标签:开发 pen 循环 问题 能力 它的 数据类型 自己的 比较
进行SIMD多媒体扩展的设计,源于一个很容易观察到的事实:
许多多媒体应用程序操作的数据类型比对32位处理器进行针对性优化的数据类型更窄一些。
图像三基色,都是8位。音频采样也都是8位和16位来表示。
SIMD的多媒体扩展指令与标准的SIMD指令相比,它指定的操作数更少,因此使用的寄存器堆更小。
SIMD扩展主要对一下三项进行了简化:
1)多媒体SIMD扩展固定了操作代码中数据操作数的数目,从而在x86的体系结构的MMX,SSE,AVX中添加了数百条指令。
2)多媒体SIMD没有提供向量体系结构的更复杂的寻址模式,也就是步幅访问和集中---分散访问。
3)多媒体SIMD不像向量体系结构那样,为了支持元素的条件执行而提供遮罩寄存器。
做这些扩展指令的目的也是加快那些精心编制的库函数的运行速度,而不是由编译器来生成的这些库。
SIMD的优点:
1)芯片设计相对向量体系结构来说,较简单,且不需要那么大的存储器带宽。
2)可以比较轻松的引入一些符合新媒体标准的指令。
GPU的祖先是图形加速器,极强的图形处理能力是GPU得以存在的原因。当前GPU的研究热点是一种简化的GPU编程的编程语言。
GPU几乎拥有所有可以由编程环境捕获的并行类型:多线程,MIMD,SIMD,指令级并行
NVIDA开发的是一种类似于C的语言和编程环境,通过克服多种并行的挑战来提高GPU程序员的生产效率。这一系统称为CUDA。
将所有的这些并行形式统一为CUDA线程,以这种最低级的并行作为编程原型。
编译器和硬件可以将数以千计的CUDA线程聚合在一起。CUDA编程模型被定义为"单指令多线程(SIMT)"
执行时,以32个线程为一组,称为线程块,将执行整个线程块的硬件称为多线程SIMD处理器。
行执行和线程管理由GPU硬件负责,而不是由应用程序或操作系统完成,不同的线程块之间可以使用全局存储的原子操作来进行协调,
但是它们之间不能直接通信。
和很多并行系统一样,CUDA在生产效率和性能之间进行了一点折中,提供了一些本身固有的功能,让程序员能够显示控制硬件。
了解编程语言可以平衡生产效率和性能之间的关系。
AMD推出的与供应商无关的语言,OpenCL。
以NVIDIA系统为例,GPU可以很好的解决数据级并行的问题,也拥有着集中---分散数据传送和遮罩寄存器,但是GPU的寄存器要比
向量处理器更多。有一些功能,GPU通过硬件来实现,在向量体系结构中通过软件来实现。
网格是在GPU上运行,由一组线程块构成的代码。例如我们希望两个向量乘在一起,每个向量长度为8192个元素。执行所有8192个
元素乘法的GPU代码称为网格(向量化循环)
为了便于管理,网格可以由线程块(向量化循环体)组成。每个线程块最多512个元素。一条SIMD指令一次执行32个元素。所以该例子
中,共有16个线程块
网格和线程块是GPU硬件中实现的编程抽象,可以帮助程序员组织自己的CUDA代码。
线程块调度程序是将线程块指定给执行该代码的处理器,我们将这种处理器称为多线程SIMD处理器。
线程块调度程序与向量体系结构中的控制处理器类似。决定了该循环所需要的线程块数,以及将他们分配给不同的多线程SIMD处理器。
SIMD多线程处理器与向量处理器类似。但是它的很多功能单元都是深度流水化的。
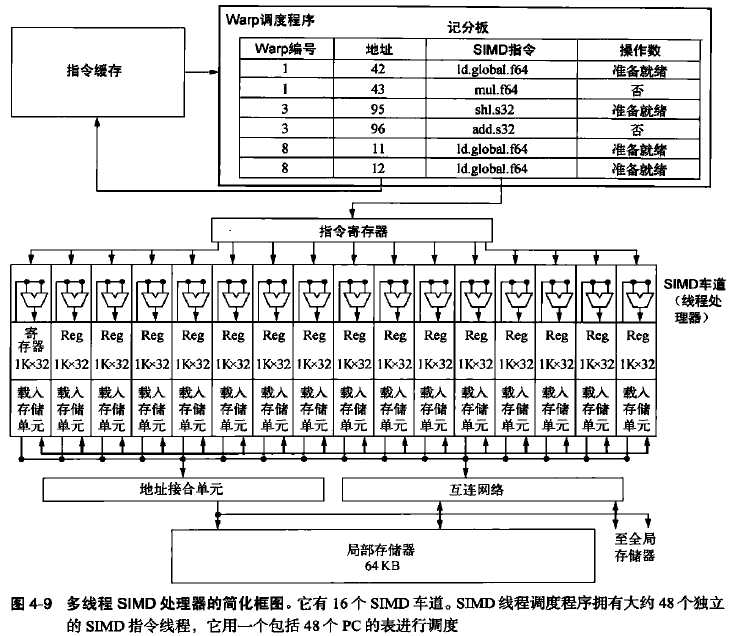
GPU是一个由多线程SIMD处理器组成的多处理器,加自己的线程块调度程度。
标签:开发 pen 循环 问题 能力 它的 数据类型 自己的 比较
原文地址:http://www.cnblogs.com/-9-8/p/6382978.html