标签:blog 实用 论文 接收 gen sed 位置 alt 推断
本篇文章调研一些感兴趣的AAAI 2016 papers。科研要多读paper!!!
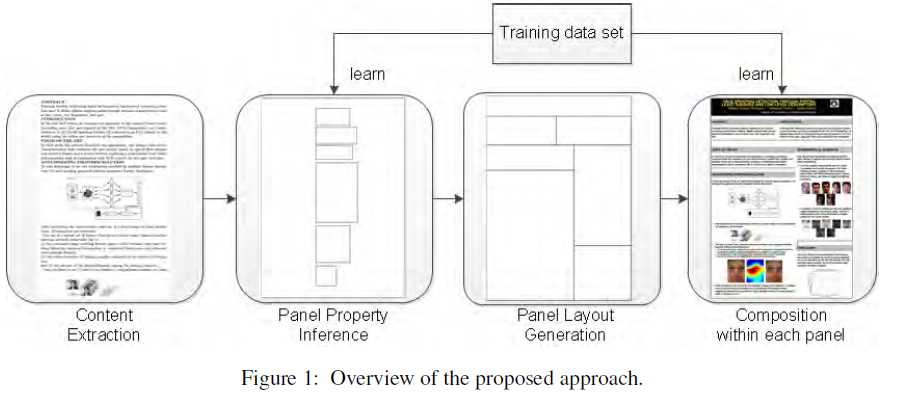
这篇paper研究从科技论文中生成海报的问题。这是一个很新颖实用的问题。paper中给出了一个Poster-Paper数据集。
为了达到目标,一个利用概率图模型的数据驱动框架被提出。
特别地,给定要显示的内容,一个好的poster的关键元素(包括每个板块的布局和每个板块的属性)被从数据中学习推断得到。每个板块内的图形元素构成被合成。
内容抽取和布局生成是生成一个令人满意的海报的两个关键元素。对于内容抽取,文中使用TextRank (Mihalcea and Tarau 2004)去抽取文字内容,然后作者提供了一个用户接口去抽取图形元素。
paper提出的方法主要针对于布局生成。文中通过三个步骤实现这一目的。首先,作者提出一个简单的概率图模型推断模块属性;然后,一个树形结构被引进用于表达模块布局,基于树形结构,作者进一步设计了一种递归算法生成模块布局。第三步,为了合成每个模块内部的布局,作者训练另一个概率图模型去推断图形元素的属性。
这篇paper提出一个新颖的自动化妆检测和移除框架。

化妆检测子:一个局部约束的低阶字典学习算法被用于决定和定位化妆位置。
卸妆:一个局部约束的耦合质点学习框架(locality-constrained coupled dictionary learning, LC-CDL)被用于合成无妆的人脸,所以化妆能够根据类型被拆除。
文中公布了一个逐步化妆的数据集(stepwise makeup dataset, SMU),提供了化妆过程,每张图片在人脸的子区域中标记了化妆状态信息。
文中对化妆有三个观测:
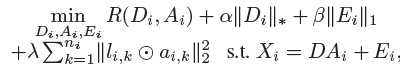
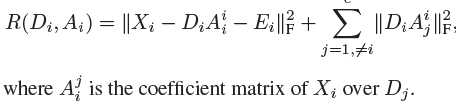
目前的哈希方法大多只关注相似性保留和编码误差最小化,很少最优化precision-recall曲线,或者接收端操作特性曲线?
这篇paper提出了一种基于projection的哈希方法,最大化precision和recall。
首先构建一族候选的基于投影的哈希函数,产生有效哈希码。这些哈希函数通过无关成分分析(Uncorrelated Component Analysis, UCA)产生。然后从这些哈希函数中,我们找出哪个最大化precision和recall性能。然后考虑一种特殊情况,数据正态分布,可以找出基于UCA的哈希函数的子集,最大化true positive rates的和。
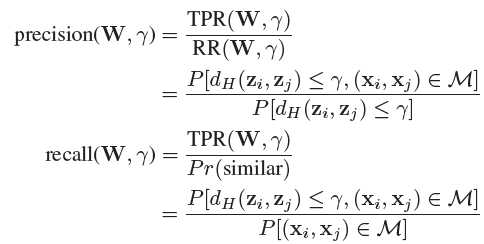

满足这两个条件的RR部分与W无关-->
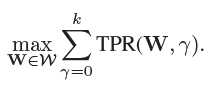
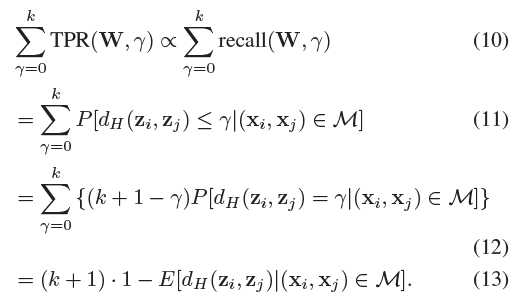
condition 1可以通过减中位数实现,condition 2通过relax为无关性约束实现:
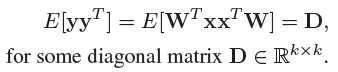
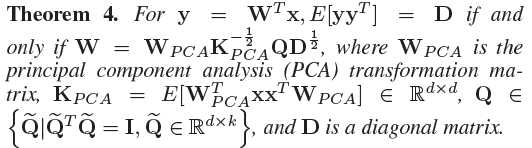
Q和D可以有无穷多的取值,从中选取能够最大化目标函数Eq. (10)的:
可以证明Eq. (10)不依赖D的取值,因此
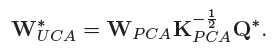
选择Q的过程中考虑数据呈高斯分布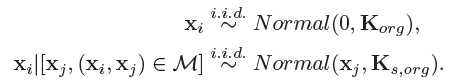
可以推导得到
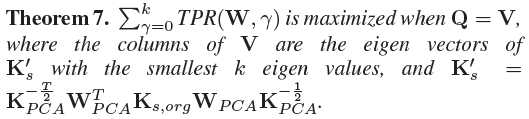
数学推导很精妙!
标签:blog 实用 论文 接收 gen sed 位置 alt 推断
原文地址:http://www.cnblogs.com/wm123/p/6399348.html