标签:编译器 情况 处理 内存地址 分享 改变 用法 调整 尺寸
数据对齐,是指数据所在的内存地址必须是该数据长度的整数倍。DWORD数据的内存起始地址能被4除尽,WORD数
据的内存起始地址能被2除尽。x86 CPU能直接访问对齐的数据,当它试图访问一个未对齐的数据时,会在内部进行一系列
的调整。这些调整对于程序来说是透明的,但是会降低运行速度,所以编译器在编译程序时会尽量保证数据对齐。同样一
段代码,我们来看看用VC、Dev C++和LCC这3个不同的编译器编译出来的程序的执行结果:

这是用VC编译后的执行结果:

变量在内存中的顺序:b(1字节)—a(4字节)—c(4字节)。
这是用Dev C++编译后的执行结果:
变量在内存中的顺序:c(4字节)—中间相隔3字节—b(占1字节)—a(4字节)。
这是用LCC编译后的执行结果:

变量在内存中的顺序:同上。
3个编译器都做到了数据对齐,但是后两个编译器显然没VC“聪明”,让一个char占了4字节,浪费内存。
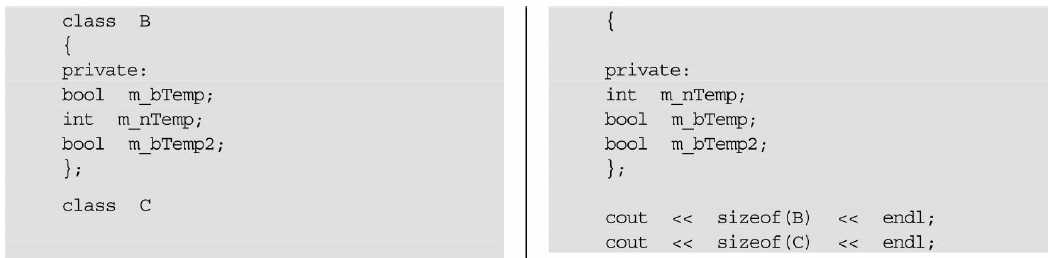
以下代码为32位机器编译,数据是以4字节为对齐单位,这两个类的输出结果
为什么不同?[中国著名软件企业JS公司2008年4月面试题]
解析:在访问内存时,如果地址按4字节对齐,则访问效率会高很多。这种现象的原因
在于访问内存的硬件电路。一般情况下,地址总线总是按照对齐后的地址来访问的。例如你
想得到0x00000001开始的4字节内容,系统首先需要以0x00000000读4字节,从中取得3字
节,然后再用0x00000004作为开始地址,获得下一个4字节,再从中得到第一个字节,两次
组合出你想得到的内容。但是如果地址一开始就是对齐到0x00000000,则系统只要一次读写
即可。
考虑到性能方面,编译器会对结构进行对齐处理。考虑下面的结构:

直观地讲,这个结构的尺寸是sizeof(char)+sizeof(int)=6,但是在实际编译下,这个结构
尺寸默认是8,因为第二个域iValue会被对齐到第4个字节。
在VC中,我们可以用pack预处理指令来禁止对齐调整。例如,下面的代码将使得结构尺
寸更加紧凑,不会出现对齐到4字节问题:
对于这个pack指令的含义,大家可以查询MSDN。请注意,除非你觉得必须,否则不要
轻易做这样的调整,因为这将降低程序的性能。目前比较常见的用法有两种,一是这个结构
需要被直接写入文件;二是这个结构需要通过网络传给其他程序。
注意:字节对齐是编译时决定的,一旦决定则不会再改变,因此即使有对齐的因素在,
也不会出现一个结构在运行时尺寸发生变化的情况。
在本题中,第一种类的数据对齐是下面的情况:

第二种类的数据对齐是下面的情况:
答案:B类输出12字节,C类输出8字节。
求解下面程序的结果。[中国著名通信企业H公司面试题]

解析:因为静态变量是存放在全局数据区的,而sizeof计算栈中分配的大小,是不会计
算在内的,所以sizeof(A1)是4。
● 为了照顾数据对齐,int大小为4,char大小为1,所以sizeof(A2)是8。
● 为了照顾数据对齐,float大小为4,char大小为1,所以sizeof(A3)是8。
● 为了照顾数据对齐,float大小为4,int大小为4,char大小为1,所以sizeof(A3)是12。
● 为了照顾数据对齐,double大小为8,float大小为4,int大小为4,char大小为1,所以
sizeof(A3)是24。
答案:4,8,8,12,24。
标签:编译器 情况 处理 内存地址 分享 改变 用法 调整 尺寸
原文地址:http://www.cnblogs.com/yihujiu/p/6367131.html