标签:style tap adl print create pat master ges lis
一:TopN的书写编码
1.先上传数据
2.程序
1 package com.ibeifeng.bigdata.spark.core 2 3 import java.util.concurrent.ThreadLocalRandom 4 5 import org.apache.spark.{SparkConf, SparkContext} 6 7 /** 8 * 分组TopN:按照第一个字段分组;同一组中,按照第二个字段进行排序;每一组中,获取出现最多的前K个数据。 9 * Created by ibf on 01/15. 10 */ 11 object GroupedTopN { 12 def main(args: Array[String]): Unit = { 13 val conf = new SparkConf() 14 .setMaster("local[*]") 15 .setAppName("grouped-topn") 16 //.set("spark.eventLog.enabled", "true") 17 //.set("spark.eventLog.dir", "hdfs://hadoop-senior01:8020/spark-history") 18 19 val sc = SparkContext.getOrCreate(conf) 20 21 // ==========具体代码逻辑======================== 22 // 原始数据存储的路径, 需要自己上传 23 val path = "/user/beifeng/spark/groupedtopk/groupsort.txt" 24 val K = 3 25 26 // 构建rdd 27 val rdd = sc.textFile(path) 28 29 // rdd操作 30 val word2CountRDD = rdd 31 .filter((line: String) => { 32 // 过滤空字符串,所以非空的返回true 33 !line.isEmpty 34 }) 35 .map(line => { 36 // 按照空格分隔字段 37 val arr = line.split(" ") 38 // 将数据转换为二元组 39 (arr(0), arr(1).toInt) 40 }) 41 42 // 如果一个RDD被多次使用,该RDD需要进行缓存操作 43 word2CountRDD.cache() 44 45 // 直接使用groupByKey函数进行统计,这种方式存在OOM的情况 46 /* 47 val resultRDD = word2CountRDD 48 .groupByKey() // 按照第一个字段进行分组 49 .map(tuple => { 50 // 同一组的数据中获取前K个元素 51 // 获取对应分组 52 val word = tuple._1 53 // 获取前K个元素(最大的k个元素), list默认排序是升序, 所以采用takeRight从后往前获取K个元素(此时的K个元素就是最大的K个元素); 最后对K个元素进行反转,最终结果元素是从大到小排序的 54 val topk = tuple._2.toList.sorted.takeRight(K).reverse 55 // 返回结果 56 (word, topk) 57 }) 58 */ 59 60 /* 61 * groupByKey存在OOM异常 62 * 解决方案:采用两阶段聚合操作 63 * 两阶段聚合可以解决的一些常见: 64 * 1. 聚合操作中存储的OOM异常 65 * 2. 聚合操作中存在的数据倾斜问题 66 * 聚合操作:分区、排序、reduceByKey..... 67 * */ 68 val random = ThreadLocalRandom.current() 69 val resultRDD2 = word2CountRDD 70 .map(tuple => { 71 // 第一阶段第一步:在key前加一个随机数 72 ((random.nextInt(100), tuple._1), tuple._2) 73 }) 74 .groupByKey() // 第一阶段的第二步:按照修改后的key进行聚合操作 75 .flatMap(tuple => { 76 // 第一阶段的第三步:对一组value进行聚合操作 77 // 获取对应分组 78 val word = tuple._1._2 79 // 获取前K个 80 val topk = tuple._2.toList.sorted.takeRight(K).reverse 81 // 返回结果 82 topk.map(count => (word, count)) 83 }) 84 .groupByKey() // 第二阶段第一步:按照原本的key进行聚合操作 85 .map(tuple => { 86 // 第二阶段第二步: 获取前k个元素 87 val word = tuple._1 88 val topk = tuple._2.toList.sorted.takeRight(K).reverse 89 // 返回结果 90 (word, topk) 91 }) 92 93 94 // 结果输出 95 resultRDD2.foreach(println) 96 /* 97 resultRDD2.foreachPartition(iter => { 98 // foreachPartition该函数常用于将RDD的数据输出到第三方的数据存储系统中,比如:redis、mongoDB 99 /* 100 * 1. 创建连接 101 * 2. 对iter进行迭代,进行数据输出 102 * 3. 关闭连接 103 * */ 104 iter.foreach(println) 105 }) 106 */ 107 108 // 如果RDD有cache,需要去除cache 109 word2CountRDD.unpersist() 110 111 // ==========具体代码逻辑======================== 112 113 sc.stop() 114 } 115 }
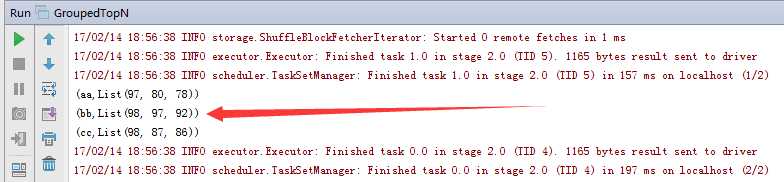
3.结果
4.注意点
Spark中不支持二次排序,如果想实现二次排序,需要根据业务的执行逻辑使用两阶段聚合来进行操作
二:优化
1.两阶段聚合

标签:style tap adl print create pat master ges lis
原文地址:http://www.cnblogs.com/juncaoit/p/6398937.html