标签:内容 als 官方文档 one field port dfs post 变化
在实际生产中,HBase往往不能满足多维度分析,我们能想到的办法就是通过创建HBase数据的二级索引来快速获取rowkey,从而得到想要的数据。目前比较流行的二级索引解决方案有Lily HBase Indexer,Phoenix自带的二级索引,华为Indexer,以及360的二级索引方案。上面的目前使用比较广泛的应该是Lily HBase Indexer,但是我们有时候只想实现一些简单的功能或者比较特殊的功能的时候,需要自己写协处理器进行处理。学习HBase的协处理器对于了解HBase架构是有帮助的。
协处理器分两种类型,系统协处理器可以全局导入region server上的所有数据表,表协处理器即是用户可以指定一张表使用协处理器。
Hbase的coprocessor分为两类,Observer和EndPoint。其中Observer相当于触发器,EndPoint相当于存储过程。其中Observer的代码部署在服务端,相当于对API调用的代理。
另一个是终端(endpoint),动态的终端有点像存储过程。
Observer
观察者的设计意图是允许用户通过插入代码来重载协处理器框架的upcall方法,而具体的事件触发的callback方法由HBase的核心代码来执行。协处理器框架处理所有的callback调用细节,协处理器自身只需要插入添加或者改变的功能。以HBase0.92版本为例,它提供了三种观察者接口:
这些接口可以同时使用在同一个地方,按照不同优先级顺序执行.用户可以任意基于协处理器实现复杂的HBase功能层。HBase有很多种事件可以触发观察者方法,这些事件与方法从HBase0.92版本起,都会集成在HBase API中。不过这些API可能会由于各种原因有所改动,不同版本的接口改动比较大。
实时更新数据需要获取到HBase的插入、更新和删除操作。由于HBase中的插入和更新都是对应RegionServer的Put操作,因此我们需要使用RegionObserver中的"postPut"和"postDelete函数"。至于Truncate操作则需要使用MasterObserver。
我们需要做的就是拦截put和delete操作,将里面的内容获取出来,写入Solr。 对应的协处理器代码如下:
package com.bqjr.bigdata.HBaseObserver.server;import com.bqjr.bigdata.HBaseObserver.entity.SolrServerManager;import org.apache.hadoop.hbase.CellUtil;import org.apache.hadoop.hbase.client.Delete;import org.apache.hadoop.hbase.client.Durability;import org.apache.hadoop.hbase.client.Put;import org.apache.hadoop.hbase.coprocessor.BaseRegionObserver;import org.apache.hadoop.hbase.coprocessor.ObserverContext;import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment;import org.apache.hadoop.hbase.regionserver.wal.WALEdit;import org.apache.hadoop.hbase.util.Bytes;import org.apache.solr.client.solrj.SolrServerException;import org.apache.solr.common.SolrInputDocument;import java.io.IOException;/*** Created by hp on 2017-02-15. */public class HBaseIndexerToSolrObserver extends BaseRegionObserver{String[] columns = {"test_age","test_name"};String collection = "bqjr";SolrServerManager solrManager = new SolrServerManager(collection);@Overridepublic void postPut(ObserverContext<RegionCoprocessorEnvironment> e,Put put, WALEdit edit, Durability durability) throws IOException {String rowkey= Bytes.toString(put.getRow());SolrInputDocument doc = new SolrInputDocument();for(String column : columns){if(put.has(Bytes.toBytes("cf1"),Bytes.toBytes(column))){doc.addField(column,Bytes.toString(CellUtil.cloneValue(put.get(Bytes.toBytes("cf1"),Bytes.toBytes(column)).get(0))));}}try {solrManager.addDocToCache(doc);} catch (SolrServerException e1) {e1.printStackTrace();}}@Overridepublic void postDelete(ObserverContext<RegionCoprocessorEnvironment> e,Delete delete,WALEdit edit,Durability durability) throws IOException{String rowkey= Bytes.toString(delete.getRow());try {solrManager.delete(rowkey);} catch (SolrServerException e1) {e1.printStackTrace();}}}
大体的写入流程我们已经完成了,接下来就是Solr的写入实现了。由于Solr需要使用Zookeeper等信息,我们可以直接通过HBase的conf中获取Zookeeper相关信息来构造所需要的SolrCloudServer。
另一方面,我们不能来了一条数据就马上写入,这样非常消耗资源。因此我们需要做一个缓存,将这些Solr数据暂时保存在里面,定时 + 定量的发送。代码如下
package com.bqjr.bigdata.HBaseObserver.entity;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.hbase.HBaseConfiguration;import org.apache.solr.client.solrj.SolrServerException;import org.apache.solr.client.solrj.impl.CloudSolrServer;import org.apache.solr.client.solrj.response.UpdateResponse;import org.apache.solr.common.SolrInputDocument;import java.io.IOException;import java.util.*;/*** Created by hp on 2017-02-15. */public class SolrServerManager {public static String ZKHost = "";public static String ZKPort = "";int zkClientTimeout = 1800000;// 心跳int zkConnectTimeout = 1800000;// 连接时间CloudSolrServer solrServer;private static String defaultCollection;int maxCache = 10000;public static List<SolrInputDocument> cache = new LinkedList<SolrInputDocument>();private static int maxCommitTime = 60; //最大提交时间,spublic SolrServerManager(String collection) {defaultCollection = collection;Configuration conf = HBaseConfiguration.create();ZKHost = conf.get("hbase.zookeeper.quorum", "bqdpm1,bqdpm2,bqdps2");ZKPort = conf.get("hbase.zookeeper.property.clientPort", "2181");String SolrUrl = ZKHost + ":" + ZKPort + "/" + "solr";solrServer = new CloudSolrServer(SolrUrl);solrServer.setDefaultCollection(defaultCollection);solrServer.setZkClientTimeout(zkClientTimeout);solrServer.setZkConnectTimeout(zkConnectTimeout);//启动定时任务,第一次延迟10执行,之后每隔指定时间执行一次Timer timer = new Timer();timer.schedule(new CommitTimer(), 10 * 1000L, maxCommitTime * 1000L);}public UpdateResponse put(SolrInputDocument doc) throws IOException, SolrServerException {solrServer.add(doc);return solrServer.commit(false, false);}public UpdateResponse put(List<SolrInputDocument> docs) throws IOException, SolrServerException {solrServer.add(docs);return solrServer.commit(false, false);}public void addDocToCache(SolrInputDocument doc) throws IOException, SolrServerException {synchronized (cache) {cache.add(doc);if (cache.size() >= maxCache) {this.put(cache);cache.clear();}}}public UpdateResponse delete(String rowkey) throws IOException, SolrServerException {solrServer.deleteById(rowkey);return solrServer.commit(false, false);}/*** 提交定时器 */ static class CommitTimer extends TimerTask {@Overridepublic void run() {synchronized (cache) {try {new SolrServerManager(defaultCollection).put(cache);cache.clear();} catch (IOException e) {e.printStackTrace();} catch (SolrServerException e) {e.printStackTrace();}cache.clear();}}}}
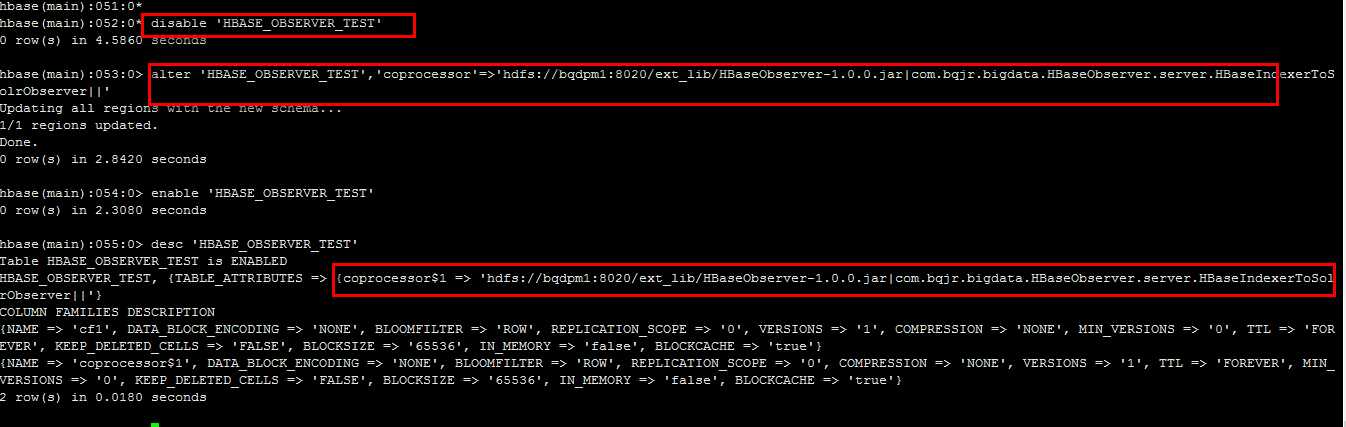
#先禁用这张表disable ‘HBASE_OBSERVER_TEST‘#为这张表添加协处理器,设置的参数具体为: jar文件路径|类名|优先级(SYSTEM或者USER)alter ‘HBASE_OBSERVER_TEST‘,‘coprocessor‘=>‘hdfs://bqdpm1:8020/ext_lib/HBaseObserver-1.0.0.jar|com.bqjr.bigdata.HBaseObserver.server.HBaseIndexerToSolrObserver||‘#启用这张表enable ‘HBASE_OBSERVER_TEST‘#删除某个协处理器,"$<bumber>"后面跟的ID号与desc里面的ID号相同alter ‘HBASE_OBSERVER_TEST‘,METHOD=>‘table_att_unset‘,NAME => ‘coprocessor$1‘
尝试插入一条数据put ‘HBASE_OBSERVER_TEST‘,‘001‘,‘cf1:test_age‘,‘18‘
结果Solr中一条数据都没有
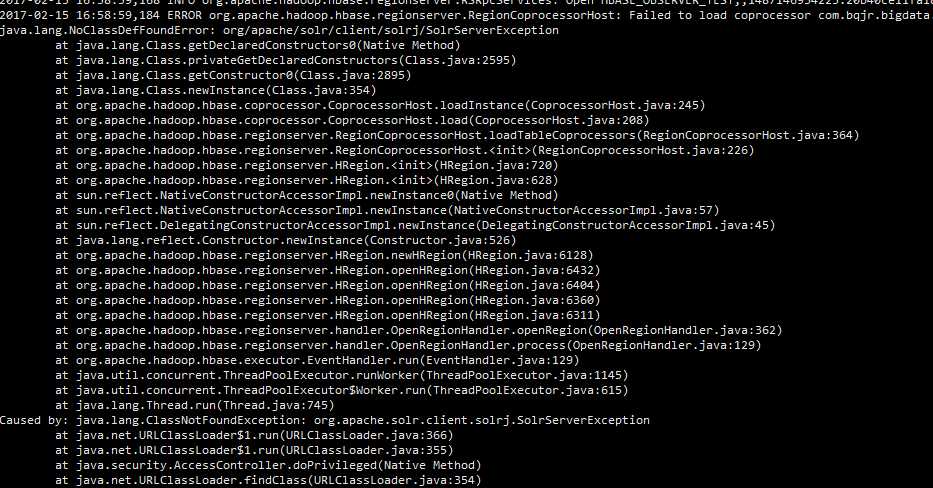
然后查看了regionserver的日志发现,没有找到SolrJ的类
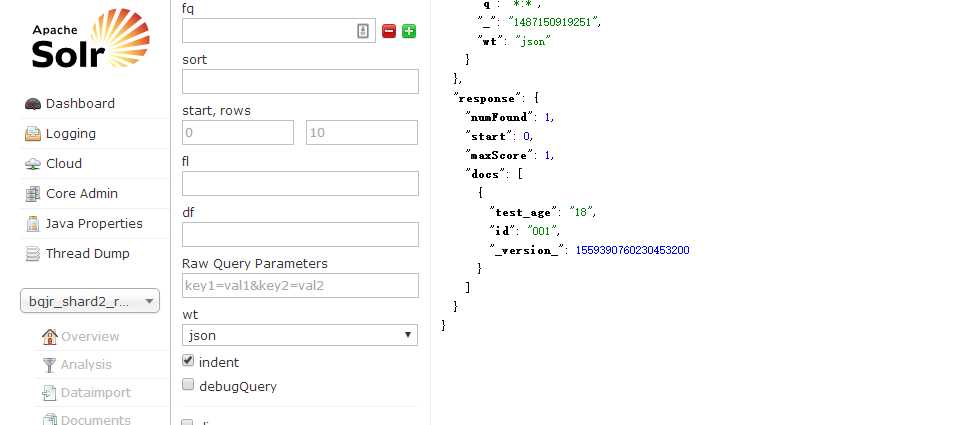
然后我们将所有的依赖加到Jar包里面之后,再次运行。就可以看到数据了。
测试Delete功能
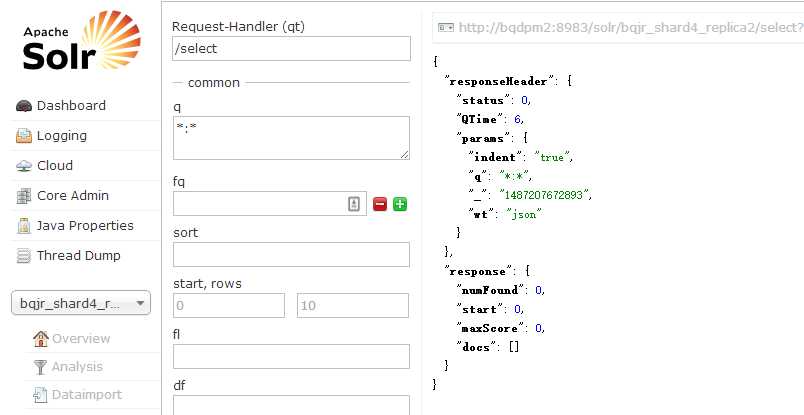
测试进行到这里就完了吗?当然不是
我们尝试再插入一条put ‘HBASE_OBSERVER_TEST‘,‘001‘,‘cf1:test_name‘,‘Bob‘
理论上我们需要在Solr中看到 test_age = 18,test_name = Bob。
但是在Solr中只有一条数据
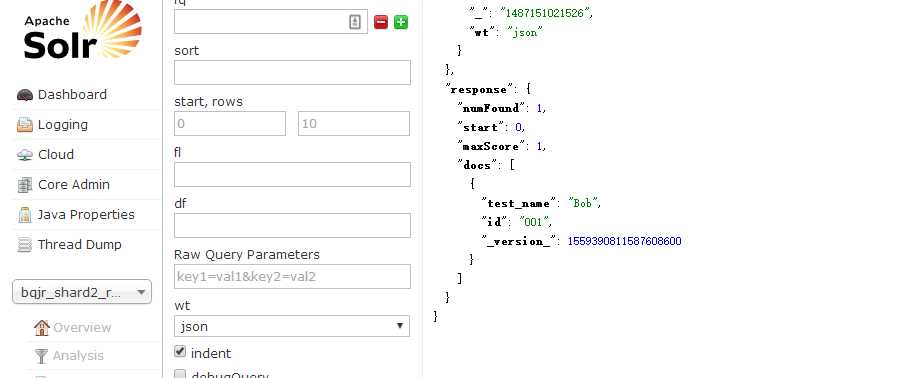
于是我们需要使用到Solr的原子更新功能。将postPut改成下面这样的代码即可
public void postPut(ObserverContext<RegionCoprocessorEnvironment> e,Put put, WALEdit edit, Durability durability) throws IOException {String rowkey= Bytes.toString(put.getRow());Long version = 1L;SolrInputDocument doc = new SolrInputDocument();for(String column : columns){if(put.has(Bytes.toBytes("cf1"),Bytes.toBytes(column))){Cell cell = put.get(Bytes.toBytes("cf1"),Bytes.toBytes(column)).get(0);Map<String, String > operation = new HashMap<String,String>();operation.put("set",Bytes.toString(CellUtil.cloneValue(cell)));doc.setField(column,operation);}}doc.addField("id",rowkey);// doc.addField("_version_",version);try {solrManager.addDocToCache(doc);} catch (SolrServerException e1) {e1.printStackTrace();}}
再次插入数据

查看Solr结果
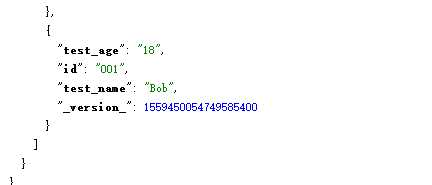
hbase的官方文档指出动态级别的协处理器,可以做到不重启hbase,更新协处理,做法就是
禁用表,卸载协处理器,重新指定协处理器, 激活表,即可,但实际测试发现
动态加载无效,是hbase的一个bug,看这个链接:
https://issues.apache.org/jira/browse/HBASE-8445
因为协处理器,已经被JVM加载,即使删除jar也不能重新load的jar,因为cache里面的hdfs的jar路径,没有变化,所以动态更新无效
,除非重启JVM,那样就意味着,需要重启RegionServer,
里面的小伙伴们指出了两种办法,使协处理器加载生效:
(1)滚动重启regionserver,避免停掉所有的节点
(2)改变协处理器的jar的类名字或者hdfs加载路径,以方便有新的ClassLoad去加载它
但总体来看,第2种方法,比较安全,第一种风险太大,一般情况下没有人会随便滚动重启线上的服务器的,这只在hbase升级的时候使用
标签:内容 als 官方文档 one field port dfs post 变化
原文地址:http://www.cnblogs.com/kekukekro/p/6409480.html