标签:是你 domain file 分享 32位 xpath 默认 官网 dir
安装pip install Scrapy
中间可能会遇到的问题:
创建项目:
其中*****是你的项目名
本文中使用tutorial
目录如上图所示
在items.py中写入需要保存的字段
import scrapy class TutorialItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() link = scrapy.Field() pass
上述代码中TutorialItem和项目名对应。这里保留两个字段,链接中的title和link
在spiders文件夹中新建爬虫文件命名随意,本文中命名为dmoz_spider.py
import scrapy from tutorial.items import TutorialItem class DmozSpider(scrapy.Spider): name = "dmoz" allowed_domains = ["http://www.wust.edu.cn/default.html"] start_urls = [ "http://www.wust.edu.cn/default.html" ] def parse(self, response): for sel in response.xpath(‘//ul/li‘): item = TutorialItem() item[‘title‘] = sel.xpath(‘a/text()‘).extract() item[‘link‘] = sel.xpath(‘a/@href‘).extract() yield item
这里定义了一个名为dmoz的爬虫,它去找存在于<ul>中的<li>中的<a>标签中的text和href,并将text赋给item中定义的title字段,将href赋给item中定义的link字段。=。=
yield 是用来在迭代时减少内存开销的
此时一个简单的爬虫已经搭建完成,这时我们运行
scrapy crawl dmoz -o result.josn -t json
就可以运行名为dmoz的爬虫,并将结果保存在result.json中,结果如图:
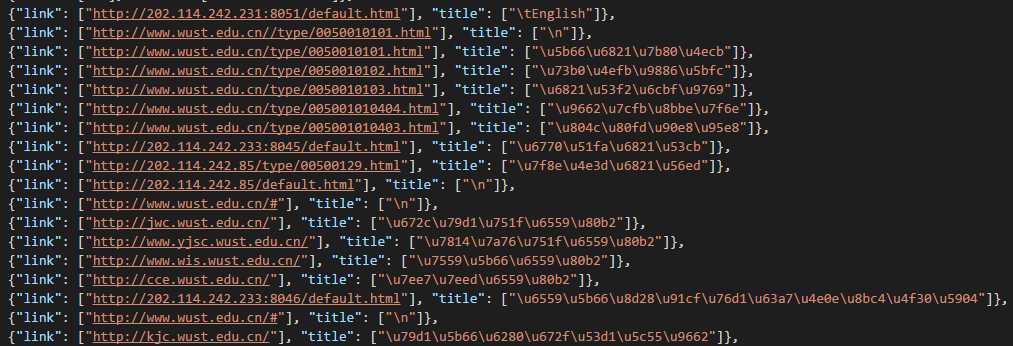
此处默认保存的是Unicode编码
标签:是你 domain file 分享 32位 xpath 默认 官网 dir
原文地址:http://www.cnblogs.com/kuqs/p/6424521.html