标签:ural 中比 解决 sed com strong mode ica 比较
摘要:本文提出了一种 DRL 算法进行单目标跟踪,算是单目标跟踪中比较早的应用强化学习算法的一个工作。
在基于深度学习的方法中,想学习一个较好的 robust spatial and temporal representation for continuous video data 是非常困难的。
尽管最近的 CNN based tracker 也取得了不错的效果,但是,其性能局限于:
1. Learning robust tracking features ;
2. maximizing long-term tracking performance ---->>> without taking coherency and correlation into account.
本文的创新点在于:
1. 提出一种 convolutional recurrent neural network model, 可以学习到单帧图像的空间表示 以及 多帧图像之间的时序上的表示;
得到的特征可以更好的捕获 temporal information,并且可以直接应用到跟踪问题上;
2. 我们的框架是端到端的进行训练的 deep RL algorithm,模型的目标是最大化跟踪性能;
3. 模型完全是 off-line的;
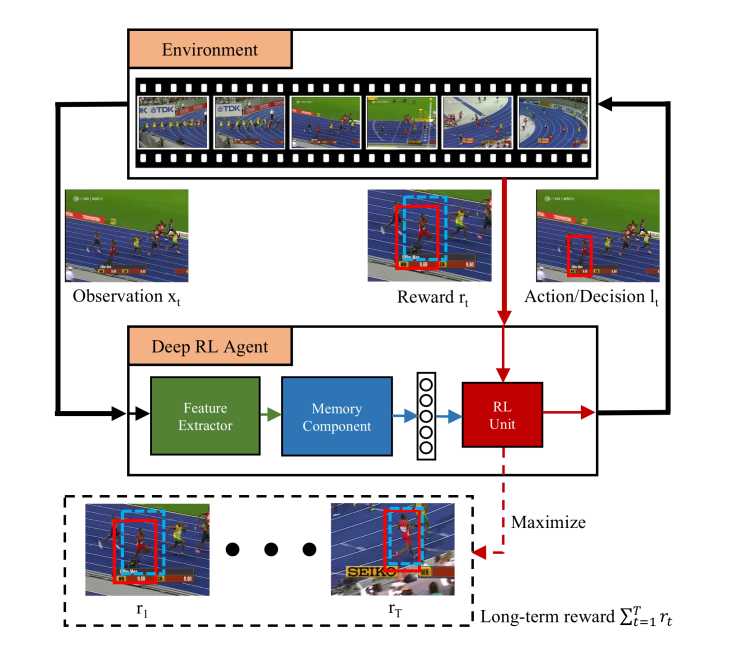
Tracking Framework :
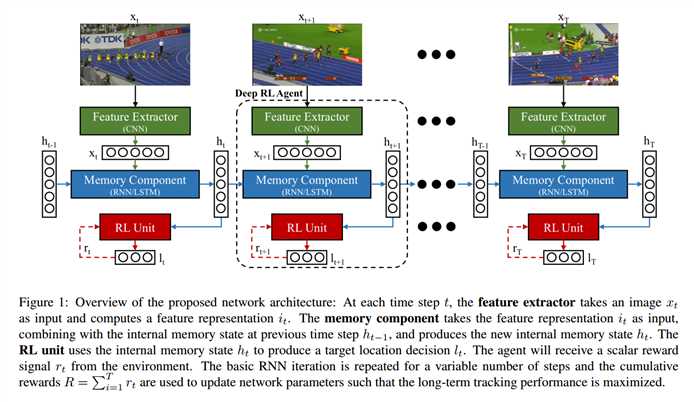
本文提出的 Deep RL 算法框架,由三个部分构成:
1 CNN 特征提取部分;
2 RNN 历史信息构建部分;
3 DEEP RL 模块
前两个部分没什么要说的,就是简单的 CNN, LSTM 结构。
第三个 RL 部分:
说到底,这个文章是在之前 attention model based Tracker ICLR 2016 年的一个文章基础上做的。
RL 部分就是没有变换,直接挪过来的。
状态,是跟踪视频的 frame ;
动作,是 多变量高斯分布得到的 predicted location;
奖励,是 scalar reward signal, 定义为:$r_t = -avg(l_t - g_t) - max(l_t - g_t)$ ,lt 是RL单元的输出,gt 是时刻 t 的 gt ;
avg() 是给定矩阵的 mean value; max() 是计算给定元素的最大值。
训练的目标是最大化奖励信号 R。
学习的目标函数为:
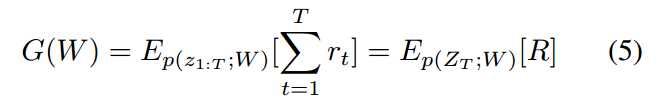
其中,p(z1:T; W) 是可能交互的分布,参数化为 W (the distribution over possible interactions parameterized by W).
上述函数涉及到 an expectation over high-dimensional interactions,以传统的监督方法来解决是非常困难的。
利用 RL 领域中的 REINFORCE algorithm 进行近似求解。

总体来说,在我之前,将 DRL 这个框架用于 跟踪问题,这一点,我服了。。。
第二点,就是,在前人方法上的改动不大,不能说非常大的创新点 。。。
Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记
标签:ural 中比 解决 sed com strong mode ica 比较
原文地址:http://www.cnblogs.com/wangxiaocvpr/p/6391221.html