标签:bool turn get pid 个数 ref node blank pac
https://www.luogu.org/problem/show?pid=1231
滚粗了的HansBug在收拾旧语文书,然而他发现了什么奇妙的东西。
蒟蒻HansBug在一本语文书里面发现了一本答案,然而他却明明记得这书应该还包含一份练习题。然而出现在他眼前的书多得数不胜数,其中有书,有答案,有练习册。已知一个完整的书册均应该包含且仅包含一本书、一本练习册和一份答案,然而现在全都乱做了一团。许多书上面的字迹都已经模糊了,然而HansBug还是可以大致判断这是一本书还是练习册或答案,并且能够大致知道一本书和答案以及一本书和练习册的对应关系(即仅仅知道某书和某答案、某书和某练习册有可能相对应,除此以外的均不可能对应)。既然如此,HansBug想知道在这样的情况下,最多可能同时组合成多少个完整的书册。
输入格式:
第一行包含三个正整数N1、N2、N3,分别表示书的个数、练习册的个数和答案的个数。
第二行包含一个正整数M1,表示书和练习册可能的对应关系个数。
接下来M1行每行包含两个正整数x、y,表示第x本书和第y本练习册可能对应。(1<=x<=N1,1<=y<=N2)
第M1+3行包含一个正整数M2,表述书和答案可能的对应关系个数。
接下来M2行每行包含两个正整数x、y,表示第x本书和第y本答案可能对应。(1<=x<=N1,1<=y<=N3)
输出格式:
输出包含一个正整数,表示最多可能组成完整书册的数目。
5 3 4 5 4 3 2 2 5 2 5 1 5 3 5 1 3 3 1 2 2 3 3 4 3
2
样例说明:
如题,N1=5,N2=3,N3=4,表示书有5本、练习册有3本、答案有4本。
M1=5,表示书和练习册共有5个可能的对应关系,分别为:书4和练习册3、书2和练习册2、书5和练习册2、书5和练习册1以及书5和练习册3。
M2=5,表示数和答案共有5个可能的对应关系,分别为:书1和答案3、书3和答案1、书2和答案2、书3和答案3以及书4和答案3。
所以,以上情况的话最多可以同时配成两个书册,分别为:书2+练习册2+答案2、书4+练习册3+答案3。
数据规模:
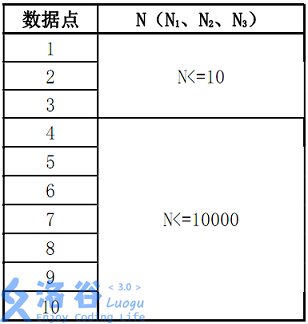
对于数据点1, 2, 3,M1,M2<= 20
对于数据点4~10,M1,M2 <= 20000
拆点+最大流
为什么要拆点?
以为一般的最大流可一个点经过多次,而本题一个点只能经过1次,所以要拆成一个流量为1的边
#include<cstdio> #include<cstring> #include<algorithm> #define N 10000 #define M 20001 using namespace std; int n1,n2,n3,m1,m2,tot=1,src,dec,ans,cur[N*5],lev[N*5],head,tail,que[4*5*N],tmp; int front[N*5]; struct node { int to,next,cap; }e[M*10]; inline void add(int u,int v) { e[++tot].to=v;e[tot].next=front[u];e[tot].cap=1;front[u]=tot; e[++tot].to=u;e[tot].next=front[v];e[tot].cap=0;front[v]=tot; } inline bool bfs() { for(int i=0;i<=N*5;i++) {lev[i]=-1;cur[i]=front[i];} head=tail=0; que[tail++]=src;lev[src]=0; while(head<tail) { int now=que[head]; for(int i=front[now];i;i=e[i].next) { int to=e[i].to; if(e[i].cap>0&&lev[to]==-1) { lev[to]=lev[now]+1; que[tail++]=to; if(to==dec) return true; } } head++; } return false; } inline int dinic(int now,int flow) { if(now==dec) return flow; int res=0,delta; for(int & i=cur[now];i;i=e[i].next) { int to=e[i].to; if(e[i].cap>0&&lev[to]>lev[now]) { delta=dinic(to,min(e[i].cap,flow-res)); if(delta) { e[i].cap-=delta;e[i^1].cap+=delta; res+=delta;if(res==flow) break; } } } if(res!=flow) lev[now]=-1; return res; } int main() { scanf("%d%d%d",&n1,&n2,&n3); src=0;dec=4*N+1; for(int i=1;i<=n3;i++) add(src,i); for(int i=1;i<=n1;i++) add(N+i,N*2+i); for(int i=1;i<=n2;i++) add(i+3*N,dec); int x,y; scanf("%d",&m1); for(int i=1;i<=m1;i++) { scanf("%d%d",&x,&y); add(x+2*N,y+3*N); } scanf("%d",&m2); for(int i=1;i<=m2;i++) { scanf("%d%d",&x,&y); add(y,x+N); } while(bfs()) ans+=dinic(src,n3); printf("%d",ans); }
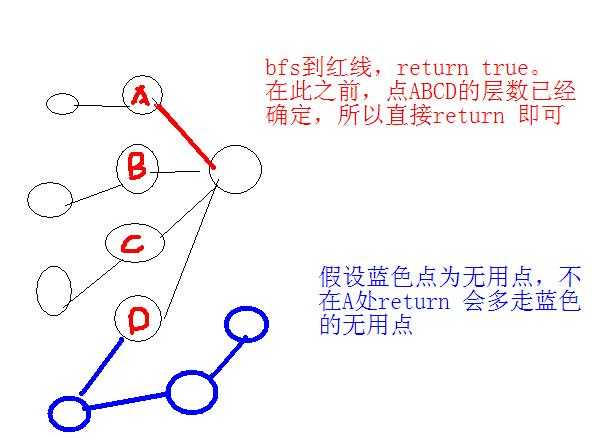
bfs中去掉if(to==des) reurn true
改为在最后return钱加一个 if(lev[dec]!=-1) return true;
前者比后者快。
原因:因为是bfs
标签:bool turn get pid 个数 ref node blank pac
原文地址:http://www.cnblogs.com/TheRoadToTheGold/p/6431332.html