标签:模型选择 朴素贝叶斯 boost 技术 lin 字段 learn regress 过拟合
数据清洗
不可信样本丢弃
缺省值极多的字段考虑不用
数据采样
下/上采样
保证样本均衡
特征处理
数值型
类别型
时间型
文本型
统计型
组合特征
特征选择
过滤型
sklearn.feature_selection.SelectKBest
包裹型
sklearn.feature_selection.RFE
嵌入型
feature_selection.SelectFromModel
Linear model, L1正则
模型选择
1.样本量很小的情况下,可以考虑直接用一些统计规则,而不用使用模型,反而可控,可解释性强
2. 样本量大,机器学习模型,y是不是类别变量(分类,回归),是否有标签(有监督,无监督)
3.文本数据可能考虑TF-IDF, SVM, 朴素贝叶斯;图像可能考虑deep learning
超参数的选择
交叉验证
K 折交叉验证,用于超参数的选择
正则化其实是约束你的样本空间,不会让你去你和一些极端的离群点
交叉验证选取超参数

模型状态
欠拟合
过拟合
随着样本的增长,训练集准确率不断下降,验证集准确率不断上升。
如果训练集的曲线的准确率比较低,那么模型就是欠拟合
如果训练集的曲线和验证集曲线中间的距离很大,那么模型就是过拟合

不同模型状态处理
过拟合
找更多的数据学习
增大正则化系数
减少特征个数(不是太推荐)
欠拟合
找到更多系数
减小正则化系数
线性模型的权重分析
过线性或者线性kernel的model:Linear regression , logistic regression, linearSVM
对于权重值较大的特征,你可能会去做更细划分,比如如果城市这个特征的权重值比较大,你可能会去再把城市下面区的特征再拿出来。或者将两个权重较大的特征进行组合,比如性别和城市组合。
Bad case分析
针对分类问题:哪些训练样本分错了?我们哪部分特征使得它做了这个判定?这些badcase有没有共性,是否有还没有挖掘的特性。
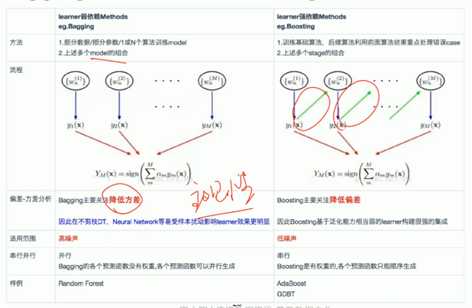
模型融合
什么是模型融合?融合学习是一组个体学习器的组合,如果这些个体学习器都是同质的,比如决策树,再用bagging,或者是gbdt这种递进学习的情况,成为基础学习器(base learner) ,如果这些个体学习器是异质的,成为组合学习器。
可以更加接近真实值
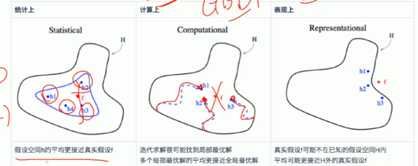
1.群众的力量是伟大的,集体智慧是惊人的
bagging \Random forest
缓解过拟合,多给他点题,别让他死记硬背;多找几个同学做题,综合一下他们的答案

2.站在巨人的肩膀上能看的更远
模型stacking,多个模型的输出,重新作为输入,如果是分类,可以取不同的权重后,再用符号函数,求得最后的分类。

3.一万小时定律
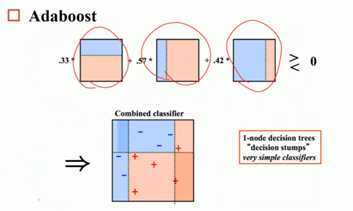
adaboost:重复迭代和训练,每次分配更错样本更高的权重,最简单分类器叠加
每个简单分类器给予不同的权重
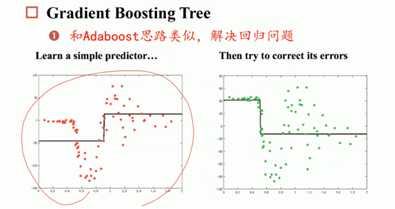
逐步增强树/gradient boosting tree
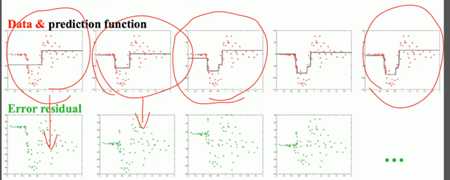
与标准答案做一个差值,绿色点为差值情况,学习差距,不断的学习差值
标签:模型选择 朴素贝叶斯 boost 技术 lin 字段 learn regress 过拟合
原文地址:http://www.cnblogs.com/fionacai/p/6407693.html