标签:href 第一个 png images 空格 ++ 日志文件 内置变量 pap
awk:
强大的文本处理工具,擅长对日志文件进行分析;
不仅用于Linux,也是任何环境中现在的功能最强大的数据处理引擎;
语法说明:
awk ‘{pattern + action}‘ {filenames}
pattern:指在数据中要查找的内容;
action:指要操作的指令。
{}可以对一系列指令进行分组,不一定要出现。pattern要表达的正则表达式要用斜杠括起来。
通常,awk是以文件的一行为处理单位,每接收一行就执行相应的命令。
三种调用方法:
awk [-F field-separator] ‘commands‘ input-files
field-separator:域分隔符,指文件每一行中每个域分隔的符号,默认为空格。
将所有awk命令插入到一个文件,并使awk程序可执行,awk命令解释器作为脚本的首行。
#!/bin/awk
awk –f script-file input-files
-f选项加载script-file中的awk脚本。
awk执行流程:
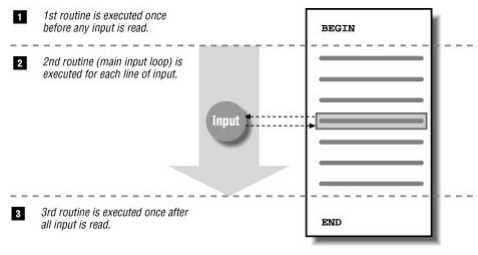
示例:
意思:显示access.201204文件的每一行中的第一个$1数据,$1为每一行中空格相隔的第一个字串,$2为第二个字串,以此类推。
如果将print $1保存在文件内,假设保存为test1,则可以写成:awk –f test1 access.201204
意思:$1字串匹配sina字符串时,则执行print $1。
意思:将每行$1作为ip数组下标,进行重复计数统计,完后再循环ip数组,显示下标和统计结果,并按降序排列。
内置变量:
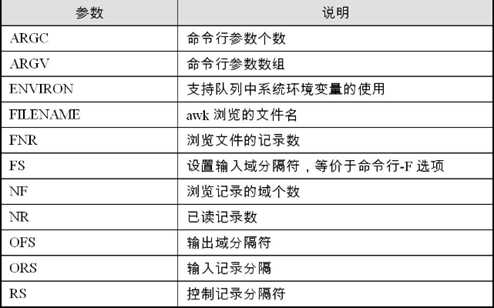
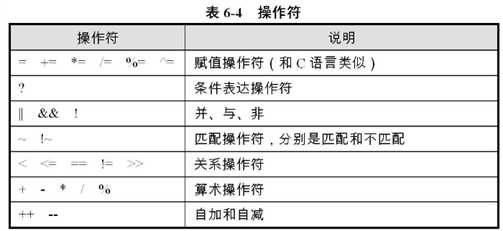
操作符:
常用的字符串函数:
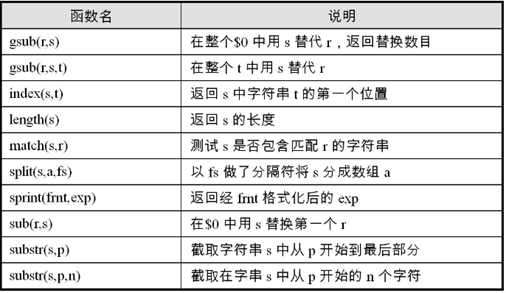
控制流和循环:

数组输出:

参考笔记:
http://linux.vbird.org/somepaper/20090427-learn_sed_and_awk.pdf
标签:href 第一个 png images 空格 ++ 日志文件 内置变量 pap
原文地址:http://www.cnblogs.com/xiwang6428/p/6389331.html