标签:mapr margin 工作 需要 输出 track sort text partition
MapReduce 是一个分布式计算框架,主要由两部分组成:编程模型和运行时环境.
其中,编程模型为用户提供了非常易用的编程接口,用户只需要像编写串行程序一样实现几个简单的函数即可实现一个分布式程序,而其他比较复杂的工作,如节点间的通信、节点失效、数据切分等,全部由MapReduce 运行时环境完成,用户无须关心这些细节。
编程模型:
????它的基本编程模型是将问题抽象成Map 和Reduce 两个阶段。其中,Map 阶段将输入数据解析成key/value,迭代调用map() 函数处理后,再以key/value 的形式输出到本地目录;Reduce 阶段则将key 相同的value 进行规约处理,并将最终结果写到HDFS 上。
map() 函数以key/value 对作为输入,产生另外一系列key/value 对作为中间输出写入本地
磁盘。MapReduce 框架会自动将这些中间数据按照key 值进行聚集,且key 值相同(用户可
设定聚集策略,默认情况下是对key 值进行哈希取模)的数据被统一交给reduce() 函数处理。
reduce() 函数以key 及对应的value 列表作为输入,经合并key 相同的value 值后,产
生另外一系列key/value 对作为最终输出写入HDFS。
运行时环境:
????它的运行时环境由两类服务组成:JobTracker 和TaskTracker,其中,JobTracker 负责资源管理和所有作业的控制,而TaskTracker 负责接收来自JobTracker 的命令并执行它。
?
五个编程组件:
InputFormat、
Mapper、
Partitioner、
Reducer 、
OutputFormat
Block 与 split的关系:
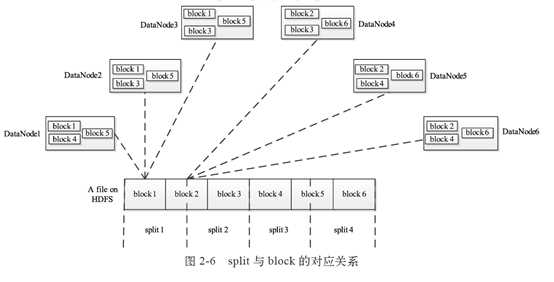
?
Map Task 执行过程:
Map Task 先将对应的split 迭代解析成一个个key/value 对,依次调用用户自定义的map() 函数进行处理,最终将临时结果存放到本地磁盘上,其中临时数据被分成若干个partition,每个partition 将被一个Reduce Task 处理。
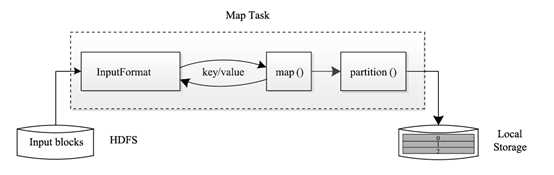
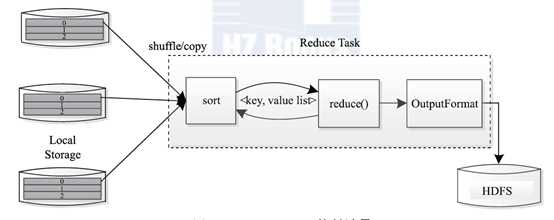
Reduce Task的执行过程:
该过程分为三个阶段①从远程节点上读取MapTask 中间结果(称为"Shuffle 阶段");②按照key 对key/value 对进行排序(称为"Sort 阶段");③依次读取<key, value list>,调用用户自定义的reduce() 函数处理,并将最终结果存到HDFS 上(称为"Reduce 阶段")。
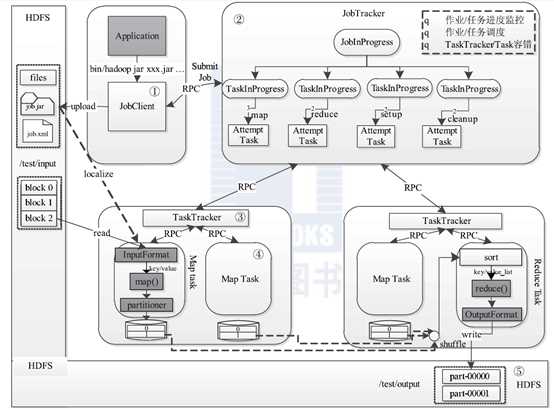
Hadoop MR作业的生命周期:
这个过程分为以下5 个步骤:
步骤1 作业提交与初始化
步骤2 任务调度与监控。
步骤3 任务运行环境准备。
步骤4 任务执行。
步骤5 作业完成。
?
分布式编程的方法:
适应的场景:
任务可被分解成相互独立的子问题
MapReduce 编程模型给出了其分布式编程方法,共分5 个步骤:
1)迭代(iteration)。遍历输入数据,并将之解析成key/value 对。
2)将输入key/value 对映射(map)成另外一些key/value 对。
3)依据key 对中间数据进行分组(grouping)。
4)以组为单位对数据进行归约(reduce)。
5)迭代。将最终产生的key/value 对保存到输出文件中。
MapReduce 将计算过程分解成以上5 个步骤带来的最大好处是组件化与并行化。
?
?
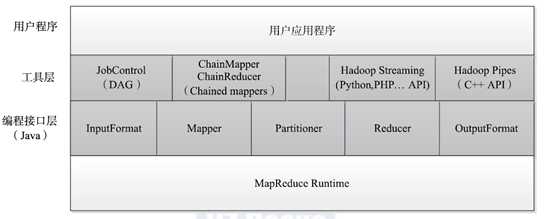
流式访问、有向图式访问、链式MapperReduce访问、
标签:mapr margin 工作 需要 输出 track sort text partition
原文地址:http://www.cnblogs.com/joqk/p/6347543.html