标签:scala filename 调用 eth weight ges 代参 内容 cto
【未完待续。。。】
分号表示语句的结束;
如果一行只有一条语句时,可以省略,多条时,需要分隔
一般一行结束时,表示表达式结束,除非推断该表达式未结束:
// 末尾的等号表明下一行还有未结束的代码.
def equalsign(s: String) =
println("equalsign: " + s)
// 末尾的花括号表明下一行还有未结束的代码.
def equalsign2(s: String) = {
println("equalsign2: " + s)
}
//末尾的逗号、句号和操作符都可以表明,下一行还有未结束的代码.
def commas(s1: String,
s2: String) = Console.
println("comma: " + s1 +
", " + s2)
多个表达式在同一行时,需要使用分号分隔
定义的引用不可变,不能再指向别的对象,相当于Java中的final
Scala中一切皆对象,所以,定义一切都是引用(包括定义的基本类型变量,实质上是对象)
val定义的引用不可变,指不能再指向其他变量,但指向的内容是可以变的:

val定义的常量必须要初始化
val的特性能并发或分布式编程很有好处
定义的引用可以再次改变(内容就更可以修改了),但定义时也需要初始化
在Java中有原生类型(基础类型),即char、byte、short、int、long、float、double和boolean,这些都有相应的Scala类型(没有基本类型,但好比Java中相应的包装类型),Scala编译成字节码时将这些类型尽可能地转为Java中的原生类型,使你可以得到原生类型的运行效率
用val和var声明变量时必须初始化,但这两个关键字均可以用在构造函数的参数中,这时变量是该类的一个属性,因此显然不必在声明时进行初始化。此时如果用val声明,该属性是不可变的;如果用var声明,则该属性是可变的:
class Person(val name: String, var age: Int)
即姓名不可变,但年龄是变化的
val p = new Person("Dean Wampler", 29)

var和val关键字只标识引用本身是否可以指向另一个不同的对象,它们并未表明其所引用的对象内容是否可变
定义时可以省略类型,会根据值来推导出类型
scala> var str = "hello"
str: String = hello
scala> var int = 1
int: Int = 1
定义时也可明确指定类型:
scala> var str2:String = "2"
str2: String = 2
以前传统Java都是指令式编程风格,如果代码根本就没有var,即仅含有val,那它或许是函数式编程风格,因此向函数式风格转变的方式之一,多使用val,尝试不用任何var编程
指令式编程风格:
def printArgs(args: Array[String]): Unit = {
var i = 0
while (i < args.length) {
println(args(i))
i += 1
}
}
函数式编程风格:
def printArgs(args: Array[String]): Unit = {
for (arg <- args)
println(arg)
}
或者:
def printArgs(args: Array[String]): Unit = {
//如果字面量函数只有一行语句并且只带一个参数,
//则么甚至连指代参数都不需要
args.foreach(println)
}
数据范围、序列
支持Range的类型包括Int、Long、Float、Double、Char、BigInt和BigDecimal
Range可以包含区间上限,也可以不包含区间上限;步长默认为1,也可以指定一个非1的步长:


函数是一种具有返回值(包括空Unit类型)的方法
函数体中最后一条语句即为返回值。如果函数会根据不同情况返回不同类型值时,函数的返回类型将是不同值的通用(父)类型,或者是可以相互转换的类型(如Char->Int)
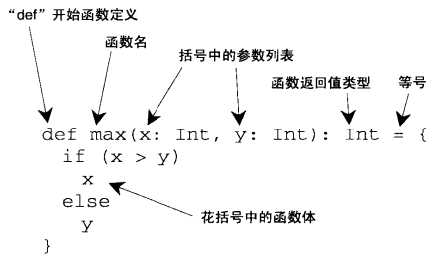
如果函数体只一条语句,可以省略花括号:
def max2(x:Int,y:Int)=if(x>y)x else y
scala> max2(3,5)
res2: Int = 5
Unit:返回类型为空,即Java中的void类型。如果函数返回为空,则可以省略
scala> def greet()=println("Hello")
greet: ()Unit
打印入口程序的外部传入的参数:
object Test {
def main(args: Array[String]): Unit = {
var i = 0
while (i < args.length) {
if (i != 0) print(" ")
print(args(i))
i += 1
}
}
}
注:Java有++i及i++,但Scala中没有。
与Java一样,while或if后面的布尔表达式必须放在括号里,不能写成诸如 if i < 10 的形式
object Test {
def main(args: Array[String]): Unit = {
var i = 0;
args.foreach(arg => { if (i != 0) print(" "); print(arg); i += 1 })
}
}
foreach方法参数要求传的是字面量函数(匿名函数),arg为字面量函数的参数,并且值为遍历出来的集合中的每个元素,类型为String,已省略,如不省略,则应为:
args.foreach((arg: String) => { if (i != 0) print(" "); print(arg); i += 1 })
如果字面量函数只有一行语句并且只带一个参数,则么甚至连指代参数都不需要:
args.foreach(println)
也可以使用for循环来代替:
for (arg <- args) println(arg)
val greetStrings: Array[String] = new Array[String](3)
greetStrings(0) = "Hello"
greetStrings(1) = ","
greetStrings(2) = "world!\n"
for (i <- 0 to 2)
print(greetStrings(i))
中括号为类型参数,即Java中的泛型<>,3表示数组长度为3,与Java中数据一样,一旦定下来就不能再变了
Scala的数组元素是通过索引值加圆括号进行的访问,而不是像Java那样把索引值放在中括号里,所以数组的第一个元素是greetStrings(0)而不是greetStrings[0]
Scala中一切都是对象,所以 i <- 0 to 2 相当于 (0).to(2) , 第一对圆括号可以省略:0.to(2)
Scala中没有操作符重载,诸如 +、-、*、/ 这样的字符是可以用来做方法名的,因此, 1 + 2 这样的语句实际上是在Int对象1上调用名为+的方法,并把2当作参数传给它,所以1+2传统的语法格式可以写成 (1).+(2):
在Scala中,用括号传递给变量(或类型)一个或多个参数值时,Scala会把它转换成对apply方法的调用,这个规则不只对于数组,任何对于对象的值参数应用将会被转换为对apply方法的调用,当然前提是这个类型定义过apply,所以:
val greetStrings: Array[String] = new Array[String](3)相当于var greetStrings: Array[String] = Array.apply(null,null,null)
print(greetStrings(i))相当于print(greetStrings.apply(i))
所以这就从另一方面说明为什么在Scala中使用圆括号来使用索引,而不是中括号
另外数据元素赋值操作也是相应方法的调用,所以 greetStrings(0) = "Hello" 实质上是 greetStrings.update(0, "Hello")方法的调用
数组在初始化时就赋值可以这样:
var greetStrings: Array[String] = Array("1", "2", "3")
此语句实质上是调用了数组的工厂方法apply,该方法接收可变参数,所以相当于:
var greetStrings: Array[String] = Array.apply("1", "2", "3")
Array在实例化之后长度就固定了,但它的元素值却是可变的,所以说数据还是可变的。
而Scala中的List就像Java中的String一样,任何改变其内容的操作(如replace)都会返回一个新的String,而不是真正修改原String对象的内容,所以,Scala中的List不同于Java中的List,一旦创建就不可变(应该是指不能增删元素),其List上的任何改变其内容的操作都是返回一个新的List而已
val oneTwo = List(1, 2)
val threeFour = List(3, 4)
//:::操作符是将在右List(threeFour)最前面加上左侧List(oneTwo)元素,形成一个新的List返回
val oneTwoThreeFour = oneTwo ::: threeFour
println(threeFour)//List(3, 4),内容没有被修改
println(oneTwoThreeFour)//List(1, 2, 3, 4)
上面使用 ::: 这个操作符将两个List合并在一起,而 ::则是将单个元素加到List最前面:
val twoThree = List(2, 3)
val oneTwoThree = 1 :: twoThree
println(twoThree)//List(2, 3),内容不会被修改
println(oneTwoThree)//List(1, 2, 3)
注: 1 :: twoThree 中,:: 是右操作数twoThree的方法,而不是左操作数1的方法,所以相当于 twoThree.::(1)。
规则:如果在定义时方法名以冒号结尾,则操作符右边的才是其调用者,而左边的只是其参数。所以上面的val oneTwoThreeFour = oneTwo ::: threeFour相当于:
val oneTwoThreeFour = threeFour.:::(oneTwo)
因为Nil 代表是空列表,所以可以使用 :: 操作符把单个的元素串起来形成新的列表:
val oneTwoThree = 1 :: 2 :: 3 :: Nil
println(oneTwoThree) //List(1,2,3)
注:List中没有append方法,即不支持在List末加元素,原因:因为随着列表变长,append的性能将逐渐变差,而使用::在最前端插入则是固定的时间,如果真要在末追加,则可以在前插入后,使用reverse方法即可,或者使用ListBuffer可变List,完成之后调用toList即可得到List列表
与List列表一样,元组是不可变的,但与列表不同,元组可以包含不同类型的元素
元组实例化之后,可以用点号、下划线和基于1(索引从1开始而非0)的索引访问其中的元素:
val pair = (99, "String")
println(pair._1)//99
println(pair._2)//String
上面Scala会推断元组的类型为Tuple2[Int,String],即:val pair:Tuple2[Int,String] = (99, "String")
注:_1、_2不是方法名,是字段成员名
元组的实际类型取决于它含有的元素数量和这些元素的类型,如(99, "String")的类型是Tuple2[Int,String]。(‘u‘, ‘r‘, ‘the‘,1,4, "me")是Tuple6[Char, Char, Char,Int,Int,String],理论上可以创建任意长度的元组,但目前Scala库只支持到最大Tuple22
不能像访问列表中的元素那样访问元组中的元素,如pair(0),那是因为列表中的apply方法始终返回同样的类型,但元组里的类型不尽相同,所以两者访问方法不一样,另外, _N 的索引是基于1的,而不是0
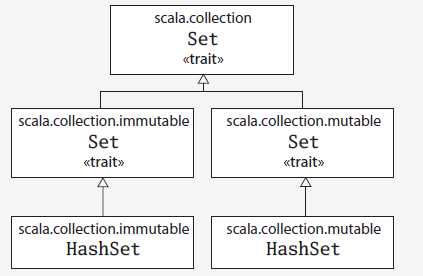
set与map都有可变和不可变(就像Array与List一样,Array是可变,而List不可变)不同包中的set、map决定了是可变还是不可变,immutable包下的为不可变,mutable包下的是可变:
var jetSet = Set("boeing", "airbus")
jetSet += "lear"
jetSet.foreach(set => println(set))
可变的和不可变的set都提供了+方法,但结果不同:可变set是把元素加入自身,而不可变set则创建并返回包含了添加元素的新set,上述使用的是不可变集,因此+调用将产生一个全新集。所以只有可变集才提供了真正的 += 名称的方法,而上面的不可变集的 += 操作符实质上是:
jetSet = jetSet + "lear"
即 += 中的 = 不是方法名的部分,而是赋值操作符,而scala.collection.mutable.Set提供了名为 += 的方法
如果没有明确导入,则默认使用的是不可变的set、map,若要使用可变的,则需要明确导入,如
import scala.collection.mutable.Set
此时上面的jetSet += "lear"就相当于:jetSet.+=("lear")
//注:创建的空的map,由于没有传递参数,所以这里的泛型不能省略
val map = Map[Int, String]()
map += (1 -> "1")
map.foreach(map => println(map))
1 -> "1"相当于 (1).->( "1"),Scala的任何对象都能调用 -> 方法并返回包含键值对的二元组
object Test {
def main(args: Array[String]): Unit = {
import scala.io.Source
//将文件中所有行读取到List列表中
val lines = Source.fromFile(args(0)).getLines().toList
//找到最长的行:类似冒泡排序,每次拿两个元素进行比较
val longestLine = lines.reduceLeft((a, b) => if (a.length() > b.length()) a else b)
//最长行的长度本身的宽度
val maxWidth = widthOfLength(longestLine)
for (line <- lines) {
val numSpaces = maxWidth - widthOfLength(line)
//让输出的每行宽度右对齐
val padding = " " * numSpaces
println(padding + line.length() + " | " + line)
}
}
def widthOfLength(s: String) = s.length().toString().length()
}

使用class定义类:
class ChecksumAccumulator {}
然后就可以使用 new 来实例化:
val cal = new ChecksumAccumulator
类里面可以放置字段和方法,这都称为成员(member)。
字段,不管是使用val还是var,都是指向对象的变量(即Java中的引用)
方法,使用def进行定义
class ChecksumAccumulator {
var sum = 0
}
object Test {
def main(args: Array[String]): Unit = {
val acc = new ChecksumAccumulator
val csa = new ChecksumAccumulator
}
}
刚实例化时内存的状态如下:
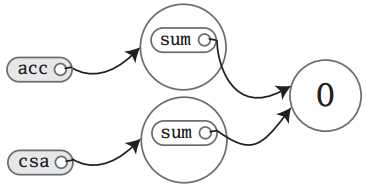
注:在Scala中,由于数字类型(整型与小数)都是final类型的,即不可变,所以在内存中如果是同一数据,则是共享的
由于上面是使用var进行定义的字段,而不是val,所以可以重新赋值:
acc.sum = 3
现在内存状态如下:
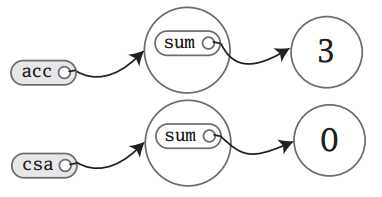
由于修改了acc中sum的内容,所以acc.sum指向了3所在的内存。
对象的稳定型就是要保证对象状态的稳定型,即对象中字段值在对象整个生命周期中持续有效。这需要将字段设为private以阻止外界直接对它进行访问与修改,因为私有字段只能被同一类里的方法访问,所以更新字段的代码将被锁定在类里:
class ChecksumAccumulator {
private var sum = 0
def add(b: Byte): Unit = {
sum += b
}
}
注:Java里公开需要使用public关键字,但在Scala里,默认就是public,是不需要写的
Scala里方法参数都是val的,不是var,如果修改则出错:
def add(b: Byte): Unit = {
b = 1 // 编译出错,因为b是val
sum += b
}
如果某个方法的方法体只有一条语句,则可以去掉花括号:
def add(b: Byte): Unit = sum += b
如果方法没有返回值(或为Unit),则定义方法时可以去掉结果类型和等号,并把方法体放在花括号里:
def add(b: Byte) { sum += b }
定义方法时,如果去掉方法体前面的等号,则方法的结果类型就一定是Unit,这不管方法体最后语句是啥,因为编译器可以把任何类型转换为Unit,如结果是String,但返回结果类型声明为Unit,那么String将被转换为Unit并丢弃原值。下面是明确定义返回类型为Unit:
scala> def f(): Unit = "this String gets lost"
f: ()Unit
去掉等号的方法返回值类型也一定是Unit:
scala> def g() { "this String gets lost too" }
g: ()Unit
加上等号时,如果没有确定定义返回类型,则会根据方法体最后语句来推导:
scala> def h() = { "this String gets returned!" }
h: ()java.lang.String
scala> h
res0: java.lang.String = this String gets returned!
Scala中不能定义静态成员,而是以定义成单例对象(singleton object)来代替,即定义类时,使用的object关键字,而非class关键字,但看上去就像定义class一样:
class ChecksumAccumulator {
private var sum = 0
def add(b: Byte): Unit = {
sum += b
}
def checksum(): Int = {
return ~(sum & 0xFF) + 1
}
}
import scala.collection.mutable.Map
object ChecksumAccumulator {
private val cache = Map[String, Int]()
def calculate(s: String): Int =
if (cache.contains(s))
cache(s)
else {
val acc = new ChecksumAccumulator
for (c <- s)
acc.add(c.toByte)
val cs = acc.checksum()
cache += (s -> cs)
cs
}
}
当单例对象(object)与某个类(class)的名称相同时(上面都为ChecksumAccumulator),它就被称为是这个类的伴生对象。类和它的伴生对象必须定义在一个源文件里。类被称为这个单例对象的伴生类。类和它的伴生对象可以互相访问其私有成员
可以将单例对象当作Java中的静态方法工具类来使用,可以直接使用单例对象的名称来调用:
ChecksumAccumulator.calculate("Every value is an object.")
其实,单例对象就是一个对象,不需要实例化就可以直接通过单例对象名来访问其成员,即单例对象名就相当于变量名,已指向了某个类的实例,只不过该类不是由你来实例化,而是在访问它时由Scala实例化出来的,且在JVM只有一个这个的实例。在编译伴生对象时,会生成一个相应名为ChecksumAccumulator$(在单例对象名后加上美元符号)的类:

类和单例对象的差别:单例对象不带参数,而类可以,因为单例对象不是使用new关键字实例化出来的。
单例对象在第一次被访问的时候才会被始化
没有伴生类的单例对象被称为独立对象,一般作为相关功能方法的工具类,或者用作Scala应用的入口程序
在Java中,只要类中有如下签名的main方法,即可作为程序入口程序:
class T {
public static void main(String[] args) {}
}
在Scala中,入口程序不是定义在类class中的,而是定义在单例对象中的,
object T {
def main(args: Array[String]): Unit = {}
}
Scala的每个源文件都会自动引入包java.lang和scala包中的成员,和scala包中名为Predef的单例对象的成员,该单例对象中包含了许多有用的方法,例如,当在Scala源文件中写pringln的时候,实际调用了Predef的println,另外当你写assert,实质上是调用Predef.assert
Java的源文件扩展名为.java,而Scala的源文件扩展名为.scala
在Java中,如果源文件中有public的class,则该public类的类名必须与Java源文件名一致,但在Scala中没有这种限制,但一般会将源文件名与类名设为一致(源文件非脚本的情况下)
与Java一样,也有对应的编译与运行命令,它们分别是scalac(编译)与scala(运行),ava中的为javac、java,不管是Java还是Scala程序,都会编译成.class的字节码文件
另外,Scala的入口程序还可以继承scala.App特质,这样就不用写main方法,而直接将代码写在花括号里,花括号里的代码会被收集进单例对象的主构造器中,并在类被初始化时执行:
object T extends scala.App {
println("T")
}
缺点:命令参数行args不能再被访问;某些JVM线程会要求main方法不能通过继承得到,必须自己行编写;

上面除了String类型为java.lang包中的类型外,其它基本类型都是名为scala包中的成员,如,Int的命名是scala.Int。由于包scala和java.lang包下的所有成员都被每个Scala源文件自动引用,所以可以直接使用上面这些基本类型,而不用加上包路径scala.xx与java.lang.xx,即引用时可以直接写成 Boolean、Char或String
Scala的基本类型与Java对应类型范围完全一样,这样可以让Scala编译器直接把这些类型编译成Java中的原始类型
字面量就是直接写在代码里的常量值
十六进制以 0x或0X开头:
scala> val hex = 0x5
hex: Int = 5
scala> val hex2 = 0x00FF
hex2: Int = 255
scala> val magic = 0xcafebabe
magic: Int = -889275714
注:不区分大小写
八进制以0开头
scala> val oct = 035 // (八进制35是十进制29)
oct: Int = 29
scala> val nov = 0777
nov: Int = 511
scala> val dec = 0321
dec: Int = 209
如果是非0开头,即十进制:
scala> val dec2 = 255
dec2: Int = 255
注:不管字面量是几进制,输出时都会转换为十进制
如果整数以L或l结尾,就是Long类型,否则默认就是Int类型:
scala> val prog = 0XCAFEBABEL
prog: Long = 3405691582
scala> val tower = 35L
tower: Long = 35
scala> val of = 31l
of: Long = 31
从上面可以看出,定义Int型时可以省去类型即可,如果是Long类型,定义时也可省略Long类型,此时在数字后面加上L或l即可,但也可以直接定义成Long也可:
scala> var lg:Long = 2
lg: Long = 2
如果要得到Byte或Short类型的变量时,需在定义时指定变量的相应类型:
scala> val little: Short = 367
little: Short = 367
scala> val littler: Byte = 38
littler: Byte = 38
scala> val big = 1.2345
big: Double = 1.2345
scala> val bigger = 1.2345e1
bigger: Double = 12.345
scala> val biggerStill = 123E45
biggerStill: Double = 1.23E47
小数默认就是Double类型,如果要是Float,则要以F结尾:
scala> val little = 1.2345F
little: Float = 1.2345
scala> val littleBigger = 3e5f
littleBigger: Float = 300000.0
当然Double类型也可以D结尾,不过是可选的
scala> val anotherDouble = 3e5
anotherDouble: Double = 300000.0
scala> val yetAnother = 3e5D
yetAnother: Double = 300000.0
当然,也要以在定义变量时明确指定类型也可:
scala> var f2 = 1.0
f2: Double = 1.0
scala> var f2:Float = 1
f2: Float = 1.0
使用单引号引起的单个字符
scala> val a = ‘A‘
a: Char = A
单引号之间除了直接是字符外,也可以是对应编码,编码是八进制或十六进制来表示
如果以八进制表示,则以 \ 开头,且为 ‘\0 到 ‘\377‘ (0377=255):
scala> val c = ‘\101‘
c: Char = A
注:如果以八进制表示,则只能表示一个字节大小的字符,即0~255之间的ASCII码单字节字符,如果要表示大于255的Unicode字符,则只能使用十六进制来表示:
scala> val d = ‘\u0041‘
d: Char = A scala>
val f = ‘\u0044‘
f: Char = D
scala> val c = ‘\u6c5f‘
c: Char = 江
注:以十六进制表示时,需以 \u(小写)开头,即后面跟4位十六进制的编码(两个字节)
实际上,十六进制可以出现在Scala程序的任何地方,如可以用在变量名里:
scala> val B\u0041\u0044 = 1
BAD: Int = 1
转义字符:
scala> val backslash = ‘\\‘
backslash: Char = \

使用双引号引起来的0个或多个字符
scala> val hello = "hello"
hello: java.lang.String = hello
特殊字符也需转义:
scala> val escapes = "\\\"\‘"
escapes: java.lang.String = \"‘
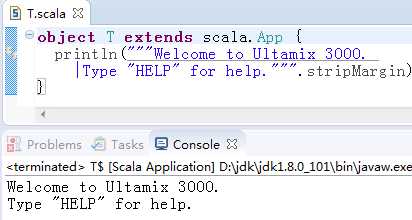
如果字符串中需要转义的字符很多时,可以使用三个引号(""")开头和结尾,这样之间的字符都将看作是最原始的字符,不会被转义(当然三个连续的引号除外):
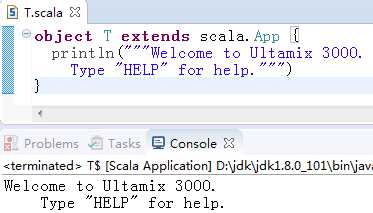
发现第二行前面的空格也会原样输出来,所以第二行前面看起来缩进了,如果要去掉每行前面的空白字符(ASCII编码小于等于32的都会去掉),则把管道符号(|)放在每行前面,然后对字符串调用stripMargin:
以单引号打头,后面跟一个或多个数字、字母或下划线,但第一个字符不能是数字,这种字面量会转换成预定义类scala.Symbol的实例,如 ‘cymbal编译器将会调用工厂方法Symbol("cymbal")转化成Symbol实例。
scala> val s = ‘aSymbol
s: Symbol = ‘aSymbol
scala> s.name
res20: String = aSymbol
符号字面量 ‘x 是表达式 scala.Symbol("x") 的简写
Java中String的intern()方法:String类内部维护一个字符串池(strings pool),当调用String的intern()方法时,如果字符串池中已经存在该字符串,则直接返回池中字符串引用,如果不存在,则将该字符串添加到池中,并返回该字符串对象的引用。执行过intern()方法的字符串,我们就说这个字符串被拘禁了(interned),即放入了池子。默认情况下,代码中的字符串字面量和字符串常量值都是被拘禁的,例如:
String s1 = "abc";
String s2 = new String("abc");
System.out.println(s1 == s2);//false
System.out.println(s1 == s2.intern());//true
同值字符串的intern()方法返回的引用都相同,例如:
String s2 = new String("abc");
String s3 = new String("abc");
System.out.println(s2 == s3);// false
System.out.println(s2.intern() == s3.intern());// true
String str1 = "abc";
String str2 = "abc";
System.out.println(str1 == str2);//true
String str3 = new String("abc");
System.out.println(str1 == str3);//false
Sysmbol实质上也是一种字符串,其好好处:
1. 节省内存
在Scala中,Symbol类型的对象是被拘禁的(interned,即会被放入池中),任意的同名symbols都指向同一个Symbol对象,避免了因冗余而造成的内存开销:
val s1 = "aSymbol"
val s2 = "aSymbol"
println(s1.eq(s2)) //true :表明s1与s2指向同一对象
val s3 = new String("aSymbol") //由于在编译时就确定,所以还是会放入常量池
println(s1.eq(s3)) //false : 表明s1与s3不是同一对象
println(s1 == s3) //true:虽然不是同一对象,但是它们的内容相同
val s = ‘aSymbol
println(s.eq(‘aSymbol)) //true
println(s.eq(Symbol("aSymbol"))) //true:只要是同名的Symbol,则都是指向同一对象
//即使s与s3的内容相同,但eq比较的是对象地址,所以不等
println(s.name.eq(s3)) //false
println(s.name == s3) //true:但内容相同
println(s.name.eq(s1)) //true : s与s1的的内容都会放入池中,所以指向的是同一对象
注:在Scala中,如果要基于引用地址进行比较,则要使用eq方法,而不是==,这与Java是不一样的
2. 快速比较
由于Symbol类型的对象会自动拘禁的(interned),任意的同名symbols(准确的说是值)都指向同一个Symbol对象,而相同值的字符串并不一定是同一个instance,所以symbols对象之间的比较操作符==速度会很快:因为它只基于地址进行比较,如果发现不是同一Symbols对象,则就认为不相同,不会在对内容进行比较(因为不同名的Symbols的值肯定也不相同)
Symbol类型的应用
Symbol类型一般用于快速比较,例如用于Map类型:Map<Symbol, Data>,根据一个Symbol对象,可以快速查询相应的Data, 而Map<String, Data>的查询效率则低很多。
虽说利用String的intern方法也可以实现Map<String, Data>的键值快速比较,但是由于需要显式地调用intern()方法,在编码时会造成很多的麻烦,而且如果忘了调用intern()方法,还会造成难以寻找的bug。从这个角度看,Scala的Symbol类型会自动进行intern操作(加入到池中),所以简化了编码的复杂度;而Java中除了字符串常量,是不会自动进行intern的,需要对相应对象手动调用interned方法
scala> val bool = true
bool: Boolean = true
scala> val fool = false
fool: Boolean = false
操作符如+加号,实质上是类型中有名为 + 的方法:
scala> val sum = 1 + 2 // Scala调用了(1).+(2)
sum: Int = 3
scala> val sumMore = (1).+(2)
sumMore: Int = 3
实际上Int类型包含了名为 + 的各种不同参数的重载方法,如Int+Long:
scala> val longSum = 1 + 2L // Scala调用了(1).+(2L)
longSum: Long = 3
既然+是名为加号的方法,可以以 1+2 这种操作模式来调用,那么其他方法也是可以如下方式来调用:
scala> val s = "Hello, world!"
s: java.lang.String = Hello, world!
scala> s indexOf ‘o‘ // Scala调用了s.indexOf(’o’)
res0: Int = 4
如果有多个参数,则要使用括号:
scala> s indexOf (‘o‘, 5) // Scala调用了s.indexOf(’o’, 5)
res1: Int = 8
任何方法都可以是操作符:Scala里的操作符不是特殊的语法,任何方法都可以是操作符,到底是方法还是操作符取决于你如何使用它。如果写成s.indexOf(‘o‘),indexOf就不是操作符。不过如果写成,s indexOf ‘o‘,那么indexOf就是操作符了
上面看到的是中缀操作符,还是前缀操作符,如 -7里的“-”,后缀操作符如 7 toLong里的“toLong”。
前缀操作符与后缀操作都只有一个操作数,是一元(unary)操作符,如-2.0、!found、~0xFF,这些操作符对应的方法是在操作符前加上前缀“unary_”:
scala> -2.0 // Scala调用了(2.0).unary_-
res2: Double = -2.0
scala> (2.0).unary_-
res3: Double = -2.0
可以当作前缀操作符用的标识符只有+、-、!和~。因此,如果你定义了名为unary_!的方法,就可以对值或变量用 !P 这样的前缀操作符方式调用方法。但是如果你定义了名为unary_*的方法,就没办法将其用成前缀操作符了,因为*不是四种可以当作前缀操作符用的标识符之一。
后缀操作符是不用点或括号调用的不带任何参数的方法:
scala> val s = "Hello, world!"
s: java.lang.String = Hello, world!
scala> s.toLowerCase()
res4: java.lang.String = hello, world!
由于不带参数,则可能省略括号
scala> s.toLowerCase
res5: java.lang.String = hello, world!
还可以省去点:
scala> import scala.language.postfixOps//需要导一下这个来激活后缀操作符使用方式,否则会警告
import scala.language.postfixOps
scala> s toLowerCase
res6: java.lang.String = hello, world!
scala> 1.2 + 2.3
res6: Double = 3.5
scala> 3 - 1
res7: Int = 2
scala> ‘b‘ - ‘a‘
res8: Int = 1
scala> 2L * 3L
res9: Long = 6
scala> 11 / 4
res10: Int = 2
scala> 11 % 4
res11: Int = 3
scala> 11.0f / 4.0f
res12: Float = 2.75
scala> 11.0 % 4.0
res13: Double = 3.0
数字类型还提供了一元的前缀 + 和 - 操作符(方法 unary_+ 和 unary_-)
scala> val neg = 1 + -3
neg: Int = -2
scala> val y = +3
y: Int = 3
scala> -neg
res15: Int = 2
scala> 1 > 2
res16: Boolean = false
scala> 1 < 2
res17: Boolean = true
scala> 1.0 <= 1.0
res18: Boolean = true
scala> 3.5f >= 3.6f
res19: Boolean = false
scala> ‘a‘ >= ‘A‘
res20: Boolean = true
可以使用一元操作符!(unary_!方法)改变Boolean值:
scala> val thisIsBoring = !true
thisIsBoring: Boolean = false
scala> !thisIsBoring
res21: Boolean = true
逻辑与(&&)和逻辑或(||):
scala> val toBe = true
toBe: Boolean = true
scala> val question = toBe || !toBe
question: Boolean = true
scala> val paradox = toBe && !toBe
paradox: Boolean = false
与Java里一样,逻辑与和逻辑或有短路:
scala> def salt() = { println("salt"); false }
salt: ()Boolean
scala> def pepper() = { println("pepper"); true }
pepper: ()Boolean
scala> pepper() && salt()
pepper
salt
res22: Boolean = false
scala> salt() && pepper()
salt
res23: Boolean = false
scala> pepper() || salt()
pepper
res24: Boolean = true
scala> salt() || pepper()
salt
pepper
res25: Boolean = true
按位与运算(&):都为1时才为1,否则为0
按位或运算(|):只要有一个为1 就为1,否则为0
按位异或运算(^):相同位产生0,不同产生1,因此0011 ^ 0101产生0110。
scala> 1 & 2 // 0001 & 0010 = 0000 = 0
res24: Int = 0
scala> 1 | 2 // 0001 | 0010 = 0011 = 3
res25: Int = 3
scala> 1 ˆ 3 // 0001 ^ 0011 = 0010 = 2
res26: Int = 2
scala> ~1 // ~0001 = 1110(负数原码:从最末一位向前除符号位各位取反即可) = 1010 = -2
res27: Int = -2
负数补码:反码+1
左移(<<),右移(>>)和无符号右移(>>>)。左移和无符号右移在移动的时候填入零。右移则在移动时填入左侧整数的最高位(符号位)。
scala> -1 >> 31 //1111 1111 1111 1111 1111 1111 1111 1111 向右移动后,还是 1111 1111 1111 1111 1111 1111 1111 1111,左侧用符号位1填充
res38: Int = -1
scala> -1 >>> 31 //1111 1111 1111 1111 1111 1111 1111 1111 向右无符号移动后,为0000 0000 0000 0000 0000 0000 0000 0001,左侧用0填充
es39: Int = 1
scala> 1 << 2 //0000 0000 0000 0000 0000 0000 0000 0001 向左位移后,为0000 0000 0000 0000 0000 0000 0000 0100,右侧用0填充
res40: Int = 4
基本类型比较:
scala> 1 == 2
res31: Boolean = false
scala> 1 != 2
res32: Boolean = true
scala> 2 == 2
res33: Boolean = true
这些操作对所有对象都起作用,而不仅仅是基本类型,如列表的比较:
scala> List(1, 2, 3) == List(1, 2, 3)
res34: Boolean = true
scala> List(1, 2, 3) == List(1, 3, 2)
res35: Boolean = false
还可以对不同类型进行比较,如:
scala> 1 == 1.0
res36: Boolean = true
scala> List(1, 2, 3) == "hello"
res37: Boolean = false
甚至可以与null进行比较:
scala> List(1, 2, 3) == null
res38: Boolean = false
==操作符在比较之前,会先判断左侧的操作符是否为null,不为null时再调用左操作数的equals方法进行比较,比较的结果主要是看这个左操作数的equals方法是怎么实现的。只要比较的两者内容相同且并且equals方法是基于内容编写的,不同对象之间比较也可能为true
Java中的==即可以比较原始类型,也可以比较引用类型。对于原始类型,Java的==比较值的相等性,与Scala一致,而对于引用类型,Java的==是比较这两个引用是否都指向了同一个对象,Scala也提供了这种基础引用地址的比较机制,名字是eq,与之相反的是ne(非同一对象时返回True)
Scala中没有操作符,操作符只是方法的一种表达方式,其优先级是根据作用符的第一个字符来判断的(也有例外,请看后面以等号 = 字符结束的一些操作符),如规定第一个字符*就比+的优先级高。以操作符的第一个字符为依据,优先级如下:
(所有其他的特殊字符)
* / %
+ -
:
= !
< >
&
^
|
(所有字母)
(所有赋值操作)
上面同一行的字符具有同样的优先级
scala> 2 << 2 + 2 // 2
<< (2 + 2)
res41: Int = 32
<<操作符第一个字符为<,根据上表 << 要比 + 优先级低
如果操作符以等号字符( =)结束 , 且操作符并非比较操作符<=, >=, ==,或=,那么这个操作符的优先级与赋值符( =)相同。也就是说,它比任何其他操作符的优先级都低。例如:
x *= y + 1
与下面的相同:
x *= (y + 1)
操作符 *= 以 = 结束,被当作赋值操作符,它的优先级低于+,尽管操作符的第一个字符是*看起来高于+。
任何以“:”字符结尾的方法由它的右操作数调用,并传入左操作数;其他结尾的方法与之相反,它们被左操作数调用,并传入右操作:a * b 变成 a.*(b), a:::b 变成 b.:::(a)。
多个同优先级操作符出现时,如果方法以:结尾,它们就被从右往左进行分组;反之,就从左往右进行分组,如:a ::: b ::: c 会被当作 a :::
(b ::: c),而 a * b * c 被当作(a * b) * c
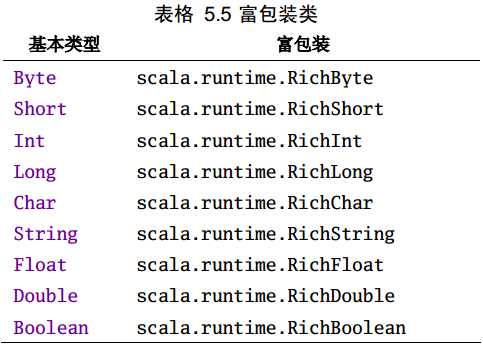
基本类型除了一些常见的算术操作外,还有一些更为丰富的操作,这些操作可以直接使用,更多需要参考API中对应的富包装类:
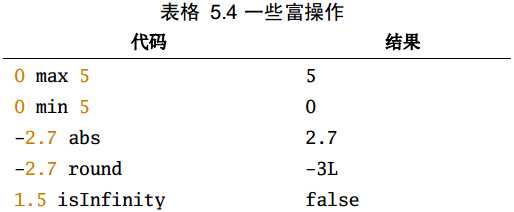

上述相应的富操作都是由下面相应的富包装类提供的,使用前会先自动进行隐式转换:
变量(本地变量、方法参数、成员字段)、或方法的定义名都是标识符。
标识符由字母、数字、操作符组成
Scala中有4种标识符:
字母数字标识符:以字母或下划线开始,后面可以跟字母、数字或下划线。注:$ 字符本身也是当作字母的,但被Scala编译器保留作为特殊标识符使用,所以用户定义的标识符中最好不要包含 $ 字符,尽管能够编译通过。另外,虽然下划线可以用来做为标识符,但同样也有很多其他非标识符用法,所以也最好避免在标识符中含有下划线
Java中常量习惯全大写,且单词之间使用下划线连接,但Scala里习惯第一个字母必须大写,其他还是驼峰形式
操作符标识符:由一个或多个操作符组成,操作符是一些如 +、:、?、~ 或 # 的可打印ASCII字符(精确的说,应该是除字母、数字、括号、方括号、花括号、单引号、双引号、下划线、句号、分号、冒号、回退字符\b),以下是一些操作符标识符:
+、++、:::、<?>、:->
Scala编译器内部会将操作符标识符转换成含有 $ 字符的Java标识符,如操作符标识符 :-> 将被编译器转换成相应Java标识符 $colon$minus$greater (colon:冒号,minus:负号,greater:大于),如果要从Java代码访问这个标识符,则应该使用这个转换后的标识符,而不是原始的
在Java里 x<-y 会被拆分成4个词汇符号,所以与 x < - y 一样,但在Scala里,<- 将被作为一个标识符,所以会被拆分成3个词汇,从而得到 x <- y,如果想要拆分成 < 与 – 的话,需要在 < 与 – 之间加上一个空格
混合标识符:由字母、数字组成,后面跟下划线和一个操作符标识符,如 unary_+ 被用做定义一元操作符 + 的方法名,myvar_= 被用做定义赋值操作符 = 的方法名(myvar_=是由编译器用来支持属性property的)
字面量标识符:是用反引 `...` 包括的任意字符串,如 `x` `<clinit>` `yield`,因为yield在Scala中是保留字,所以在Scala中不能直接调用java.lang.Thread.yield()(使当前线程从运行状态变为就绪状态),而是这样调用java.lang.Thread.`yield`()
有理数是一个整数a和一个非零整数b的比,例如3/8,通则为a/b,又称作分数。
0也是有理数。有理数是整数和分数的集合,整数也可看做是分母为1的分数。
有理数的小数部分是有限或为无限循环的数。无理数的小数部分是无限不循环的数。
与浮点数相比较,有理数的优势是小数部分得到了完全表达,没有舍入或估算
下面设计分数这样的类:
class Rational(n: Int, d: Int) // 分子:n、分母:d
如果类没有主体,则可以省略掉花括号。括号里的n、d为类参数,并且编译器会创建带这两个参数的主构造器(有主就有从)
Scala编译器将把类的内部任何即不是字段也不是方法的定义代码编译到主构造器中,如:
class Rational(n: Int, d: Int) {
println("Created " + n + "/" + d)
}
scala> new Rational(1, 2)
Created 1/2
res0: Rational = Rational@90110a
Rational 类继承了定义在 java.lang.Object 类上的 toString方法,所以打印输出了“Rational@90110a”。重写toString方法:
class Rational(n: Int, d: Int) {
override def toString = n + "/" + d
}
scala> val x = new Rational(1, 3)
x: Rational = 1/3
构造时,分母非0检查:
class Rational(n: Int, d: Int) {
require(d != 0) //此句会放入主构造器中
override def toString = n + "/" + d
}
require方法为scala包中Predef对象中定义的方法,编译器会自动引入到源文件中,所以可直接使用不需导入。传入的如果是false时,会抛java.lang.IllegalArgumentException异常,对象构造失败
实现add方法:
class Rational(n: Int, d: Int) {
require(d != 0)
override def toString = n + "/" + d
def add(that: Rational): Rational =
new Rational(n * that.d + d * that.n, d * that.d)
}
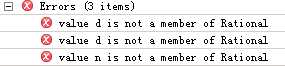
由于n、d只是类参数,在整个类范围内是可见(但因为只是构造器的一部分,所以编译器不会为它们自动构造字段),但只能被调用它的对象访问,其他对象不能访问。代码中的that对象并不是调用add方法的对象,所以编译时出错:
所以需要将n、d转存到字段成员中才可访问:
class Rational(n: Int, d: Int) {
require(d != 0)
private val numer: Int = n //与Java一样,私有的也可以在同一类中的所有对象中访问
private val denom: Int = d
override def toString = n + "/" + d
// 1/2 + 2/3 = (1*3)/(2 *3) + (2*2)/(3*2)
def add(that: Rational): Rational =
new Rational(n * that.denom + d * that.numer, d * that.denom)
}
scala> val oneHalf = new Rational(1, 2)
oneHalf: Rational = 1/2
scala> val twoThirds = new Rational(2, 3)
twoThirds: Rational = 2/3
scala> oneHalf add twoThirds
res0: Rational = 7/6
比大小:
def lessThan(that: Rational) = numer * that.denom < that.numer * denom
返回较大的:
def max(that: Rational) = if (lessThan(that)) that else this
在Scala里除主构造器之外的其它构造器都是从构造器。
当分母为1时,只需传入分子,分母固定为1,下面增加一个这样的从构造器:
def this(n: Int) = this(n, 1)
Scala 的从构造器以 def this(...) 定义形式开头。每个从构造器的第一个语句都是调用同类里的其他构造器(主构造器或者其它从构造器),但最终都会以调用主构造器而结束,此因主构造器是类的唯一入口点。在Java中,构造器的第一个语句只有两个选择:要么调用同类的其他构造器,要么直接调用父类的构造器,如果省略,则默认为super(),即默认会调用父类的无参默认构造器
加入分数最简形式,形如66/42可以简化为11/7,分子分母同时除以最大公约数6:
class Rational(n: Int, d: Int) {
//此句会放入主构造器中
require(d != 0)
//分子与分母的最大公约数
private val g = gcd(n.abs, d.abs)
private val numer: Int = n / g //与Java一样,私有的也可以在同一类中的所有对象中访问
private val denom: Int = d / g
//从构造器
def this(n: Int) = this(n, 1)
override def toString = numer + "/" + denom
// 1/2 + 2/3 = (1*3)/(2 *3) + (2*2)/(3*2)
def add(that: Rational): Rational =
new Rational(numer * that.denom + denom * that.numer, denom * that.denom)
//求两个数的最大公约数
private def gcd(a: Int, b: Int): Int = if (b == 0) a else gcd(b, a % b)
}
object T {
def main(args: Array[String]): Unit = {
println(new Rational(66, 42)) //11/7
val oneHalf = new Rational(1, 2)
val twoThirds = new Rational(2, 3)
println(oneHalf add twoThirds) //7/6
}
}
定义操作符:到目前为止,已实现了分数相加的方法add,但不能像Scala库里面数字类型那样使用 + 操作符来完成两个分数的相加,其实将add方法名改为 + 即可:
class Rational(n: Int, d: Int) {
//此句会放入主构造器中
require(d != 0)
//分子与分母的最大公约数
private val g = gcd(n.abs, d.abs)
private val numer: Int = n / g //与Java一样,私有的也可以在同一类中的所有对象中访问
private val denom: Int = d / g
//从构造器
def this(n: Int) = this(n, 1)
override def toString = numer + "/" + denom
// 1/2 + 2/3 = (1*3)/(2 *3) + (2*2)/(3*2)
def +(that: Rational): Rational =
new Rational(numer * that.denom + denom * that.numer, denom * that.denom)
//实现乘法
def *(that: Rational): Rational =
new Rational(numer * that.numer, denom * that.denom)
//求两个数的最大公约数
private def gcd(a: Int, b: Int): Int = if (b == 0) a else gcd(b, a % b)
}
object T {
def main(args: Array[String]): Unit = {
val x = new Rational(1, 2)
val y = new Rational(2, 3)
println(x + x * y) //5/6
println((x + x) * y) //2/3
}
}
上面只是针对分数Rational进行加、乘运行,不能与Int进行运算,下面对这些方法进行重载,并加上减、除运算:
class Rational(n: Int, d: Int) {
//此句会放入主构造器中
require(d != 0)
//分子与分母的最大公约数
private val g = gcd(n.abs, d.abs)
private val numer: Int = n / g //与Java一样,私有的也可以在同一类中的所有对象中访问
private val denom: Int = d / g
//从构造器
def this(n: Int) = this(n, 1)
override def toString = numer + "/" + denom
//加: 1/2 + 2/3 = (1*3)/(2 *3) + (2*2)/(3*2)
def +(that: Rational): Rational =
new Rational(numer * that.denom + denom * that.numer, denom * that.denom)
def +(i: Int): Rational = new Rational(numer + i * denom, denom)
//减: 1/2 - 2/3 = (1*3)/(2 *3) - (2*2)/(3*2)
def -(that: Rational): Rational = new Rational(numer * that.denom - that.numer * denom, denom * that.denom)
def -(i: Int): Rational = new Rational(numer - i * denom, denom)
//乘:1/2 * 2/3 =(1*2)/(2*3)
def *(that: Rational): Rational =
new Rational(numer * that.numer, denom * that.denom)
def *(i: Int): Rational = new Rational(numer * i, denom)
//除:1/2 / 2/3 =(1*3)/(2*2)
def /(that: Rational): Rational = new Rational(numer * that.denom, denom * that.numer)
def /(i: Int): Rational = new Rational(numer, denom * i)
//求两个数的最大公约数
private def gcd(a: Int, b: Int): Int = if (b == 0) a else gcd(b, a % b)
}
object T {
def main(args: Array[String]): Unit = {
println(new Rational(2, 3) * 2)// 4/3
}
}
上面只能使用 new Rational(2, 3) * 2 ,而不能倒过来 2 * new Rational(2, 3),因为Int类就没有针对 Rational类型进行运算的方法,Rational不是Scala的标准类型,如果在使用2 * new Rational(2, 3) 这种形式,则需要在使用前进行隐式转换,则Int类型转换为Rational类型:
//需要在使用之前定义从Int到Rational的隐式转换方法
implicit def int2Rational(x: Int) = new Rational(x)
println(2 * new Rational(2, 3)) // 4/3
Scala的控制结构特点都是有返回值的
传统方式:
var filename = "default.txt"
if (!args.isEmpty)
filename = args(0)
其实可以省去变量var:
val filename = if (!args.isEmpty) args(0) else "default.txt"
//计算最大公约数:(6,9)= 3
def gcdLoop(x: Long, y: Long): Long = {
var a = x
var b = y
while (a != 0) {
val temp = a
a = b % a
b = temp
}
b
}
//循环多控制台读取输入行
var line = ""
do {
line = readLine()
println("Read: " + line)
} while (line != "")
while和do-while结构之所以称为“循环”,而不是表达式,是因为它们不能产生有意义的结果,循环结果返回结果的类型是Unit,写做()。()的存在是Scala的Unit不同于Java的void的地方:
//返回值为空
def greet() { println("hi") }
def main(args: Array[String]): Unit = {
println(greet() == ())//hi true
}
另外,在Java等编程语言中,赋值语句本身会返回被赋予的那值:
String line = "";
System.out.println(line = "hello");// hello
但在Scala中,赋值语句本身不会再返回被赋予的那值,而是Unit:
var line = ""
println(line = "ho") // ()
所以下面从控制台读取将永远不能结束:
var line = ""
while ((line = readLine()) != "") // 不起作用,因为赋值语句固定返回为Unit()
println("Read: " + line)
由于while循环不产生值,因此在纯函数式语言中不推荐使用,它适合于传统指令式编程,而使用递归的函数式风格可以替代while。下面使用这种递归的函数式风格来代替上面使用while指令式风格求最大公约数:
//计算最大公约数,使用递归函数实现
def gcd(x: Long, y: Long): Long =
if (y == 0) x else gcd(y, x % y)
Java传统做法:
File[] filesHere = new java.io.File(".").listFiles();
for (int i = 0; i < filesHere.length; i++) {
System.out.println(filesHere[i]);
}
Scala枚举当前目录下的所有文件(包括目录):
val filesHere = new java.io.File(".").listFiles
![]()
for (file <- filesHere)
println(file)

Java1.5以后也有类型的语法:
File[] filesHere = new java.io.File(".").listFiles();
for (File file : filesHere) {
System.out.println(file);
}
对任何集合类型都可以枚举,如Rang:
for (i <- 1 to 4)
println("Iteration " + i)

for (i <- 1 until 4)//不包括边界4
println("Iteration " + i)
val filesHere = new java.io.File(".").listFiles
//也可按传统方式通过索引遍历数组元数,但不推荐这样使用
for (i <- 0 to filesHere.length - 1)
println(filesHere(i))
在for语句中添加if过滤器:
val filesHere = (new java.io.File(".")).listFiles
//只打印出后缀名为 .project 的文件
for (file <- filesHere if file.getName.endsWith(".project"))
println(file)
也可以将if语句拿出来写在循环体中,但不推荐:
for (file <- filesHere)
if (file.getName.endsWith(".project"))
println(file)
可以添加多个过滤器:
for (file <- filesHere if file.isFile if file.getName.endsWith(".project"))
println(file)
for语句中可以使用多个 <- 提取符形成嵌套循环。
下面外层循环是针对扩展名为.classpath的文件进行循环,然后读取每个文件中含有con字符的文本行:
val filesHere = (new java.io.File(".")).listFiles
def fileLines(file: java.io.File) =
scala.io.Source.fromFile(file).getLines.toList
def grep(pattern: String) =
for (
file <- filesHere if file.getName.endsWith(".classpath"); //循环文件
line <- fileLines(file) if line.trim.matches(pattern) //循环文本行
) println(file + ": " + line.trim)
grep(".*con.*")
注:嵌套之间要使用分号分隔,不过可以使用花括号来代替小括号,此时嵌套之间的分号就可以省略了:
def grep(pattern: String) =
for {
file <- filesHere if file.getName.endsWith(".classpath")
line <- fileLines(file) if line.trim.matches(pattern)
} println(file + ": " + line.trim)
如果某个方法多次用,可以将其先赋给某个val变量,这样只需计算一次,如上面两处调用line.trim:
def grep(pattern: String) =
for {
file <- filesHere if file.getName.endsWith(".classpath")
line <- fileLines(file)
trimmed = line.trim //可以定义val中间变量,val关键字可以省略
if trimmed.matches(pattern)
} println(file + ": " + trimmed)
针对for的每次循环,yield 会把当前的元素记下来,每次循环返回的结果被添加到另一集合中(被循环的原来集合不会被修改),当循环执行完后,这个集合将被返回,这个集合的类型就是你迭代的集合类型,如果被循环的是 Map,返回的就是 Map,被循环的是 List,返回的就是 List,以此类推。
scala> for (i <- 1 to 5) yield i
res0: scala.collection.immutable.IndexedSeq[Int] = Vector(1, 2, 3, 4, 5)
每个元素翻倍:
scala> for (i <- 1 to 5) yield i * 2
res1: scala.collection.immutable.IndexedSeq[Int] = Vector(2, 4, 6, 8, 10)
scala> val a = Array(1, 2, 3, 4, 5)
a: Array[Int] = Array(1, 2, 3, 4, 5)
scala> for (e <- a) yield e
res2: Array[Int] = Array(1, 2, 3, 4, 5)
正如你所见, 例子中被 yield 的是 Array[Int], 而更早的例子中返回的类型是 IndexedSeq[Int].
scala> val a = Array(1, 2, 3, 4, 5)
a: Array[Int] = Array(1, 2, 3, 4, 5)
scala> for (e <- a if e > 2) yield e
res3: Array[Int] = Array(3, 4, 5)
如上, 加上了 "if e > 2" 作为守卫条件用以限制得到了只包含了三个元素的数组.
yield与for一样是关键字,它应该放在循环体最前面,如果循环体有多个语句时,可以使用花括号包起来,yield放在花括号外:
for {子句} yield {循环体}
val half =
if (n % 2 == 0) n / 2
else
throw new RuntimeException("n must be even")
import java.io.FileReader
import java.io.FileNotFoundException
import java.io.IOException
var f: FileReader = null
try {
f = new FileReader("input.txt")
// Use and close file
} catch {
case ex: FileNotFoundException =>
// Handle missing file
case ex: IOException =>
// Handle other I/O error
} finally {
f.close() // Be sure to close the file
}
Scala里不需要你捕获检查异常:checked exception,或把它们声明在throws子句中
和其它大多数Scala控制结构一样,try-catch-finally也产生值,Scala的行为与Java的差别仅源于Java的try-finally不产生值
import java.net.URL
import java.net.MalformedURLException
def urlFor(path: String) =
try {
new URL(path)
} catch {
case e: MalformedURLException =>
new URL("http://www.scalalang.org")
}
如果未捕获到异常,则没有值
finally子句即使计算得到值,也会被抛弃,所以一般不在finally计算值
当有显示的返回时,以最后返回的为准
def f(): Int = try { return 1 } finally { return 2 }
println(f()) //2
否则:
def g(): Int = try { 1 } finally { 2 }
println(g()) //1
因此,finally子句不要返回值,而只作如关闭资源等使用
val firstArg = if (args.length > 0) args(0) else ""
firstArg match {
case "salt" => println("pepper")
case "chips" => println("salsa")
case "eggs" => println("bacon")
case _ => println("huh?")
}
下划线表示其它
不像Java那样,firstArg可以是任何类型,而不只是整型或枚举,示例中是字符串。另外,每个可选项最后并没有break,这是隐含的
match表达式还可以产生值:
val firstArg = if (!args.isEmpty) args(0) else ""
val friend =
firstArg match {
case "salt" => "pepper"
case "chips" => "salsa"
case "eggs" => "bacon"
case _ => "huh?"
}
println(friend)
不再使用break和continue
Scala允许你在嵌套范围内定义同名变量
大括号通常引入了一个新的范围,所以任何定义在花括号里的东西在括号之后就脱离了范围(但有个例外,因为嵌套for语句可以使用花括号来代替小括号,所以此种除外)
然而,你可以在一个内部范围内定义与外部范围里名称相同的变量:
val a = 1; //在这里要加上分号,因为此处不能推导
{
val a = 2
println(a) //2
}
println(a) //1
与Scala不同,Java不允许你在内部范围内创建与外部范围变量同名的变量。在Scala程序里,内部变量被说成是遮蔽:shadow了同名的外部变量,因为在内部范围内外部变量变得不可见了
def processFile(filename: String, width: Int) {
def processLine(filename: String, width: Int, line: String) {//只能在processFile方法中使用,外部无法访问
if (line.length > width) print(filename + ": " + line)
}
val source = Source.fromFile(filename)
for (line <- source.getLines) {
processLine(filename, width, line)
}
}
本地函数可以访问所在外层函数的参数,所以上面可以改成:
def processFile(filename: String, width: Int) {
def processLine(line: String) {
if (line.length > width) print(filename + ": " + line)
}
val source = Source.fromFile(filename)
for (line <- source.getLines)
processLine(line)
}
递增操作的字面量函数:
(x: Int) => x + 1
=>指明这个函数把左边的东西(任何整数 x)转变成右边的东西( x + 1),左边是参数,右边是函数体
编译时函数字面量会被编译进类源码中,并从FunctionN继承(如Function0是不带参数的函数,Function1是带一个参数的函数等等,具体继承自哪个需要根据参数个数来确定),在运行期会实例化为具体的某个函数值(函数字面量与值好比类和对象之间的关系)
函数值是对象,所以可以将其赋给变量,并且可以参数变量调用:
scala> var increase = (x: Int) => x
+ 1
increase: (Int) => Int =
<function> //
函数返回值为Int,函数体最后一条语句即返回值
scala> increase(10)
res0: Int = 11
函数体有多条语句时,使用大括号:
scala> increase = (x: Int) => {
println("We")
println("are")
println("here!")
x + 1 // 函数返回值为Int,函数体最后一条语句即返回值
}
increase: (Int) => Int =
<function>
scala> increase(10)
We
are
here!
res4: Int = 11
Iterable 是 List, Set, Array,还有 Map 的共有超类,foreach 方法就定义在其中,它可以用来针对集合中的每个元素应用某个函数:
scala> val someNumbers = List(-11, -10, -5, 0, 5, 10)
someNumbers: List[Int] = List(-11, -10, -5, 0, 5, 10)
scala> someNumbers.foreach((x: Int) =>
println(x)) // 只是简单的打印每个元素
-11
-10
-5
0
5
10
集合中还有filter函数也是可以传递一个函数的,用来过滤元素,传递进去的函数要求返回Boolean:
scala> someNumbers.filter((x: Int) => x
> 0)
res6: List[Int] = List(5, 10)
去除参数类型,以及外面的括号:
someNumbers.filter((x: Int) => x
> 0)
因数函数是应用于集合中元素,所以会根据集合元素类型来推导参数类型。
如果某个参数只在函数体里出现一次,则可以使用下划线 _ 来替换这个参数:
scala> someNumbers.filter(_ > 0)
res9: List[Int] = List(5, 10)
_ > 0 相当于x => x > 0,遍历时会使用当前相应元素来替换下划线(有点像在下划线上填写内容一样,下划线有留空的意思,所以用作占位符)
有多少个下划线,则就表示有多少个不同的参数。多个占位符时,第一个下划线表示第一个参数,第二个下划线表示第二个参数,以此类推;所以同一参数多处出现时是无法使用这种占位符来表示的。
使用占位符时,有时无法推导出类型,如:
scala> val f = _ + _
此时需明确写出类型:
scala> val f = (_: Int) + (_: Int)
前面的例子是在字面量函数中使用下划线 _ 占位符,它出现在函数体中,代表具体某一个参数。你也可以将下划线用在某个函数参数中,此时用来代替该函数的整个参数列表(有多少个参数,则代表多少个参数),如println(_) ,或println _ ,或更简洁println :
someNumbers.foreach(println _)
这等效于:
someNumbers.foreach(x => println(x))
这个例子的下划线不是单个参数的占位符,而是整个参数列表的占位符(虽然示例中是只带有一个参数的println函数)
由于someNumbers.foreach方法要求传入的就是函数,所以此时下划线也可以直接省略,更简洁的写法:
someNumbers.foreach(println)
注:只能在需要传入函数的地方去掉下划线,其他地方不能,如后面的sum函数:
scala> val c = sum
<console>:12: error: missing argument list for method sum
Unapplied methods are only converted to functions when a function type is expected.
You can make this conversion explicit by writing `sum _` or `sum(_,_,_)` instead of `sum`.
val c = sum
^
上面以这种方式使用下划线时,你就是正在写一个偏应用函数(Partially applied functions)。
当你调用某个带有参数的函数时,实质上是把这个函数应用到这些参数上:
scala> def sum(a: Int, b: Int, c: Int) = a + b
+ c
sum: (Int,Int,Int)Int
你就可以把函数 sum 应用到参数 1, 2 和 3 上,如下:
scala> sum(1, 2, 3)
res12: Int = 6
偏应用函数是一种表达式,你不需要提供函数需要的所有参数(或只提供部分,或不提供任何参数)。比如在定义字面量函数时,在体中调用带有参数的函数时可以不提供任何参数,而是使用该函数的偏应用表达式(做法是在sum后面接一个下划线),然后可以把这个表达式存放到变量中,如下面定义的a函数变量:
scala> val a = sum _
a: (Int, Int, Int) => Int = <function> //注:此时返回的是带有3个参数的函数,即a为带有3个参数的函数变量,在调用时才能确定参数值
scala> a(1, 2, 3) //等到在使用时才传入具体参数值
res13: Int = 6
scala> var b = sum(1,2,3); //如果在定义时就传入了具体值,则返回的就是具体的值了,而非函数,所以此时b变量是Int变量,而非函数变量
b: Int = 6
编译器会将 sum _ 偏应用函数表达式 编译成从Function3扩展的类,并且有一个带3个参数的apply方法(之所以带3个参数是因为 sum _ 表达式缺少的参数为3个)。运行时会实例化该类,将实例化出来的函数值对象赋值给a变量,随后编译器把表达式a(1, 2, 3) 翻译成对函数值a的apply方法调用,再由这个apply方法去真正调用sum函数,因此a(1, 2, 3)等效于下面:
scala> a.apply(1, 2, 3)
res14: Int = 6
这种由下划线代替整个参数列表的另一用途就是:可以将def定义的方法转换为函数值的方式,尽管不能直接将def定义的方法或嵌套函数赋值给函数变量,或当做参数传递给其它的方法,但是如果把方法或嵌套函数通过在名称后面加一个下划线的方式包装在函数值中,就可以做到了
上面的 sum _ 就是偏应用函数,原因就是应用时未指定所有参数。并且还可以部分指定参数,如:
scala> val b = sum(1, _: Int, 3)
b: (Int) => Int = <function>
只缺少中间一个参数,所以编译器会产生一个新的函数类,其 apply 方法带一个参数,所以调用b函数变量时只能传入一个:
scala> b(2)
res15: Int = 6
此时,b(2)相当于调用了b.apply(2),而b.apply(2)再去调用sum(1,2,3)
标签:scala filename 调用 eth weight ges 代参 内容 cto
原文地址:http://www.cnblogs.com/jiangzhengjun/p/6435225.html