标签:sum seconds pre producer zookeeper lol 执行 关闭 批处理
参考:
http://www.cnblogs.com/smartloli/p/4538173.html
http://blog.csdn.net/lsshlsw/article/details/47342821
虚拟机中共五个centos系统,每个系统有两个用户root和hadoop:cdh1,cdh2,cdh3,cdh4,cdh5
集群规划

安装kafka(cdh3机器)
第一步,解压已下载好的kafka安装包
#tar -zxvf kafka_2.9.2-0.8.2.2.tgz
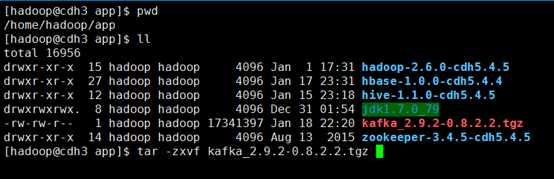
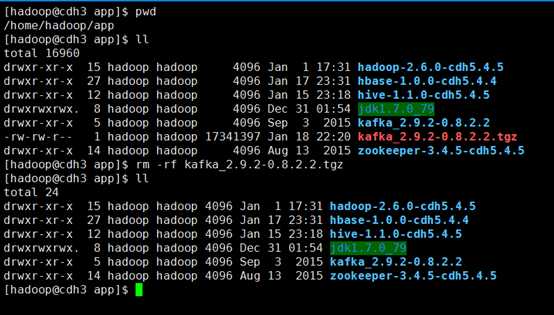
解压后删除kafka安装包,节省磁盘空间
#rm -rf kafka_2.9.2-0.8.2.2.tgz
第二步,root用户配置环境变量
#vi /etc/profile
添加以下配置
KAFKA_HOME=/home/hadoop/app/kafka_2.9.2-0.8.2.2 export PATH=$PATH:$KAFKA_HOME/bin

使环境变量及时生效
#source /etc/profile
第三步,配置zookeeper.properties
hadoop用户登录
#su hadoop
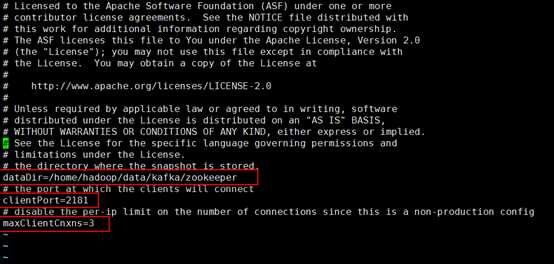
进入$KAFKA_HOME/config目录,配置zookeeper.properties文件
#vi zookeeper.properties
更改以下配置:
#用于存放zookeeper生成的数据文件,默认放在/tmp/zookeeper路径下
dataDir=/home/hadoop/data/kafka/zookeeper
#zookeeper监听的端口
clientPort=2181
#连接到 ZooKeeper 的客户端的数量,限制并发连接的数量,它通过 IP 来区分不同的客户端。此配置选项可以用来阻止某些类别的 Dos 攻击。将它设置为 0 或者忽略而不进行设置将会取消对并发连接的限制
maxClientCnxns=3
创建zookeeper生成的数据存放目录:
#mkdir –p /home/hadoop/data/kafka/zookeeper/

第四步,配置server.properties文件
进入$KAFKA_HOME/config目录,配置server.properties文件
更改以下配置
#zookeeper的ip和端口
zookeeper.connect=cdh3:2181,cdh4:2181,cdh5:2181
#broker存放数据文件的地方,默认在/tmp/kafka-logs/
log.dirs=/home/hadoop/data/kafka/kafka-logs
需要注意的是broker.id=0,broker的唯一标识,整数,配置broker的时候,每台机器上的broker保证唯一,从0开始。如:在另外2台机器上分别配置broker.id=1,broker.id=2



创建broker存放数据目录:
#mkdir -p /home/hadoop/data/kafka/kafka-logs/

第五步,配置producer.properties
# vi producer.properties
更改一下配置:
# broker的ip和端口
metadata.broker.list=cdh3:9092,cdh4:9092,cdh5:9092

第六步,配置consumer.properties
# vi consumer.properties
更改以下配置:
# zookeeper的ip和端口
zookeeper.connect=cdh3:2181,cdh4:2181,cdh5:2181

第七步,拷贝kafka数据目录/home/hadoop/data/kafka到其他节点
在cdh3的~/tools目录下执行deploy.sh批处理命令
# ./deploy.sh ~/data/kafka/ ~/data/ zookeeper

第七步,拷贝kafka安装文件到其他节点(cdh4,cdh5)
在cdh3的~/tools目录下执行deploy.sh批处理命令
# ./deploy.sh ~/app/kafka_2.9.2-0.8.2.2/ ~/app/ zookeeper

拷贝完成后,更改cdh4和cdh5两个节点中server.properties的属性:
cdh4 broker.id=1 cdh5 broker.id=2
第八步,其他节点的root用户配置环境变量(可以用批处理脚本,也可以每个节点手动配置)
#vi /etc/profile
添加以下配置
KAFKA_HOME=/home/hadoop/app/kafka_2.9.2-0.8.2.2 export PATH=$PATH:$KAFKA_HOME/bin

使环境变量及时生效
#source /etc/profile
第九步,启动kafka
启动zookeeper 进入cdh3节点的~/tools目录 #cd ~/tools/ #./runRemoteCmd.sh "~/app/zookeeper-3.4.5-cdh5.4.5/bin/zkServer.sh start" zookeeper 查看各节点进程,进入cdh3的~/tools目录下 #cd ~/tools/ #./runRemoteCmd.sh "jps" zookeeper
启动kafka
进入cdh3节点的~/tools目录
#cd ~/tools/ #启动cdh3,cdh4,cdh5三台虚拟机的kafka #./runRemoteCmd.sh " kafka-server-start.sh ~/app/kafka_2.9.2-0.8.2.2/config/server.properties" zookeeper 或者 #./runRemoteCmd.sh " kafka-server-start.sh ~/app/kafka_2.9.2-0.8.2.2/config/server.properties &" zookeeper

由上New leader is 0可以看出cdh3节点是主节点。
查看进程,进入cdh3的~/tools目录下
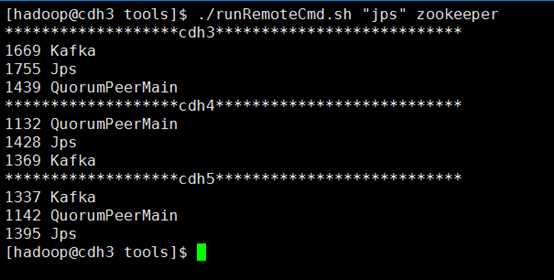
#cd ~/tools/ #./runRemoteCmd.sh "jps" zookeeper
第十步,创建Topic
#kafka-topics.sh --zookeeper cdh3:2181,cdh4:2181,cdh5:2181 --topic topic1 --replication-factor 3 --partitions 1 –create

查看Topic相关信息
#kafka-topics.sh --zookeeper cdh3:2181,cdh4:2181,cdh5:2181 --topic topic1 --describe

下面解释一下这些输出。第一行是对所有分区的一个描述,然后每个分区都会对应一行,因为我们只有一个分区所以下面就只加了一行。
Leader:负责处理消息的读和写,Leader是从所有节点中随机选择的。
Replicas:列出了所有的副本节点,不管节点是否在服务中。
Isr:是正在服务中的节点
第十一步,生产消息
下面我们使用kafka的Producer生产一些消息,然后让Kafka的Consumer去消费,命令如下所示:
#kafka-console-producer.sh --broker-list cdh3:9092,cdh4:9092,cdh5:9092 --topic topic1

第十二步,消费消息
在另外一个节点(如cdh4)启动消费进程,来消费这些消息,命令如下所示:
#kafka-console-consumer.sh --zookeeper cdh3:2181,cdh4:2181,cdh5:2181 --from-beginning --topic topic1

第十三步,测试kafka的HA高可用
杀掉leader节点cdh3的kafka服务
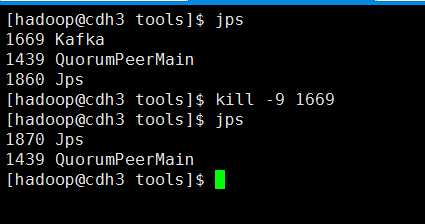
查看cdh5的kafka服务输出信息:

可以看出,leader切换为cdh5节点(broker.id=2),切换成功
第十四步,重新测试消息的生产和消费
生产消息
在kafka已经服务启动的节点下生产消息:
# kafka-console-producer.sh --broker-list cdh3:9092,cdh4:9092,cdh5:9092 --topic topic1

在其他节点(如cdh4)下消费消息:
# kafka-console-consumer.sh --zookeeper cdh3:2181,cdh4:2181,cdh5:2181 --from-beginning --topic topic1

总结
在部署Kafka Cluster的时候,有些地方需要我们注意,比如:在我们启动Kafka集群的时候,确保ZK集群启动,另外,在配置Kafka配置文件信息时,确保ZK的集群信息配置到相应的配置文件中,总体来说,配置还算较为简单,需要在部署的时候,仔细配置各个文件即可。
启动kafka的消息监控
第一步,将jar文件上传到虚拟机,如cdh3节点
第二步,编写jar文件的执行脚本
脚本如下:
nohup java -cp KafkaOffsetMonitor-assembly-0.2.0.jar com.quantifind.kafka.offsetapp.OffsetGetterWeb --zk cdh3:2181,cdh4:2181,cdh5:2181 --port 8089 --refresh 10.seconds --retain 1.days &
常用参数说明
–zk - Zookeeper hosts
–port - 启动webUI的端口号
–refresh - 页面数据刷新时间
–retain - 历史数据存放的时间(存放在SQLlite中)
#vi kafkaOffsetMonitor.sh
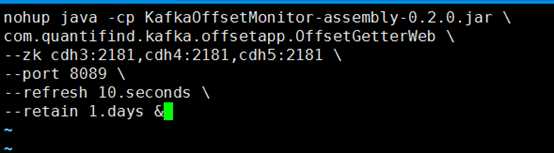

启动jar执行脚本
sh kafkaOffsetMonitor.sh
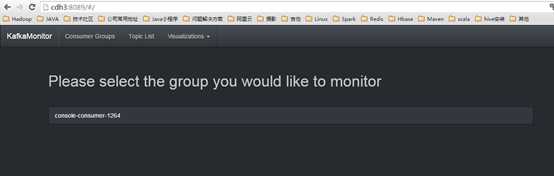
访问http://cdh3:8089监控页面
消费者组列表:
topic的所有partiton消费情况列表:
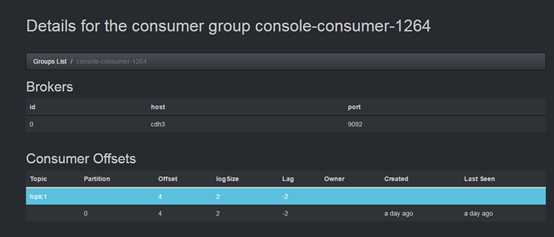
以上图中参数含义解释如下:
topic:创建时topic名称
partition:分区编号
offset:表示该parition已经消费了多少条message
logSize:表示该partition已经写了多少条message
Lag:表示有多少条message没有被消费。
Owner:表示消费者
Created:该partition创建时间
Last Seen:消费状态刷新最新时间。
kafka正在运行的topic:
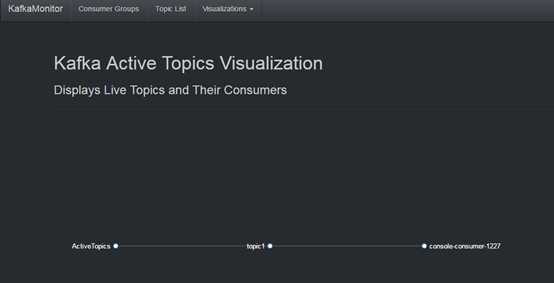
kafka集群中topic列表:
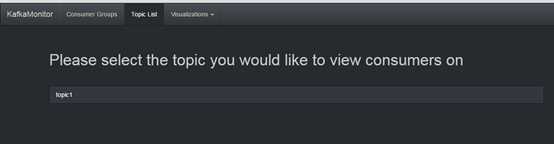
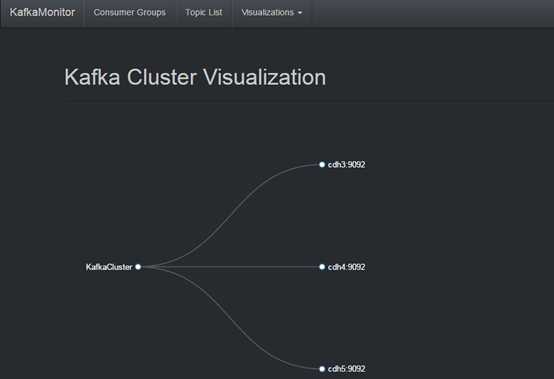
kafka集群中broker列表:
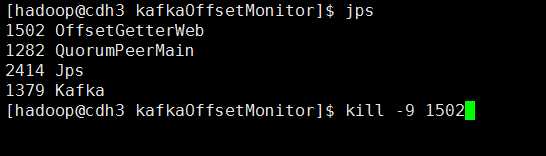
停止KafkaOffsetMonitor监控
#jps #kill -9 进程号
**********************关闭kafka*********************
关闭kafka 进入cdh3节点的~/tools目录 #cd ~/tools/ #关闭cdh3,cdh4,cdh5三台虚拟机的kafka #./runRemoteCmd.sh " kafka-server-stop.sh ~/app/kafka_2.9.2-0.8.2.2/config/server.properties" zookeeper 或者 #./runRemoteCmd.sh " kafka-server-stop.sh ~/app/kafka_2.9.2-0.8.2.2/config/server.properties &" zookeeper 查看进程,进入cdh3的~/tools目录下 #cd ~/tools/ #./runRemoteCmd.sh "jps" zookeeper 关闭zookeeper 进入cdh3节点的~/tools目录 #cd ~/tools/ #./runRemoteCmd.sh "~/app/zookeeper-3.4.5-cdh5.4.5/bin/zkServer.sh stop" zookeeper 查看进程,进入cdh3的~/tools目录下 #cd ~/tools/ #./runRemoteCmd.sh "jps" zookeeper
Kafka集群安装完成
完成!
Hadoop学习笔记-011-CentOS_6.5_64_HA高可用-Zookeeper3.4.5安装Kafka+消息监控KafkaOffsetMonitor
标签:sum seconds pre producer zookeeper lol 执行 关闭 批处理
原文地址:http://www.cnblogs.com/liudi1992/p/6346535.html