标签:throw tutorial bsp add xxx 信息 net boolean 2.x
(一)
本章打算研究一下爬虫。我想用爬虫简单的爬取几篇文章,以及收集一下常用网站的信息。
(二)
以开源项目 JAVA爬虫 WebCollector 为源码研究。在此基础上改为适合自己项目的代码。
(三)
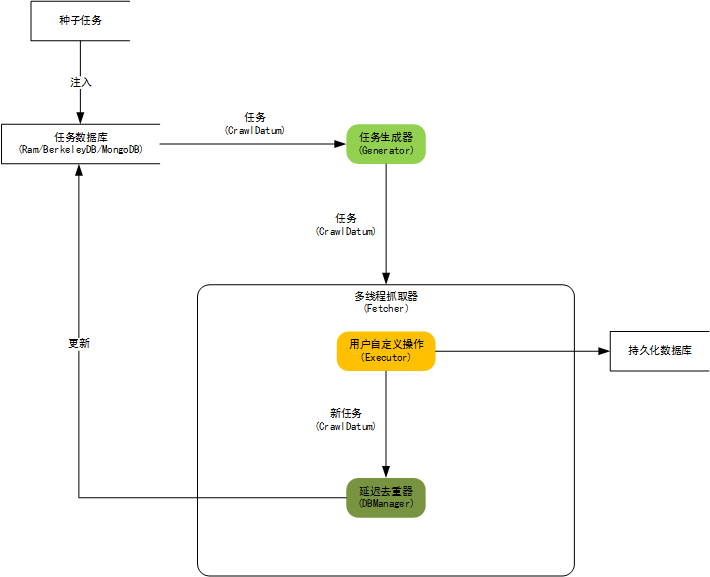
WebCollector致力于维护一个稳定、可扩的爬虫内核,便于开发者进行灵活的二次开发。内核具有很强的扩展性,用户可以在内核基础上开发自己想要的爬虫。源码中集成了Jsoup,可进行精准的网页解析。
内核构架图:
WebCollector的正文抽取API都被封装为ContentExtractor类的静态方法。 可以抽取结构化新闻,也可以只抽取网页的正文(或正文所在Element)。
标题抽取和日期抽取使用简单启发式算法,并没有像正文抽取算法一样在标准数据集上测试,算法仍在更新中。
WebCollector 2.x版本特性:
(四)
该源码的使用方法仅需按照其示例 TutorialCrawler 写即可。比如,类似如下自定义方法:
package com.panie.modules.crawl.webcollector.example; import org.jsoup.nodes.Document; import com.panie.modules.crawl.webcollector.model.CrawlDatums; import com.panie.modules.crawl.webcollector.model.Page; import com.panie.modules.crawl.webcollector.plugin.berkeley.BreadthCrawler; public class NewsCrawler extends BreadthCrawler { public NewsCrawler(String crawlPath, boolean autoParse) { super(crawlPath, autoParse); /*start page*/ this.addSeed("http://news.hfut.edu.cn/list-1-1.html"); /*fetch url like http://news.hfut.edu.cn/show-xxxxxxhtml*/ this.addRegex("http://news.hfut.edu.cn/show-.*html"); /*do not fetch jpg|png|gif*/ this.addRegex("-.*\\.(jpg|png|gif).*"); /*do not fetch url contains #*/ this.addRegex("-.*#.*"); } @Override public void visit(Page page, CrawlDatums next) { String url = page.getUrl(); /*if page is news page*/ if (page.matchUrl("http://news.hfut.edu.cn/show-.*html")) { /*we use jsoup to parse page*/ Document doc = page.getDoc(); /*extract title and content of news by css selector*/ String title = page.select("div[id=Article]>h2").first().text(); String content = page.select("div#artibody", 0).text(); System.out.println("URL:\n" + url); System.out.println("title:\n" + title); System.out.println("content:\n" + content); /*If you want to add urls to crawl,add them to nextLink*/ /*WebCollector automatically filters links that have been fetched before*/ /*If autoParse is true and the link you add to nextLinks does not match the regex rules,the link will also been filtered.*/ //next.add("http://xxxxxx.com"); } } public static void main(String[] args) throws Exception { NewsCrawler crawler = new NewsCrawler("crawl", true); //crawler.addSeed("http://news.hfut.edu.cn/.*"); crawler.setThreads(50); crawler.setTopN(100); //crawler.setResumable(true); /*start crawl with depth of 4*/ crawler.start(4); } }
根据实际需要将 visit 方法 自定义相关内容
com.panie 项目开发随笔_爬虫初识(2017.2.7)
标签:throw tutorial bsp add xxx 信息 net boolean 2.x
原文地址:http://www.cnblogs.com/panie2015/p/6375317.html