上学习是无法完成的
(2)、来自于同一分布的数据集的估计可以通过抽样法来进行估计,成立的原理就是霍夫曼不等式
(3)、单个固定的hypothesis情况下的霍夫曼不等式
(4)、多个且有限的hypothesis情况下的霍夫曼不等式
(5)、PAC准则
2、学习看似是不可能的
用已知的数据之间的规则去评价未知数据的结果,是无法获得到正确的学习结果,在不加限制的条件下,即使每次学习的规则都是合法的,但是总是可以说这个学习规则是不合理的,从这方面看,学习貌似是不可行的。
以识别图形为例:

给出以上六个数据,判断下列图形的归属;
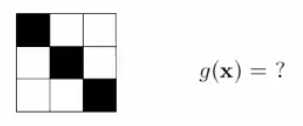
对于上述问题可以使用很对规则去对应其类别,比如说坐上交的颜色或者该图形是不是一个对称都是可以区分该种类,但是待判断图形的判断规则可能和判断已知图形的规则不同,这样学习的结果就是错误的。总之就是已知数据的规则和未知数据的规则可能不相同,这样的话学习必然是错误的。
另外一个例子:
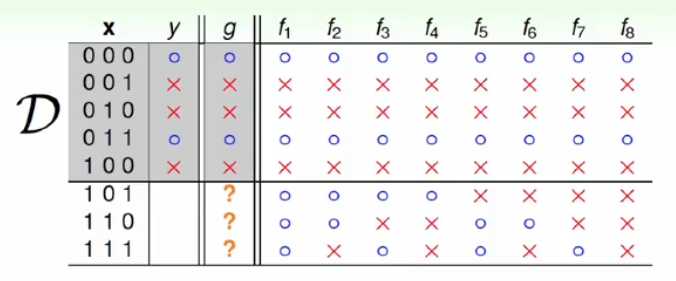
利用给出的几组数据判断x的结果,在假设空间集合上选定了一个g是得g(x) = y,在数据集D内部g≈f成立,但是在数据集D外的位置数据上,我们看到有很多种可能,这就说明在数据集D外, g ≈ f 不成立,但是这部分的预测结果才是我们想要的。
总之,预测目标函数f是未知的,因此只在已知的资料上看到的f的部分是没有办法去预测在未知资料上的表现或者结果,但是是不是加入一些限制条件就可以保证已知推未知?

3、从不可学习到可学习的可能性(probablity of rescue)
上面说了使用未知的预测目标函数f在已知数据集上的与预测目标函数g是相似的,在为未知数据上两者可能不相似,那么满足什么条件下就可以保证在已知数据集和未知数据集上预测函数g和预测目标函数都是相似的。

在使用已知去推测未知时,我们经常使用的工具就是概率论,表示一件事情发生或者不发生的可能性有多大。以下为例:

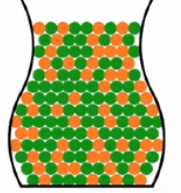
既然不能精确知道罐子中橙色的弹珠的比例,那么能不能近的知道呢?抽样法!
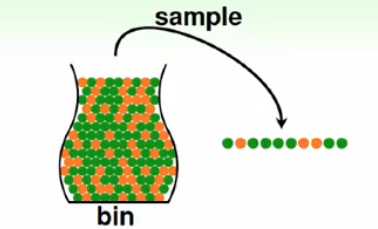
在罐子中拿出m个弹珠作为一个样本,统计样本中橙色弹珠和绿色弹珠的比例,可以得到一个比例

那么这个样本可以为估计整个罐子中橙绿比例提供什么信息呢?假如一个罐子中大部分都是橙色的,那么样本中大部分弹珠都是绿色的概率就很小

这个例子的数学表示就是:霍夫丁不等式;
如果样本规模为N

对于霍夫丁不等式来说:
(1)、对于所有的N和ε都是成立的
(2)、对于右侧的门限值来说与未知的μ无关
(3)、N越大或者ε很小都可以保证μ = ν的概率很大
PAC规则:

总之,如果数据都是有同一分布产生,那么使用抽样调查法进行局部估计全部是可行的,这一可行由PAC准则进行保证,也就解释了我们开篇提出的问题,什么情况下可以使用已知的数据去预测未知的数据,只有当已知数据和未知数据都是由同一分布产生,那么就可以使用已知数据去评估或者估算未知数据。
4、由例子到机器学习
弹珠例子: 学习:

对于弹珠和学习都是在同一分布下的数据进行的抽样学习;
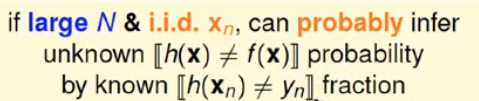
如果抽样样本数据够大并且该数据集都符合同一分布,那么通过了解已知数据的性质就可以代表未知数据的信息;
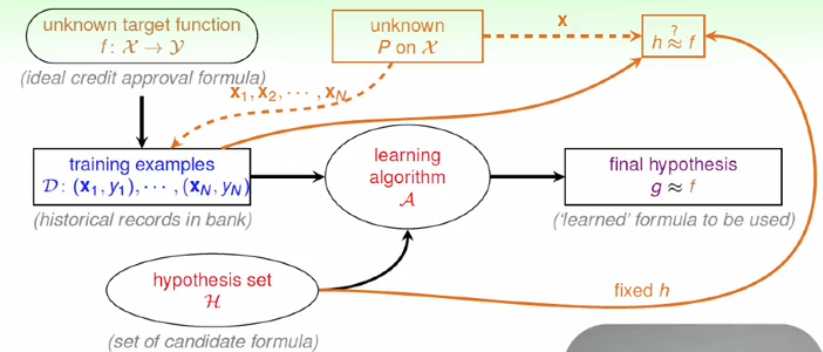
在整个学习流程中加上两个组件,一个组件是某分布产生训练数据,该分布可以是未知的,另外一个组件就是产生测试数据,对于假设空间站中的某一个固定的假设函数来进行检验;
然后引入Ein和Eout的概念:
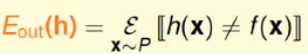 表示在整个数据输入空间上上预测函数h(x)与目标函数f(x)不一致的情况
表示在整个数据输入空间上上预测函数h(x)与目标函数f(x)不一致的情况
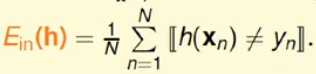 表示在训练数据上的预测函数h(x)与目标函数f(x)不一致的情况,对于f(x) = y永远成立;
表示在训练数据上的预测函数h(x)与目标函数f(x)不一致的情况,对于f(x) = y永远成立;
通过上面的讲解可以知道我们可以通过Ein来近似Eout:
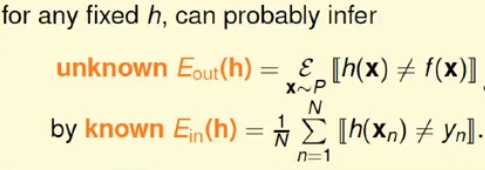
学习的PAC保证:
学习的PAC和罐子的PAC相同,只不过进行了变量的替换:

学习的PAC保证了在所有的数据都是来自于同一分布的情况下,Ein和Eout可以认为是差不多相等的,那么如果Ein很小Eout也就会很小;
上述中的预测函数都是说一个固定的函数满足上述的证明,但是在此过程中没有涉及的h(x)的选择还不能成为是learning,只能成为确认流程,就是选定h(x)后判断此函数的性能,(fixed)在这里不太明白,,对于学习的每一册选择完成后不就是一个fixed的函数了吗?这点很不明白
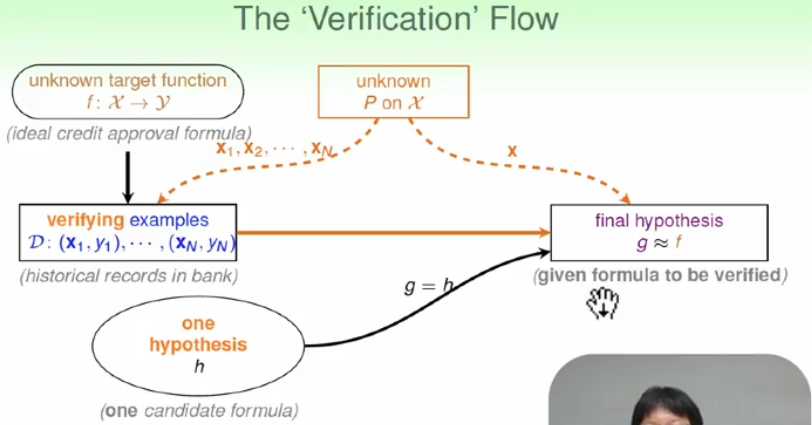
5、多个但有限hypthesis的情况分析
霍夫丁保证的是某个数据分布上多次抽样,在这个多次抽样中发生不好的抽样的次数很少

加入有多个h存在的情况下,会发生一下情况:
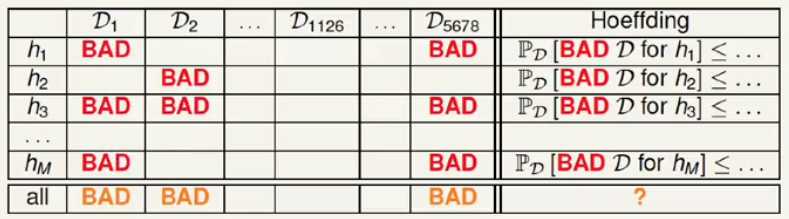
同一抽样样本,不同的h(x)的表现不同,有的是好的有的是不好的,那么对于每个h(x)霍夫丁总能保证发生不好的概率的抽样样本很少,但是一旦有选择使用某个抽样样本来说,只要多个h(x)中有一个不好的情况发生那么最后就不会得到很好的结果,因此某一样本发生不好的概率随着h(x)的数量的增加而迅速增加具体来说对于所有的h(x)来说霍夫丁不等式为:
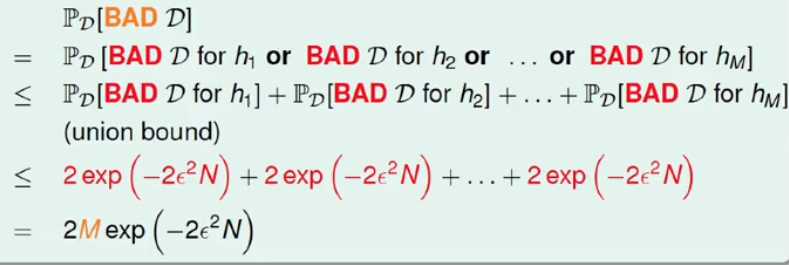
这就是对于有限hypothesis的情况下,发生bad data的概率上限,bad data 就是Eout很大但是Ein很小;
因此在有限个hypothesis的下,不好的数据发生的概率存在一个有限的上限值,因此使用PAC准则利用已知去推论未知数据;

总之,在多个但是有限的hypothesis的情况下,bad data发生的概率还是存在一个上限值,因此还是适用于霍夫丁不等式只是门限值变大了,因此还是可以选择学习;
机器什么时候可以学习(4) --- 学习的可能性(feasibility of learning)
标签:img 规模 性能 可能性 解释 上交 机器 image 颜色
原文地址:http://www.cnblogs.com/daguankele/p/6344859.html