标签:treeset eset err collect 成功 存在 其他 现实生活 ring
import java.util.HashSet; import javax.print.attribute.HashAttributeSet; /* 集合 的体系: ------------| Collection 单例集合的根接口 ----------------| List 如果是实现了List接口的集合类,具备的特点: 有序,可重复。 -------------------| ArrayList ArrayList 底层是维护了一个Object数组实现的。 特点: 查询速度快,增删慢。 -------------------| LinkedList LinkedList 底层是使用了链表数据结构实现的, 特点: 查询速度慢,增删快。 -------------------| Vector(了解即可) 底层也是维护了一个Object的数组实现的,实现与ArrayList是一样的,但是Vector是线程安全的,操作效率低。 ----------------| Set 如果是实现了Set接口的集合类,具备的特点: 无序,不可重复。 -------------------| HashSet 底层是使用了哈希表来支持的,特点: 存取速度快.
无序: 添加元素的顺序与元素出来的顺序是不一致的。
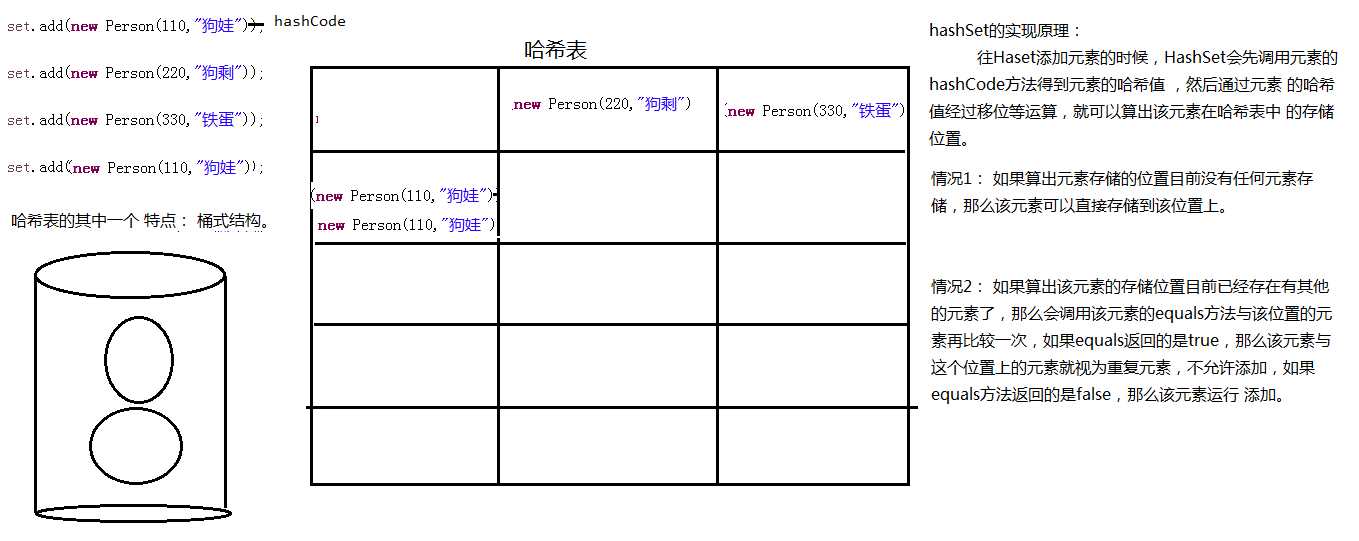
hashSet的实现原理: 往Haset添加元素的时候,HashSet会先调用元素的hashCode方法得到元素的哈希值 , 然后通过元素 的哈希值经过移位等运算,就可以算出该元素在哈希表中 的存储位置。 情况1: 如果算出元素存储的位置目前没有任何元素存储,那么该元素可以直接存储到该位置上。 情况2: 如果算出该元素的存储位置目前已经存在有其他的元素了,那么会调用该元素的equals方法与该位置的元素再比较一次 ,如果equals返回的是true,那么该元素与这个位置上的元素就视为重复元素,不允许添加,如果equals方法返回的是false,那么该元素运行 添加。 -------------------| TreeSet */ class Person{ int id; String name; public Person(int id, String name) { super(); this.id = id; this.name = name; } @Override public String toString() { return "{ 编号:"+ this.id+" 姓名:"+ this.name+"}"; } @Override public int hashCode() { System.out.println("=======hashCode====="); return this.id; } @Override public boolean equals(Object obj) { System.out.println("======equals======"); Person p = (Person)obj; return this.id==p.id; } } public class Demo2 { public static void main(String[] args) { /* HashSet set = new HashSet(); set.add("狗娃"); set.add("狗剩"); set.add("铁蛋"); System.out.println("集合的元素:"+ set); */ HashSet set = new HashSet(); set.add(new Person(110,"狗娃")); set.add(new Person(220,"狗剩")); set.add(new Person(330,"铁蛋")); //在现实生活中只要编号一致就为同一个人. System.out.println("添加成功吗?"+set.add(new Person(110,"狗娃"))); System.out.println("集合的元素:"+set); } }
标签:treeset eset err collect 成功 存在 其他 现实生活 ring
原文地址:http://www.cnblogs.com/xufengyuan/p/6368763.html