标签:链表 size 驱动 红色 web 成功 大量 用户空间 logs
首先来说一下进程:
进程在就是一段执行中的代码,他是由一条条指令和数据组成的一个具有生命周期的有头有尾的实体。
进程根据权限大体上可以分为两类:用户进程 和 内核进程。
这两者的主要区别在于权限不同。用户进程无法直接访问I/O设备,如果用户进程想要访问I/O设备,需要调用内核提供的接口,由内核进程对I/O设备进行操作,读取其中的数据到内核空间,然后将数据从内核空间移动到用户空间。
大体介绍完进程,我们来考虑这种情况:
我们可能有很多进程需要运行,假如我们只有一颗cpu,那么同一时刻只能有一个进程运行在cpu上,为了让人们产生多进程同时运行的错觉,内核被设计为这样:
1 每个用户进程仅仅被允许在cpu上运行一小段时间
2 当某个用户进程在cpu上的运行时间达到限定时间或者进程进入阻塞状态,内核就会负责将该进程的上下文环境保存(保存现场),然后根据链表的排序将下一个用户进程运行在cpu上,并恢复下一个进程的上下文环境(恢复现场)。 在这里我们可以看到内核的主要职责之一:进行进程调度切换或者说上下文切换
3 由于每个进程单次在cpu上运行的时间很短,并且进程切换也很快,这就给了我们多进程同时运行的错觉。
4 我们知道cpu的资源是有限的,如果内核占用cpu的时间百分比大,那么就说明用户进程占用cpu的时间小。换句话说如果我们有成千上万个用户进程需要运行,内核为了满足我们多进程同时运行的错觉,可能就需要缩短每个进程单次在cpu上的运行时间,然后疯狂的进行上下文切换。
5 我们的用户进程可能是web服务进程,数据库进程,负载均衡进程………… 总之:对于作为非内核开发的我们来说:我们所开发的所有进程都属于用户进程。
6 为了能更好的利用cpu资源,在保证系统稳定安全的前提下,我们需要尽可能的增加用户进程对cpu的时间占用比,也就是说尽可能的缩减内核对cpu的时间占用比(实际上在这里主要讨论如何减少上下文切换对cpu的占用)
7 那么问题来了:如何缩减内核对cpu的时间占用比?
使用线程,线程是更小的执行单位,线程比较之进程更加轻量级,也就是说,线程在进行上下文切换时消耗系统资源更少(这是理论上,因为各种原因可能导致相反的结果)。这样通过减少单次进程(线程)上下文切换的时间来降低内核对cpu的占用。(本文主要讲I/O多路复用,所以对线程不做过多讨论),
并且属于同一个进程的线程可以共享该进程的数据,这就使得多线程相较于多进程消耗的内存更少。当然这也是个问题:
因为共享数据就容易引起竞争,我们需要各种锁机制来确立进程内安定祥和的局面(最起码不能烽烟四起!)
而且,多线程相较于多进程来说不算稳定,一个线程崩毁容易引起进程的崩溃。
基于以上几点这个解决办法可以根据情况自行斟酌
I/O多路复用
说到I/O多路复用,我还是介绍一下UNIX下的I/O模型
1 对同步、异步术语的定义
在POSIX中:
同步:导致请求进程阻塞,直到I/O完成
异步:不导致请求进程阻塞。
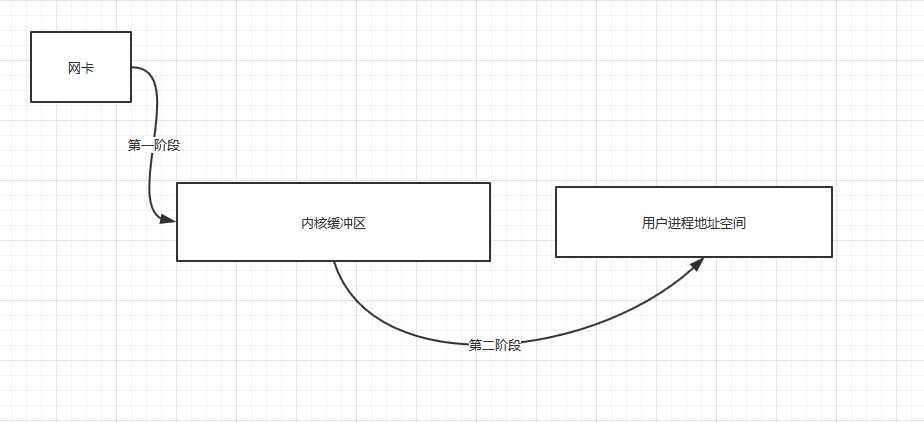
2 I/O的大体过程
用户进程读取I/O流需要两个阶段:
第一阶段: 将数据分组复制到内核空间
第二阶段: 将内核空间的相关数据复制到用户空间
3 五种I/O模型的解释
1 阻塞式I/O
默认情况下所有的套接字都是阻塞的(当然我们可以设置为非阻塞),当我们调用系统提供的接口访问套接字时,就会将进程阻塞。
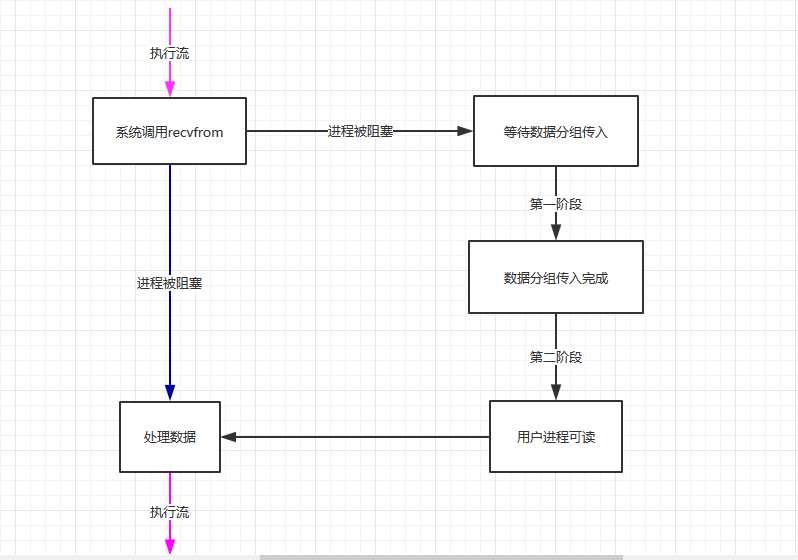
上图中,粉红色箭头表示进程处于running状态,也就是正在cpu上运行。而蓝色箭头表示进程处于sleep阻塞状态。(若无特殊说明,以下各图均为如此)
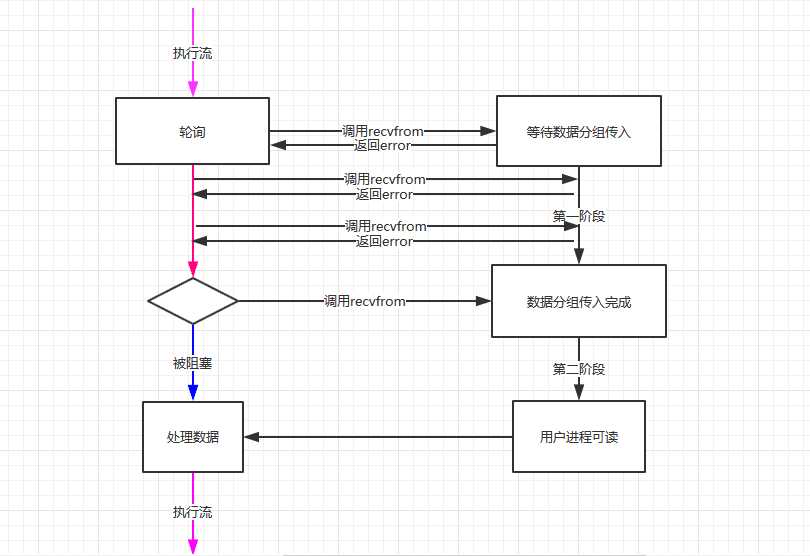
2 非阻塞式I/O
进程把一个套接字设置成非阻塞是在通知内核,当所请求的I/O操作非得把本进程投入睡眠才能完成时,不要把进程投入睡眠,而是返回一个错误。
但这就要求我们得不停的调用recvfrom函数,尝试读取socket中的数据,直到读取成功后,才继续处理接收的数据。整个IO请求的过程中,虽然用户线程每次发起IO请求后可以立即返回,但是为了等到数据,仍需要不断地轮询、重复请求,消耗了大量的CPU的资源。一般很少直接使用这种模型,而是在其他IO模型中使用非阻塞IO这一特性
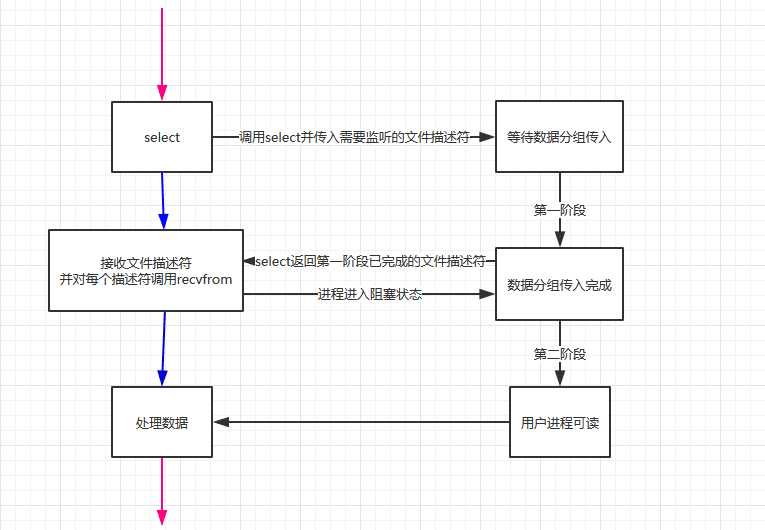
3 I/O多路复用
Linux中I/O多路复用的实现方式有三个,分别是select poll epoll 。这三个都可以监听许多文件描述符(在linux中套接字也是文件描述符),就会返回那些发生变化(可以理解为第一阶段完成)的文件描述符。
来看一下select的:
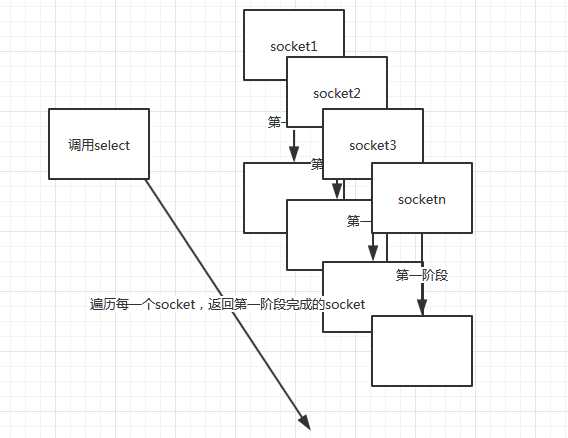
通过调用select(或者poll epoll),我们可以在一个进程(或者线程)中监控多个文件描述符,当某个文件描述符状态改变时,进程可以得到通知。
再来一张图片介绍一下这三者的不同:
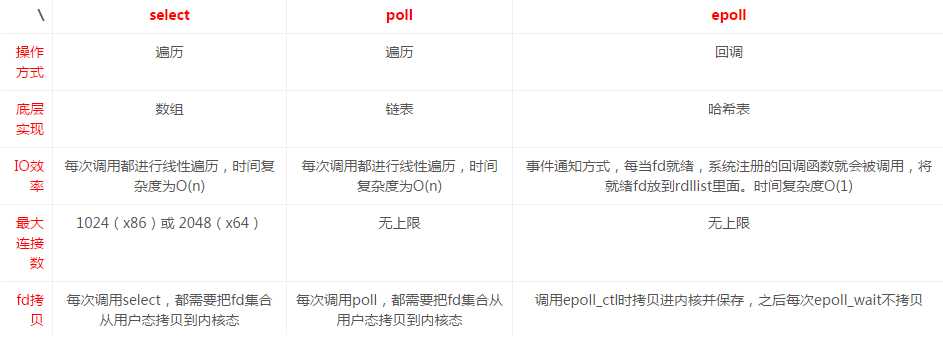
注:上图转载自https://pic1.zhimg.com/v2-e6a869884585625dfc7eace1b90c3024_r.png
4 信号驱动式I/O(本文不做讨论)
5 异步I/O
这类操作就是告知内核,等两个阶段操作都完成后再来通知我。
异步I/O需要调用操作系统提供的特殊API
Linux中为:AIO
windows: IOCP
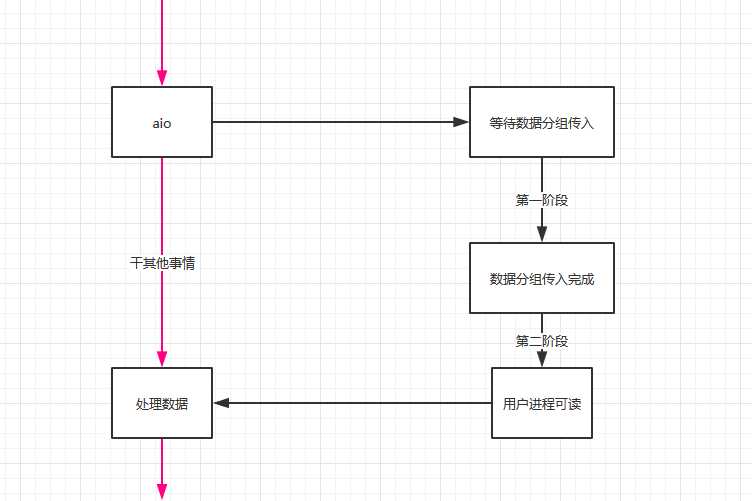
总结:阻塞式I/O(默认),非阻塞式I/O(nonblock),I/O复用(select/poll/epoll)都属于同步I/O,因为它们在数据由内核空间复制回进程缓冲区时都是阻塞的(不能干别的事)。只有异步I/O模型(AIO)是符合异步I/O操作的含义的
标签:链表 size 驱动 红色 web 成功 大量 用户空间 logs
原文地址:http://www.cnblogs.com/MnCu8261/p/6265972.html