标签:算法 没有 one pool 成功 矩阵相乘 var 情况 像素
到目前为止,我们已经大致地介绍了一些新网络
但是,如果你对数据已有一些了解,比如它是一张图片,或者一系列事物,你可以做得更好
想法非常简单,如果你的数据是某种结构,则你的网络没有必要从零开始学习结构,它会表现得更好
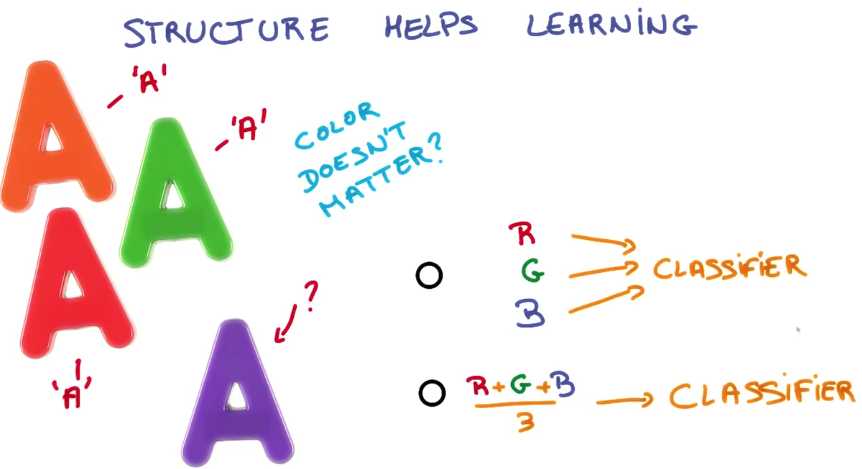
例如,假设你想尝试分类这些字母,你知道颜色并不是让A成为A的重要因素
你认为怎么样会使得你的分类器更容易学习?
一个使用彩色照片的模型还是只使用灰度的模型
直观地说,如果一个字母表现为你从未见过的颜色,当你尝试分类字母时,忽略颜色的特性将使得模型变得更加容易

这是另一个例子,你有一张照片,你想要你的网络表示出照片中有一只猫
猫在图片的哪里并不重要,它仍然是一张有猫的照片

如果要你的网络必须分别学习出猫是在左下角,还是在右上角,这有非常多的工作需要做

如果这样告诉你,准确地讲,不管是在图片的左边还是右边,物体和图像都一样,这就是所谓的平移不变性
不同的位置,相同的猫咪
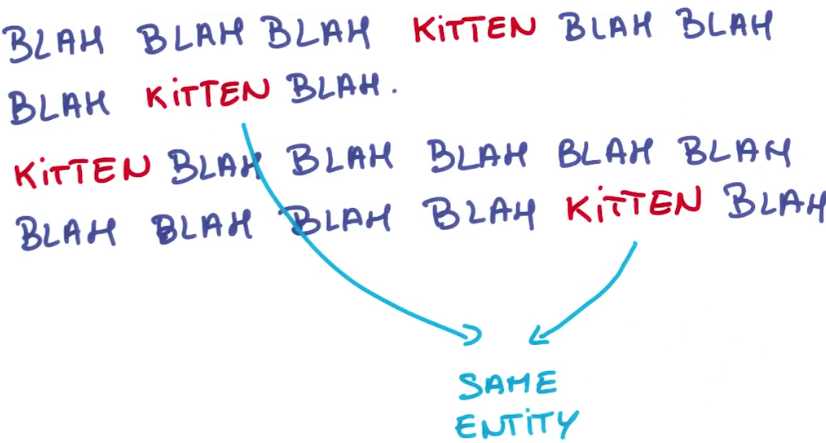
还有另外一个例子,假设你有一长段话谈论猫咪,猫咪的意义是否随它在第一句话,还好第二句话而发生变化呢?
大部分情况不变,因此,如果你尝试一个关于文本的网络
网络学习到的什么是猫咪可被重复使用。而不是每次见到猫咪这个词就要重新学习它

实现这种网络的方法叫做weight sharing权重共享
当你知道两种输入可以获得同样的信息,则你应该共享权重且利用这些输入共同训练权重。这是一种非常重要的思想

Statistical Invariants统计不变性司空见惯,事物的平均值并不随时间或空间发生变化
对于图片,权重共享的思想使我们研究卷积神经网络convolutional networks
一般情况下,对于文本和序列,应当使用词嵌入和循环神经网络
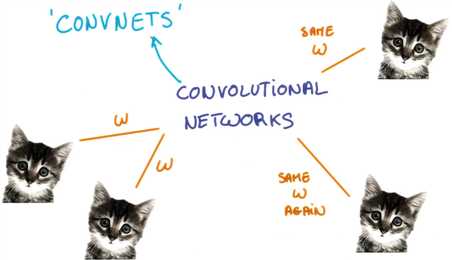
让我们来讨论一下卷积神经网络或者称convnets。convnets是一种空间上共享参数的神经网络
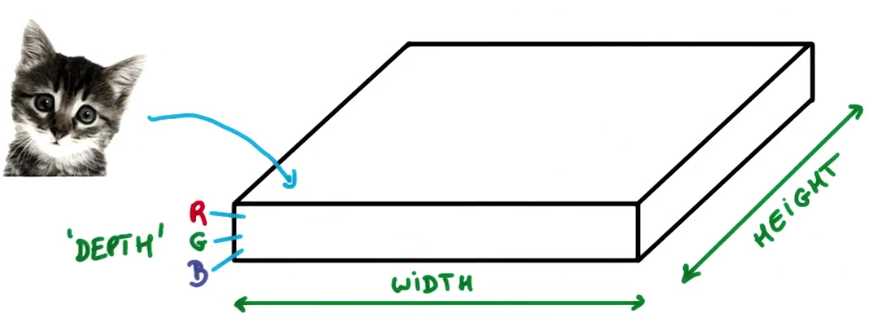
假设你有一张照片,它可以被表示为一个薄饼,它有宽度和高度,且由于天然存在红绿蓝三色,
因此它还拥有深度,在这种情况下,你的输入深度为3
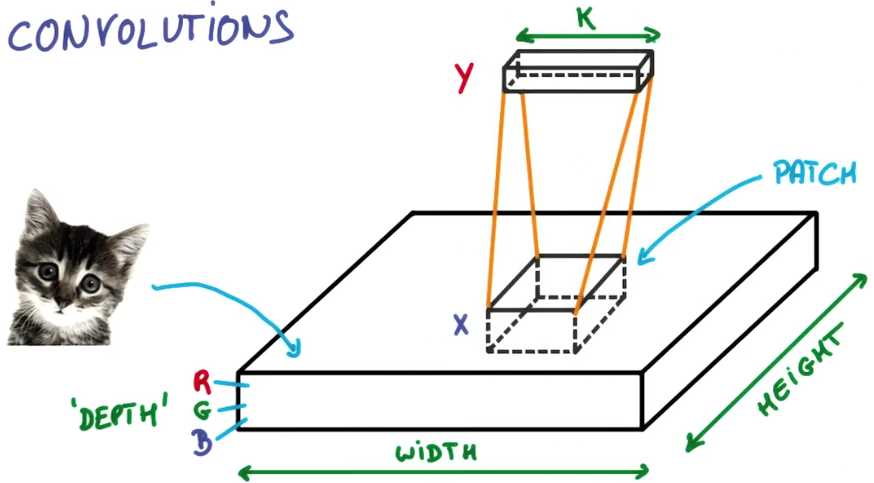
现在假设拿出图片的一小块,运行一个具有K个输出的小神经网络
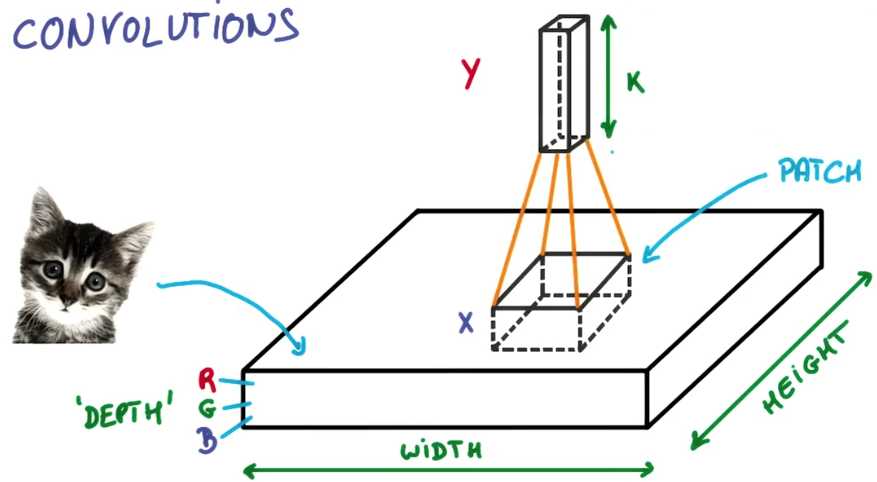
像这样把输出表示为垂直的一小列
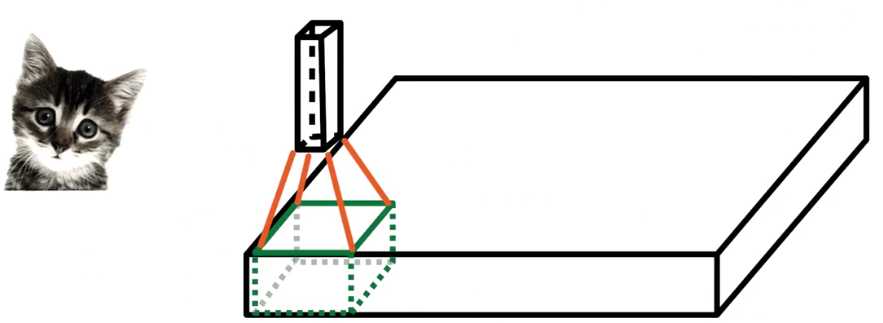
在不改变权重的情况下,把那个小神经网络滑遍整个图片,就像我们拿着刷子刷墙一样水平垂直的滑动
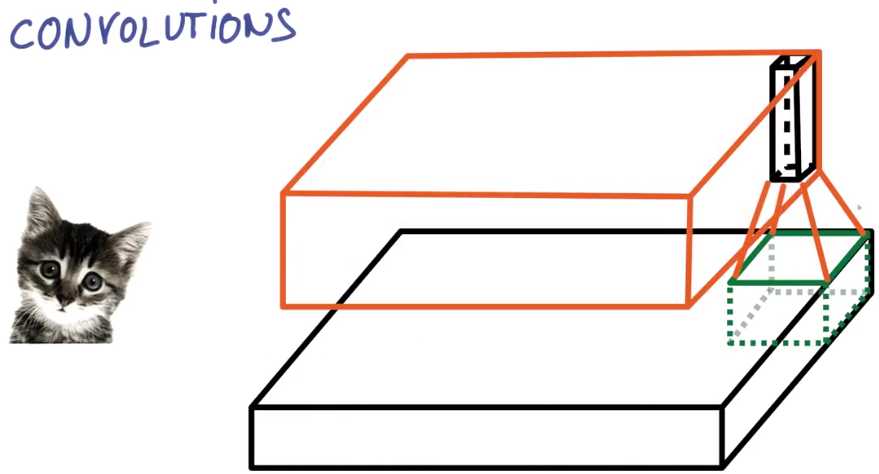
在输出端,我们画出了另一副图像,它跟之前的宽度和高度不同,更重要的是它跟之前的深度不同。
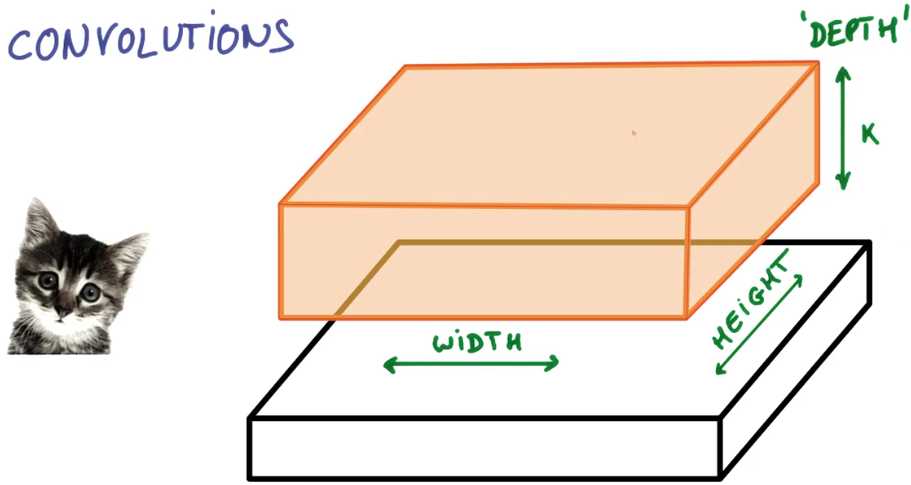
而不是仅仅只有红绿蓝,现在你得到了K个颜色通道,这种操作叫做卷积
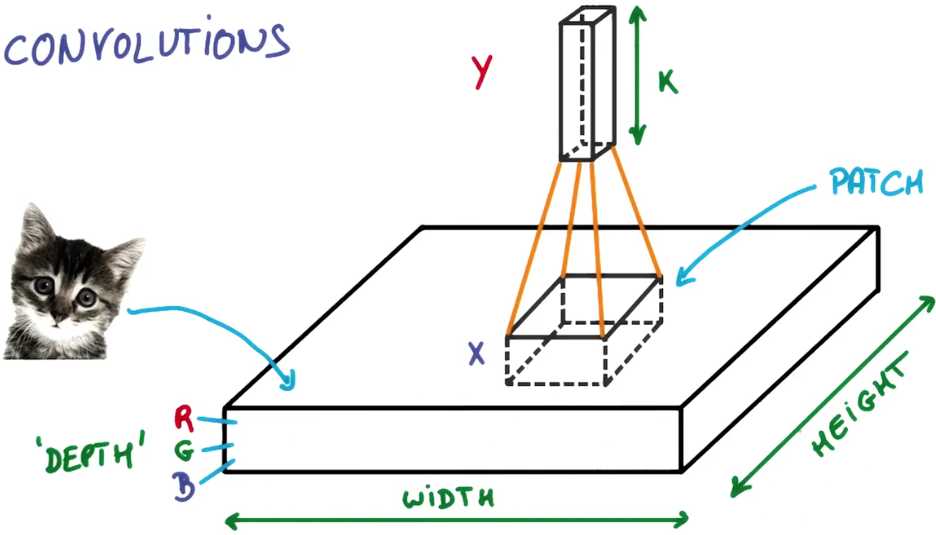
如果你的块大小是整张图片,那它就跟普通的神经网络没有任何区别
正由于我们使用了小块 ,我们有很多小块在空间中共享较少的权重
一个卷积网络是组成深度网络的基础,我们将使用数层卷积而不是数层的矩阵相乘
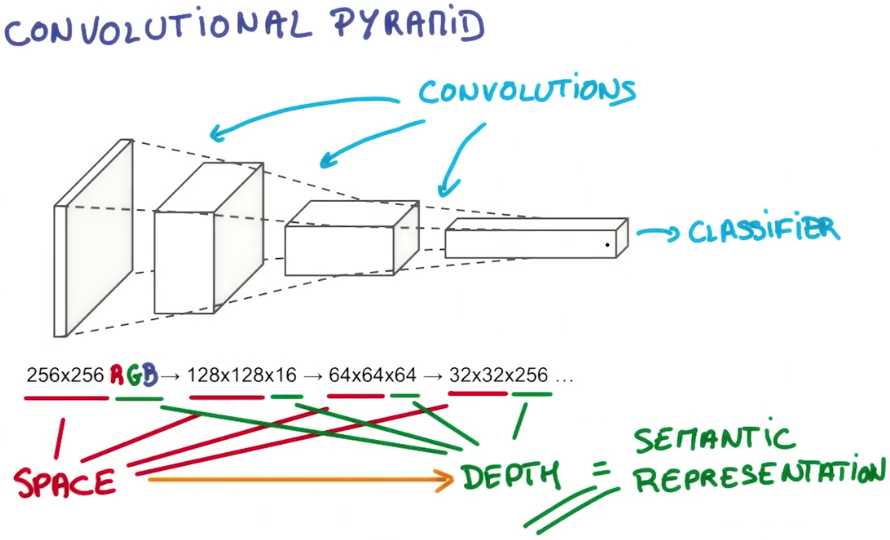
总的想法是让它形成金字塔状,金字塔底是一个非常大而浅的图片,仅包括红绿蓝
通过卷积操作逐渐挤压空间的维度,同时不断增加深度,使深度信息基本上可表示出复杂的语义
你可以在金字塔的顶端实现一个分类器,所有空间信息都被压缩成一个标识
只有把图片映射到不同类的信息保留,这就是总体的思想
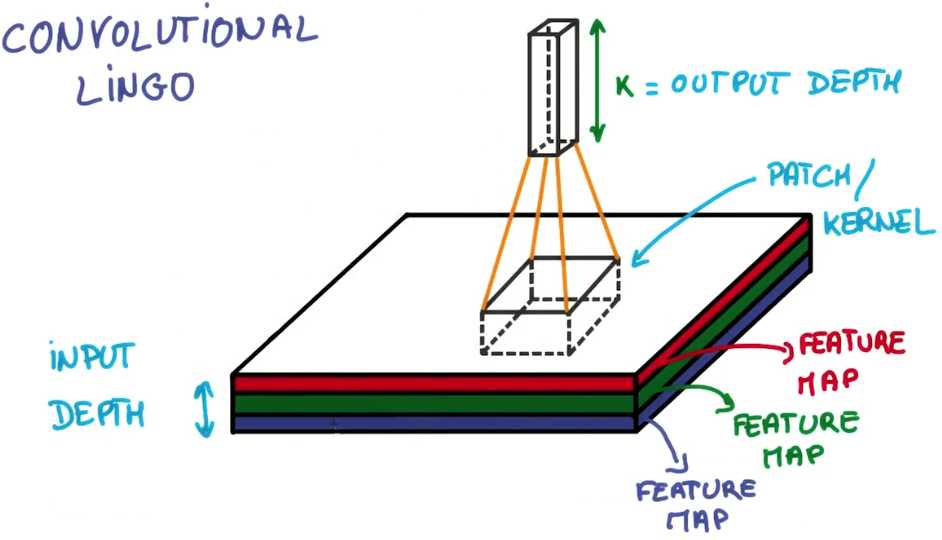
如果你想实现它,必须正确实现很多细节,还需要使用一点点的神经网络语言(lingo)
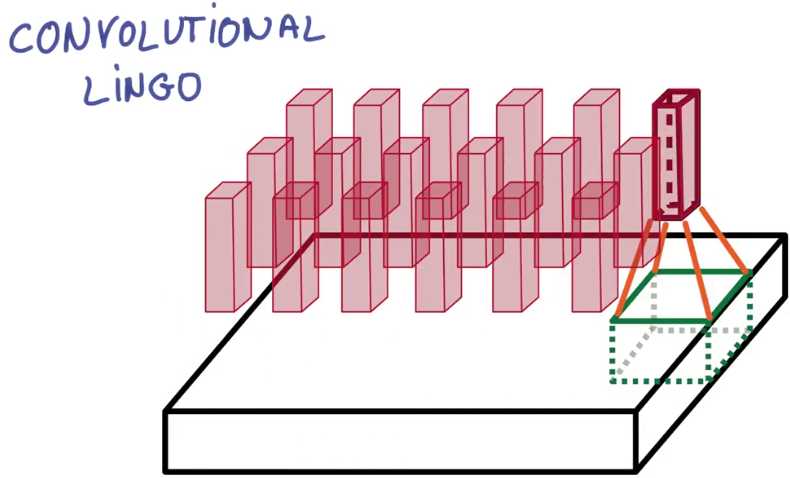
你已经接触到了块(Patch)和深度(depth)的概念,块有时也叫做核(kernel)
你堆栈的每个薄饼都被叫做特征图(feature map)
Each pancake in your stack is called a feature map.
这里你把三个特征映射到K个特征图
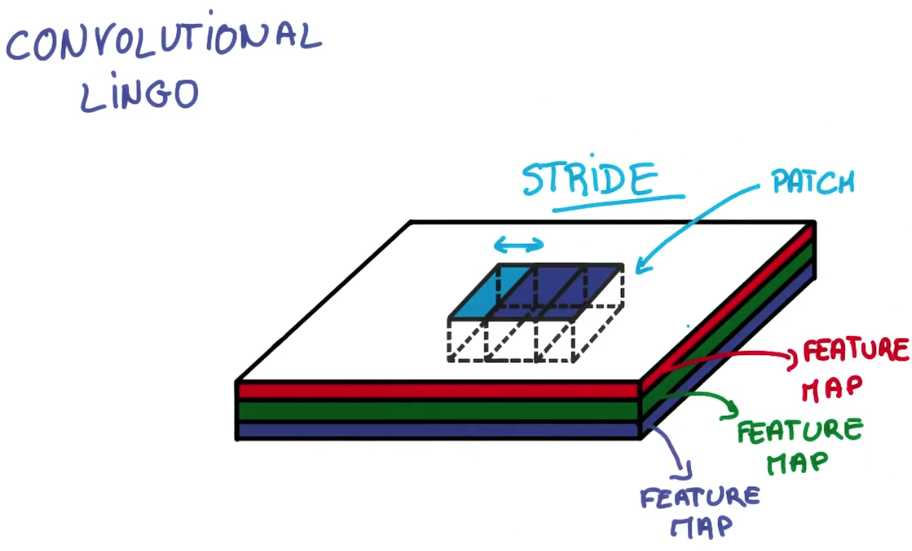
另一个你需要知道的术语是步副(stride),它是当你移动滤波器时平移的像素的数量
(it‘s the number of pixels that you‘re shifting each time you move your filter.)
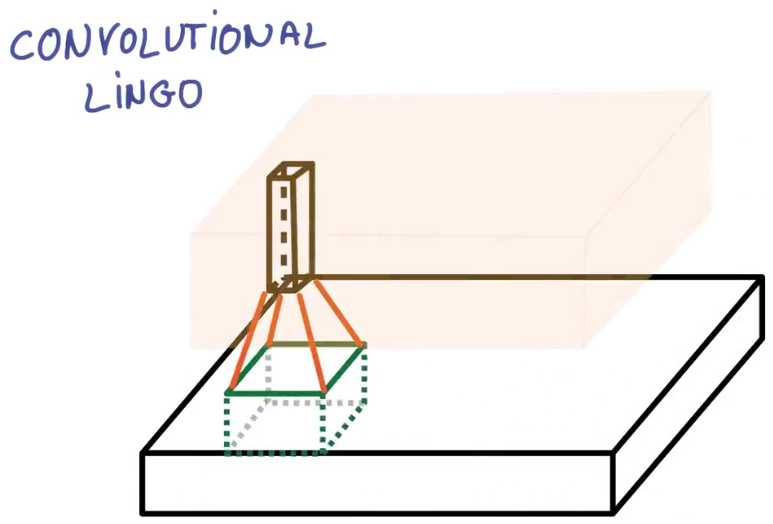
步副为1时得到的尺寸基本上和输入相同,
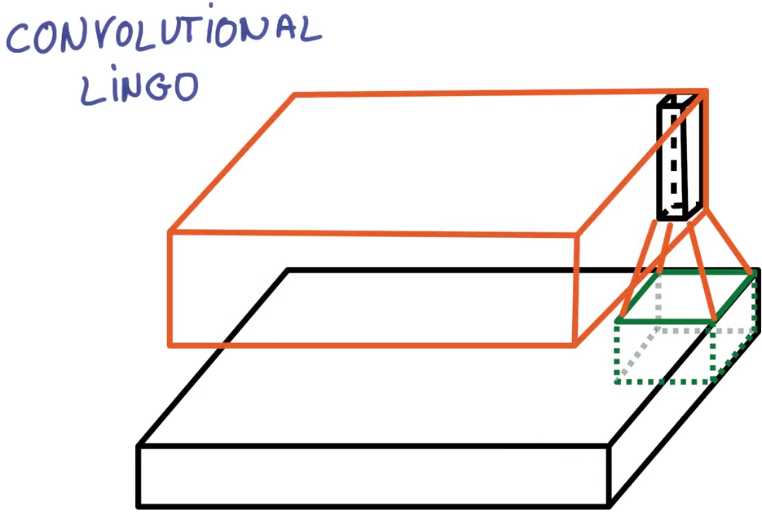
步副为2意味着变为一半的尺寸,
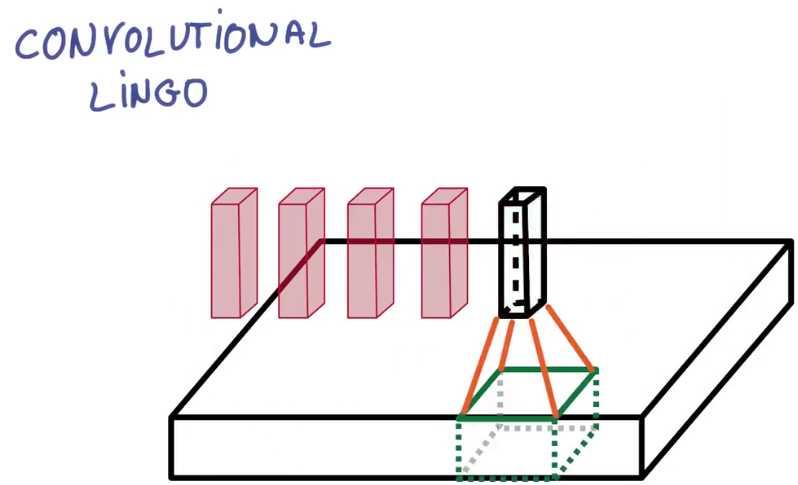
我说基本上,因为它取决于你在边界上怎么做,
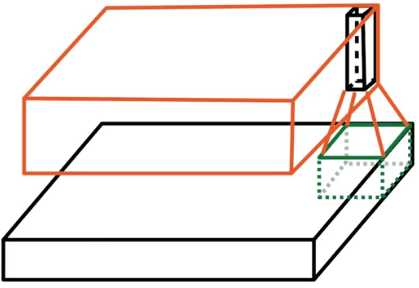
要么你从不超过边界,它常被简称为有效填充(valid padding),
要么你超过边界且使用0填充,这样你会得到同输入相同大小的输出,这常被简称为相同填充(same padding)
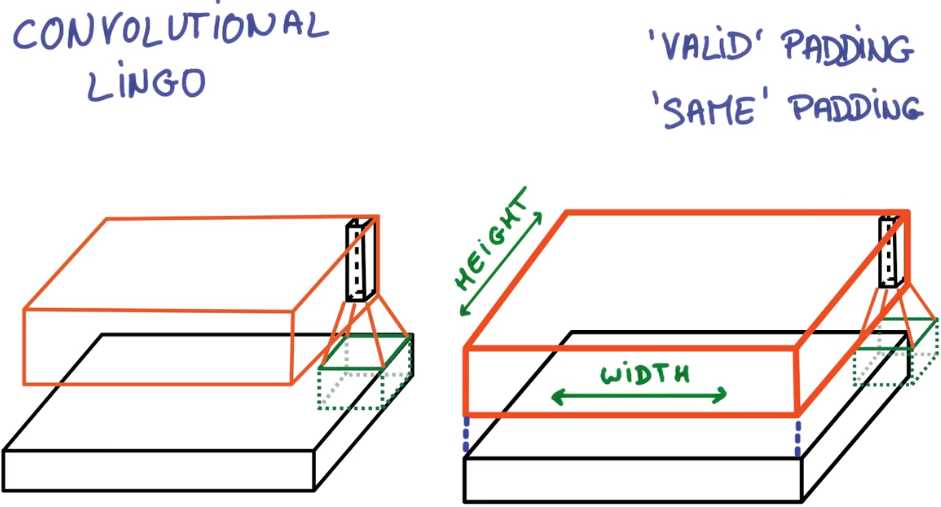
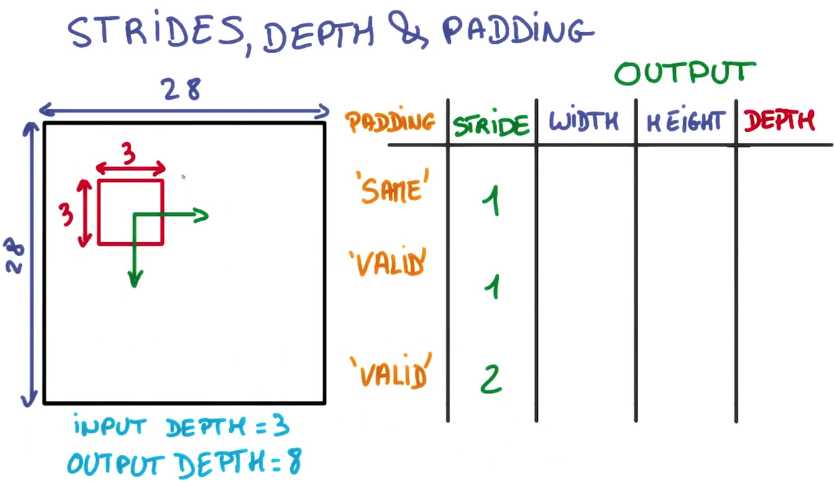
假设你有一个28*28的图片, 你在上面运行一个3×3的卷积操作,卷积操作输入深度为3输出深度为8,
你的输出特征图的维度是多少?当你使用相同填充且步副为1时,使用有效填充且步副为1时
或使用有效填充且步副为2时
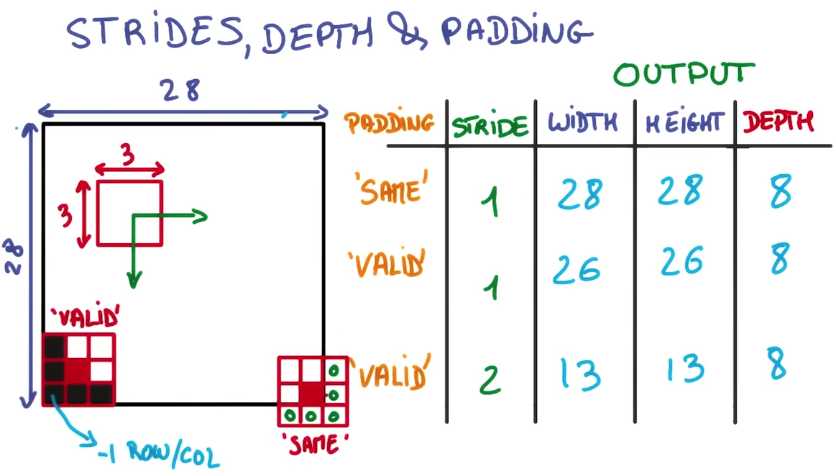
如果你使用所谓的相同填充且步副为1,则输出高度和宽度同输入相同,我们在输入图像中填充零是的尺寸相同
如果你使用所谓的有效填充且步幅为1,则不会存在填充,如果你不使用填充且要相同小的神经网络匹配,
则需要在图片的一边,分别在神经网络中移除一列和一行,因此你在输出特征图中仅剩下26个特征
此外,如果你使用的步幅为2则仅得到一半输出,因此宽度和高度均为13
所有情况下,输出深度都不会变
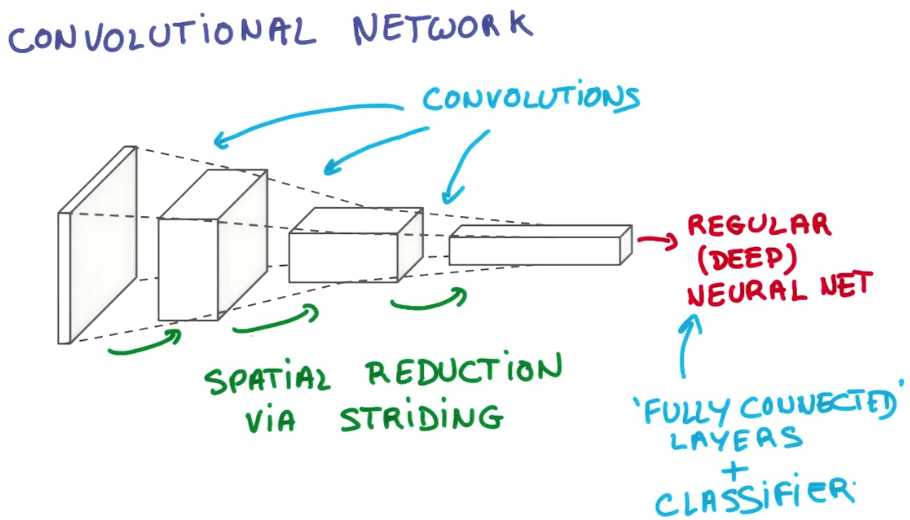
就是这样,你可以像这样构建一个卷积神经网络,你不必自己实现,就可以把卷积叠加起来,
然后尝试使用降维的方法,一层一层的增加网络的深度,
一旦你得到一个既深又窄的表示,把所有的信息连接到几层全连接层,你就可以训练你的分类器了
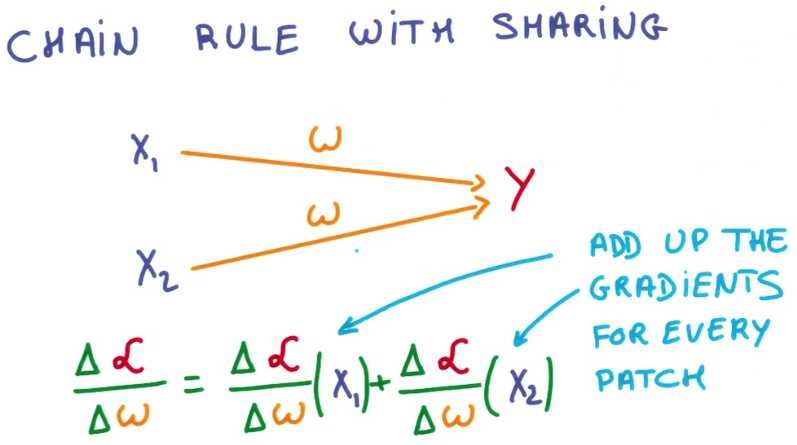
你也许好奇训练中发生了什么,特别是当像这样使用共享权重时,链式公式发生了什么
其实啥也没发生,公式就是能正常工作
你只是将图片中所有位置的微分叠加了起来,

现在你看到一个简单的卷积神经网络,我们可以做很多的事情来提升它
我们将讨论其中的三种:pooling、one by one convolutions、inception
池化、1×1卷积、和更高级一点的东西,叫做inception结构
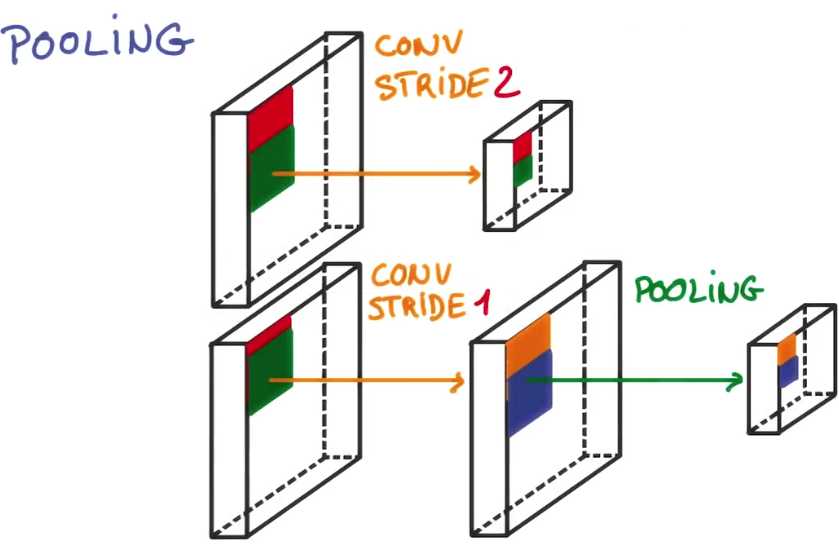
第一个改进是用更好的方法降低,卷积神经网络中的特征图的空间范围,
直到现在,我们已经使用调整的步幅来平均滤波器,(we‘ve used striding to shift the filters by a few pixel each time)
从而降低特征图的尺寸,这是对图像降低采样率的一种非常有效的方法,它移除了很多信息,
如果我们不采用在两个卷积之间使用步幅调整,而依然执行一个非常小的步幅,比方说1
但是我们通过某种方法把相临近的卷积结合在一起,这种操作就叫做池化,有几种方法可以实现它
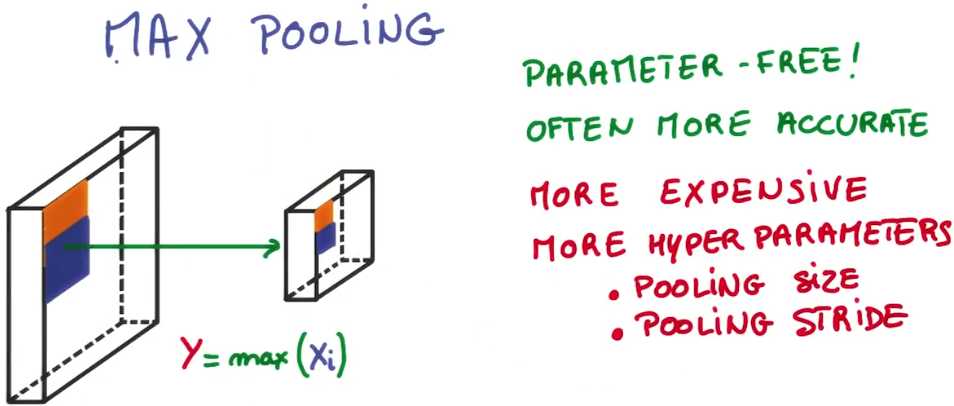
最常用的是最大池化,在特征图的每一个点,查到它周围很小范围的点,计算附近所有点的最大值,
使用最大池化有很多优点,
首先它没有增加参数数量 ,因此不必担心会导致容易过拟合
其次,它常常简单的产生了更精确的模型,
然而由于在非常低的步幅下进行卷积,模型必然需要更多的计算量,
且你有更多的超参数需要调整,例如池化区域尺寸,池化步幅,它们不必完全一样,
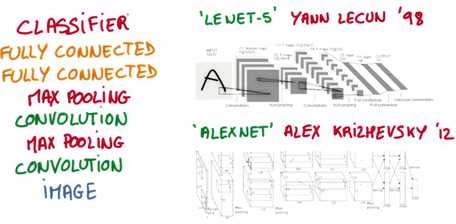
一种典型的卷积神经网络结构为几层的卷积和池化的交替,然后在最末端连接几层全连接层,
第一个使用这种结构的著名模型是LENET-5,它是1998年由Yann Lecun在字母识别中设计的,
高级的卷积神经网络,如著名的ALEXNET在2012年赢得了ImageNet物体识别挑战赛,就使用了一种非常类似的结构
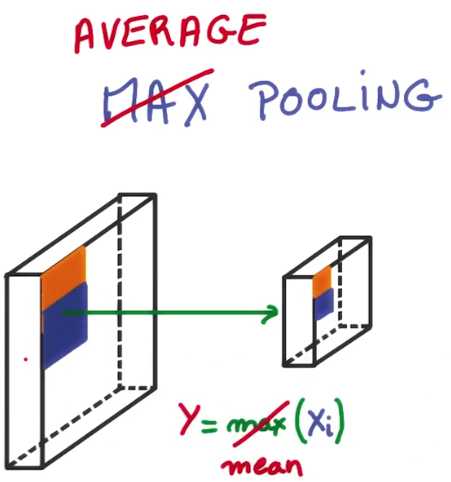
另一种值得注意的形式是平均池化,相比于采用最大值,它使用了在窗口附近一片区域的平均值
它有点像提供了下面这个特征图的 一个低分辨率的视图,不久后我们将利用这种优点
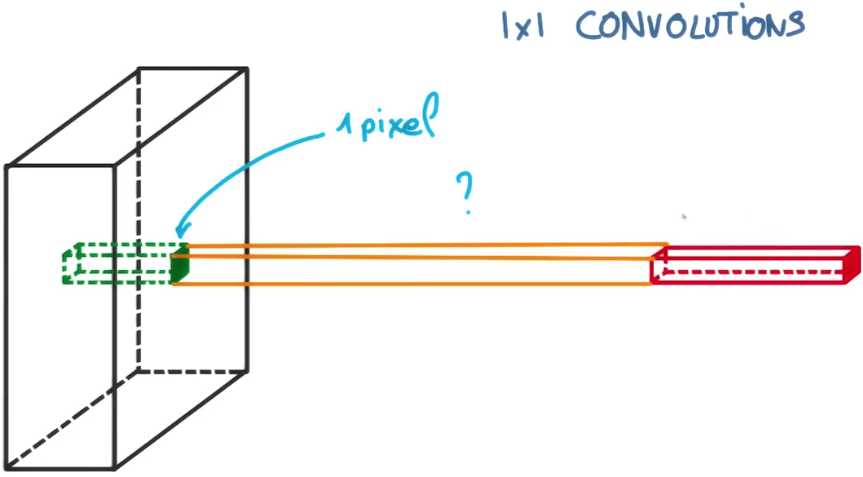
首先,先介绍一个想法, 即是1×1卷积。它并不关注一块图像,而是仅仅一个像素
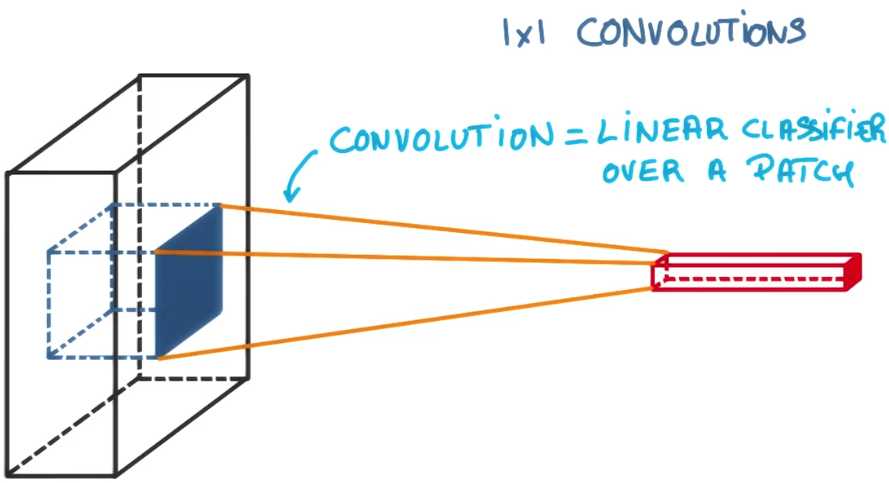
让我们回顾一下传统的卷积,它基本上是运行在一小块图片上的小分类器,但仅仅是个线性分类器
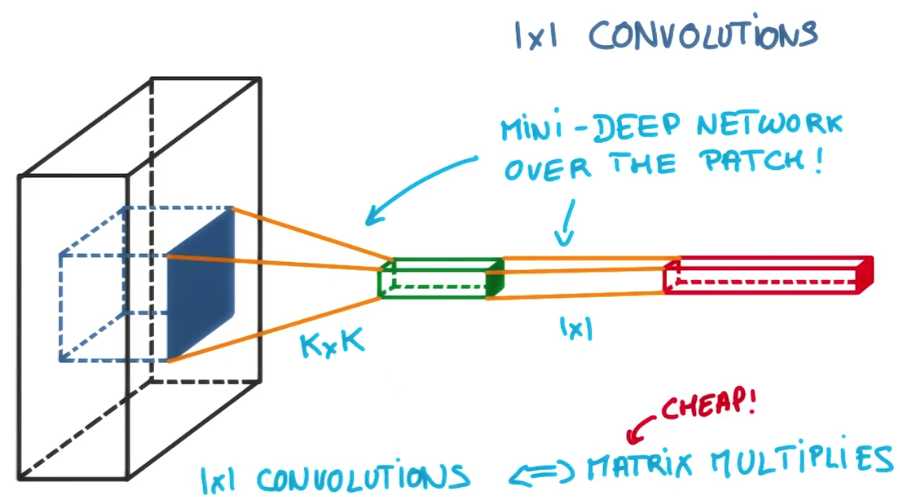
一旦你在中间加一个1×1卷积,你就用运行在一块图像的神经网络分类器代替了线性分类器
在卷积操作中散布一些1×1卷积,是一种使模型变得更深的低耗高效的方法
它会存在更多的参数但并没有完全改变神经网络结构 ,它非常简单,因为如果你看它的数学公式,它根本不是卷积
它们只是矩阵的相乘且仅有较少的参数。我提到了所有的方法,平均池化和1×1卷积

因为我想讲一下在创造神经网络时非常成功的应用策略
相比于金字塔式的结构,它们使得卷积网络更加的简洁高效
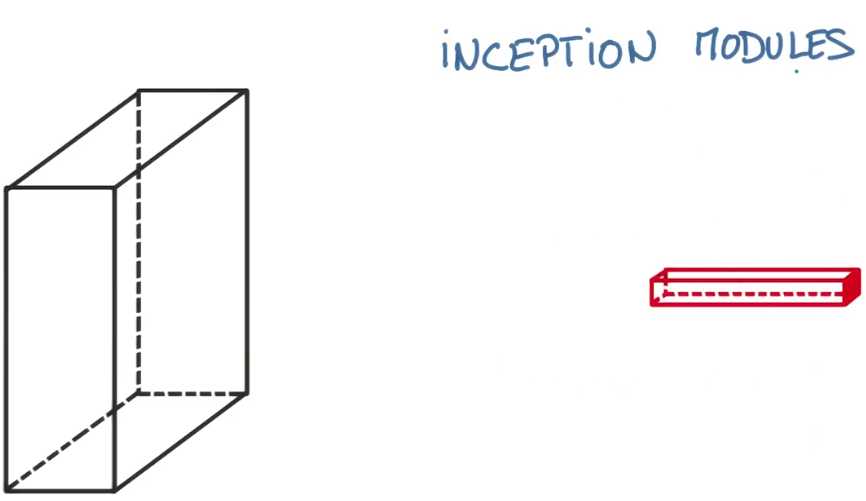
它看起来更加的复杂,这个想法是卷积神经网络的每一层,你都要做出一个选择,进行一个池化操作,还是一个卷积操作
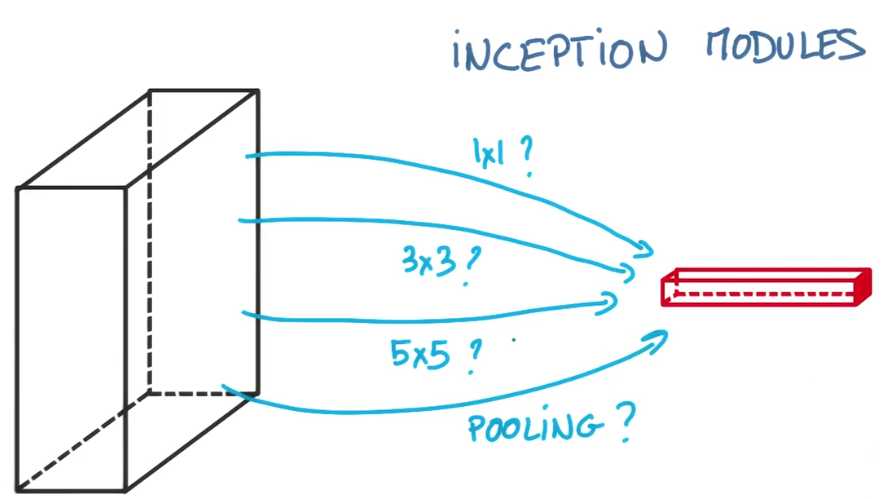
然后你需要决定是进行一个1×1、3×3还是5×5的卷积,其实这些对构建一个高效的神经网络都有帮助
那为什么还要选择?让我们全用吧
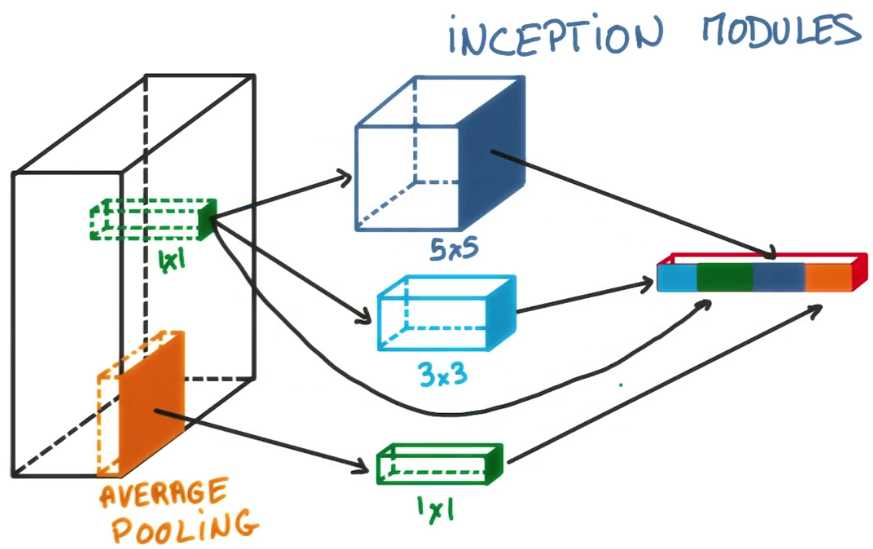
这就是一个inception模块的样子,相比与仅仅使用单个卷积,你的网络有一个1×1的池化
然后还有一个1×1的卷积还有一个1×1和3×3的卷积
最后面是一个1×1和5×5卷积
在末端,你只要连接所有的输出,看起来它很复杂,但是有意思的是你可以在模型参数非常少的情况下选择这些参数
因此这种模型会比之前简单的模型好太多,
这是神经网络最有趣的事情之一 ,因为你有一个总体的框架,在框架下你可以自由的组装很多的块结构
你可以迅速的实现你的想法, 针对你的问题可以提出非常有趣的模型结构
下面让我们看一下神经网络如何处理文本,
仔细观察卷积背后的算法以及你选择的填充方法,步数和其它的参数是如何影响它的,请参照这个图解指南:
标签:算法 没有 one pool 成功 矩阵相乘 var 情况 像素
原文地址:http://www.cnblogs.com/custer/p/6444949.html