标签:分配 src print runtime 也会 hello example glob return
1.基本概念
CUDA,全称是Compute Unified Device Architecture,意即统一计算架构,是NVIDIA推出的一种整合技术,开发者可以利用NVIDIA的GeForce 8 以后的GPU和较新的Quadro GPU进行计算。 ——维基百科
利用CUDA这个平台,可以方便地使用GPU来加速程序的数据运算。GPU对于深度学习这类领域非常重要,因为其具有强大的并行计算能力和浮点运算能力。
CUDA的编程模型将CPU作为主机(Host),将GPU作为设备(Device),CPU用来控制整体调度和程序逻辑,GPU负责执行高度线程化的数据并行部分。
运行在GPU上的程序被称为内核。
2.程序的一般步骤
01.分配主机储存器并初始化
02.分配设备储存器
03.将已经初始化的主机储存器内容复制到已分配的设备储存器上
04.GPU进行计算
05.将计算完的结果从设备复制到主机上
06.处理该结果数据
3.CUDA的线程层次
主要是三个层次,网格(Grid)、线程块(Block)、线程(Thread)
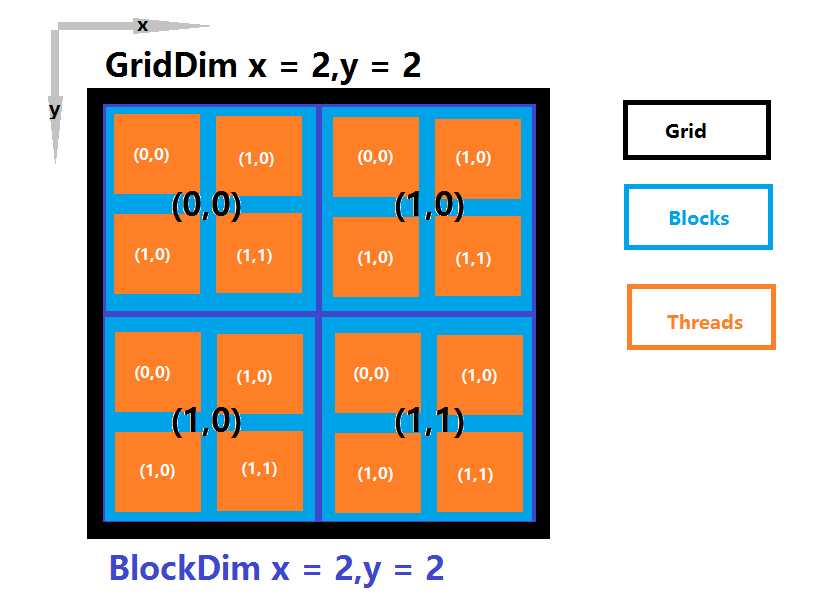
计算单个Thread的id:
ID=blockDim.x*blockDim.y*blockIdx.y*gridDim.x+gridDim.x*blockDim.x*threadIdx.y+blockDim.x+threadIdx.x;
4.一个简单的实例
CUDA的安装很方便,安装完后VS的相关环境配置一般都自动完成
实例
#include “cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
__global__ void hello() // kernel
{
printf("hello\n");
}
int main()
{
hello<< <1,5>> >();
cudaDeviceReset();
return 0;
}
CUDA安装后也会生成很多examples,都很不错。
标签:分配 src print runtime 也会 hello example glob return
原文地址:http://www.cnblogs.com/whlook/p/6476735.html