标签:tmp .com hot query 版本 merge jdbc over 通过
安装hive
1、下载hive-2.1.1(搭配hadoop版本为2.7.3)
2、解压到文件夹下
/wdcloud/app/hive-2.1.1
3、配置环境变量
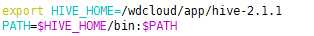
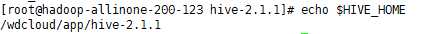
4、在mysql上创建元数据库hive_metastore编码选latin,并授权
grant all on hive_metastore.* to ‘root‘@‘%‘ IDENTIFIED BY ‘weidong‘ with grant option; flush privileges;
5、新建hive-site.xml,内容如下:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!--
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
--><configuration>
<!-- WARNING!!! This file is auto generated for documentation purposes ONLY! -->
<!-- WARNING!!! Any changes you make to this file will be ignored by Hive. -->
<!-- WARNING!!! You must make your changes in hive-site.xml instead. -->
<!-- Hive Execution Parameters -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.200.250:3306/hive_metastore?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>weidong</value>
</property>
<property>
<name>datanucleus.schema.autoCreateTables</name>
<value>true</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive/warehouse</value>
</property>
<property>
<name>hive.exec.scratchdir</name>
<value>/hive/warehouse</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/wdcloud/app/hive-2.1.1/logs</value>
</property>
<property>
<name>hive.aux.jars.path</name>
<value>/wdcloud/app/hbase-1.1.6/lib</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://192.168.200.123:9083</value>
</property>
</configuration>
6、hive-env.sh

7、放开日志
cp hive-log4j2.properties. template hive-log4j2.properties
cp hive-exec-log4j2.properties.template hive-exec-log4j2.properties
8、导入mysql connector jar包


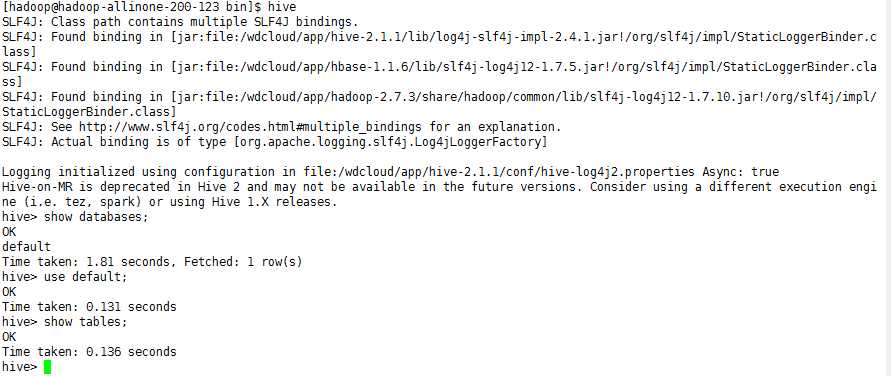
9、启动元数据库服务
hive --service metastore &
出错:
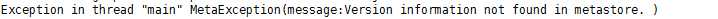

再次启动
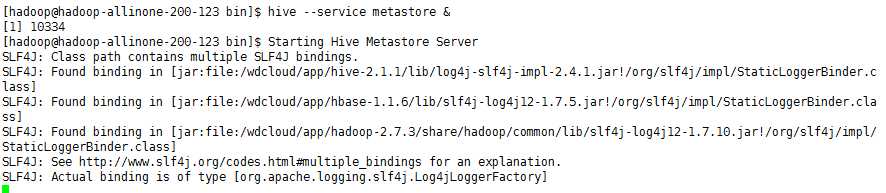
成功不报错
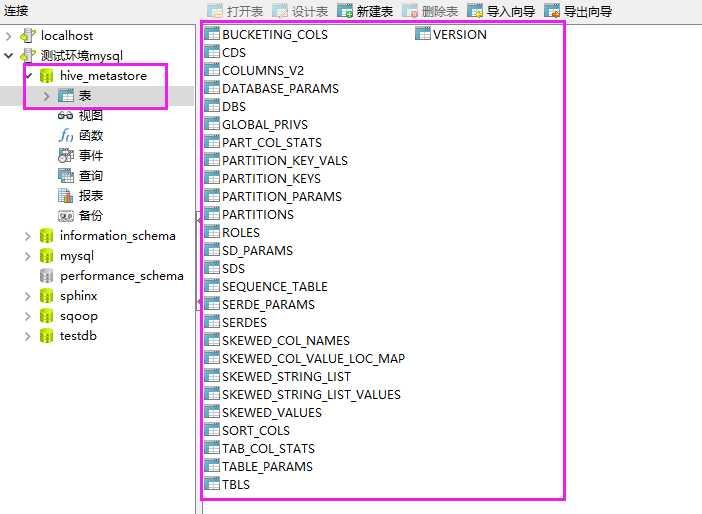
元数据库也生成了一些需要的表
调试 模式命令 hive -hiveconf hive.root.logger=DEBUG,console
客户端连接
OK,现在hive就安装完毕了,让我们来执行下将mysql数据通过sqoop导入hive
sqoop import --connect jdbc:mysql://192.168.200.250:3306/sqoop --table widgets_copy -m 1 --hive-import --username root -P
出错
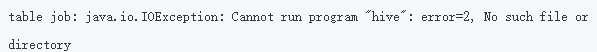
解决方法:

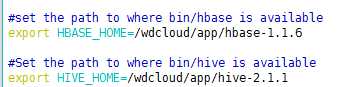
再次执行,导入成功,后台日志
[hadoop@hadoop-allinone-200-123 conf]$ sqoop import --connect jdbc:mysql://192.168.200.250:3306/sqoop --table widgets_copy -m 1 --hive-import --username root -P 17/01/24 03:42:48 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6 Enter password: 17/01/24 03:42:50 INFO tool.BaseSqoopTool: Using Hive-specific delimiters for output. You can override 17/01/24 03:42:50 INFO tool.BaseSqoopTool: delimiters with --fields-terminated-by, etc. 17/01/24 03:42:51 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. 17/01/24 03:42:51 INFO tool.CodeGenTool: Beginning code generation 17/01/24 03:42:51 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `widgets_copy` AS t LIMIT 1 17/01/24 03:42:52 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `widgets_copy` AS t LIMIT 1 17/01/24 03:42:52 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /wdcloud/app/hadoop-2.7.3 Note: /tmp/sqoop-hadoop/compile/4a89a67225918969c1c0f4c7c13168e9/widgets_copy.java uses or overrides a deprecated API. Note: Recompile with -Xlint:deprecation for details. 17/01/24 03:42:54 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-hadoop/compile/4a89a67225918969c1c0f4c7c13168e9/widgets_copy.jar 17/01/24 03:42:54 WARN manager.MySQLManager: It looks like you are importing from mysql. 17/01/24 03:42:54 WARN manager.MySQLManager: This transfer can be faster! Use the --direct 17/01/24 03:42:54 WARN manager.MySQLManager: option to exercise a MySQL-specific fast path. 17/01/24 03:42:54 INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql) 17/01/24 03:42:54 INFO mapreduce.ImportJobBase: Beginning import of widgets_copy 17/01/24 03:42:54 INFO Configuration.deprecation: mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/wdcloud/app/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/wdcloud/app/hbase-1.1.6/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] 17/01/24 03:42:55 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar 17/01/24 03:42:57 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps 17/01/24 03:42:57 INFO client.RMProxy: Connecting to ResourceManager at hadoop-allinone-200-123.wdcloud.locl/192.168.200.123:8032 17/01/24 03:43:01 INFO db.DBInputFormat: Using read commited transaction isolation 17/01/24 03:43:01 INFO mapreduce.JobSubmitter: number of splits:1 17/01/24 03:43:02 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1485230213604_0011 17/01/24 03:43:03 INFO impl.YarnClientImpl: Submitted application application_1485230213604_0011 17/01/24 03:43:03 INFO mapreduce.Job: The url to track the job: http://hadoop-allinone-200-123.wdcloud.locl:8088/proxy/application_1485230213604_0011/ 17/01/24 03:43:03 INFO mapreduce.Job: Running job: job_1485230213604_0011 17/01/24 03:43:16 INFO mapreduce.Job: Job job_1485230213604_0011 running in uber mode : false 17/01/24 03:43:16 INFO mapreduce.Job: map 0% reduce 0% 17/01/24 03:43:28 INFO mapreduce.Job: map 100% reduce 0% 17/01/24 03:43:28 INFO mapreduce.Job: Job job_1485230213604_0011 completed successfully 17/01/24 03:43:28 INFO mapreduce.Job: Counters: 30 File System Counters FILE: Number of bytes read=0 FILE: Number of bytes written=138211 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=87 HDFS: Number of bytes written=169 HDFS: Number of read operations=4 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Other local map tasks=1 Total time spent by all maps in occupied slots (ms)=8081 Total time spent by all reduces in occupied slots (ms)=0 Total time spent by all map tasks (ms)=8081 Total vcore-milliseconds taken by all map tasks=8081 Total megabyte-milliseconds taken by all map tasks=8274944 Map-Reduce Framework Map input records=4 Map output records=4 Input split bytes=87 Spilled Records=0 Failed Shuffles=0 Merged Map outputs=0 GC time elapsed (ms)=117 CPU time spent (ms)=2630 Physical memory (bytes) snapshot=178216960 Virtual memory (bytes) snapshot=2903285760 Total committed heap usage (bytes)=155713536 File Input Format Counters Bytes Read=0 File Output Format Counters Bytes Written=169 17/01/24 03:43:28 INFO mapreduce.ImportJobBase: Transferred 169 bytes in 31.7543 seconds (5.3221 bytes/sec) 17/01/24 03:43:28 INFO mapreduce.ImportJobBase: Retrieved 4 records. 17/01/24 03:43:28 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `widgets_copy` AS t LIMIT 1 17/01/24 03:43:29 WARN hive.TableDefWriter: Column price had to be cast to a less precise type in Hive 17/01/24 03:43:29 WARN hive.TableDefWriter: Column design_date had to be cast to a less precise type in Hive 17/01/24 03:43:29 INFO hive.HiveImport: Loading uploaded data into Hive(将生成在HDFS的数据加载到HIVE中) 17/01/24 03:43:41 INFO hive.HiveImport: SLF4J: Class path contains multiple SLF4J bindings. 17/01/24 03:43:41 INFO hive.HiveImport: SLF4J: Found binding in [jar:file:/wdcloud/app/hive-2.1.1/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] 17/01/24 03:43:41 INFO hive.HiveImport: SLF4J: Found binding in [jar:file:/wdcloud/app/hbase-1.1.6/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] 17/01/24 03:43:41 INFO hive.HiveImport: SLF4J: Found binding in [jar:file:/wdcloud/app/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] 17/01/24 03:43:41 INFO hive.HiveImport: SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. 17/01/24 03:43:41 INFO hive.HiveImport: SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] 17/01/24 03:43:42 INFO hive.HiveImport: 17/01/24 03:43:42 INFO hive.HiveImport: Logging initialized using configuration in file:/wdcloud/app/hive-2.1.1/conf/hive-log4j2.properties Async: true 17/01/24 03:43:55 INFO hive.HiveImport: OK 17/01/24 03:43:55 INFO hive.HiveImport: Time taken: 3.687 seconds 17/01/24 03:43:55 INFO hive.HiveImport: Loading data to table default.widgets_copy 17/01/24 03:43:56 INFO hive.HiveImport: OK 17/01/24 03:43:56 INFO hive.HiveImport: Time taken: 1.92 seconds 17/01/24 03:43:57 INFO hive.HiveImport: Hive import complete. 17/01/24 03:43:57 INFO hive.HiveImport: Export directory is contains the _SUCCESS file only, removing the directory.(加载进Hive成功后将HDFS上的中间数据删除掉)
如果曾经执行失败过,那再执行的时候,会有错误提示:
ERROR tool.ImportTool: Encountered IOException running import job: org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory xxx already exists
这时,执行hadoop fs -rmr xxx 即可
或者在命令行加上参数
--hive-overwrite : Overwrite existing data inthe Hive table
这个参数会自动覆盖掉曾经存在与hive表的数据
这样即使失败了也会自动去覆盖
查看导入数据
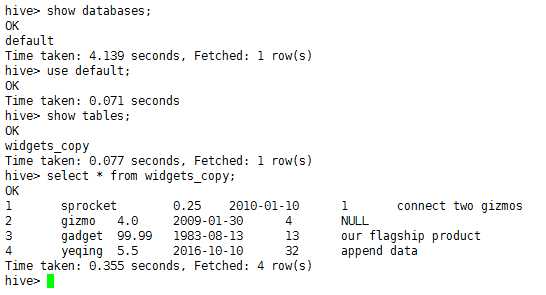
拓展: Sqoop-1.4.4工具import和export使用详解
http://blog.csdn.net/wangmuming/article/details/25303831
附上最后的配置文件hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Licensed to the Apache Software Foundation (ASF) under one or more contributor license agreements. See the NOTICE file distributed with this work for additional information regarding copyright ownership. The ASF licenses this file to You under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. --><configuration> <!-- WARNING!!! This file is auto generated for documentation purposes ONLY! --> <!-- WARNING!!! Any changes you make to this file will be ignored by Hive. --> <!-- WARNING!!! You must make your changes in hive-site.xml instead. --> <!-- Hive Execution Parameters --> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://192.168.200.250:3306/hive_metastore?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>weidong</value> </property> <property> <name>datanucleus.schema.autoCreateTables</name> <value>true</value> </property> <property> <name>hive.metastore.warehouse.dir</name> <value>/hive/warehouse</value> </property> <property> <name>hive.exec.scratchdir</name> <value>/hive/warehouse</value> </property> <property> <name>hive.querylog.location</name> <value>/wdcloud/app/hive-2.1.1/logs</value> </property> <property> <name>hive.aux.jars.path</name> <value>/wdcloud/app/hbase-1.1.6/lib</value> </property> <property> <name>hive.metastore.uris</name> <value>thrift://192.168.200.123:9083</value> </property> <property> <name>hive.metastore.schema.verification</name> <value>false</value> </property> </configuration>
[hadoop读书笔记] 第十五章 sqoop1.4.6小实验 - 将mysq数据导入hive
标签:tmp .com hot query 版本 merge jdbc over 通过
原文地址:http://www.cnblogs.com/avivaye/p/6347492.html