标签:订阅 zookeeper 分享 序列 增量更新 连接 mon 保存 logs
扒房源数据进入线索模块,客户端(浏览器)接收数据,使用了异步消息推送设计。数据来源是搜索团队,他们通过爬虫,将数据抓取后,将数据粗略去重后扔到 Kafka 里,司南通过接入 Kafka,监听消息队列。数据抵达后,数据首先进行二次清洗,数据保存后,扔到 Redis 队列。各个服务器监听 Redis 队列,订阅消息。单机监听到消息后,将数据推送给客户端。
下图是扒房源的后端架构设计图,步骤如下:
司南的服务器集群,监听 Redis 队列消息。每台服务器收到的消息都一模一样。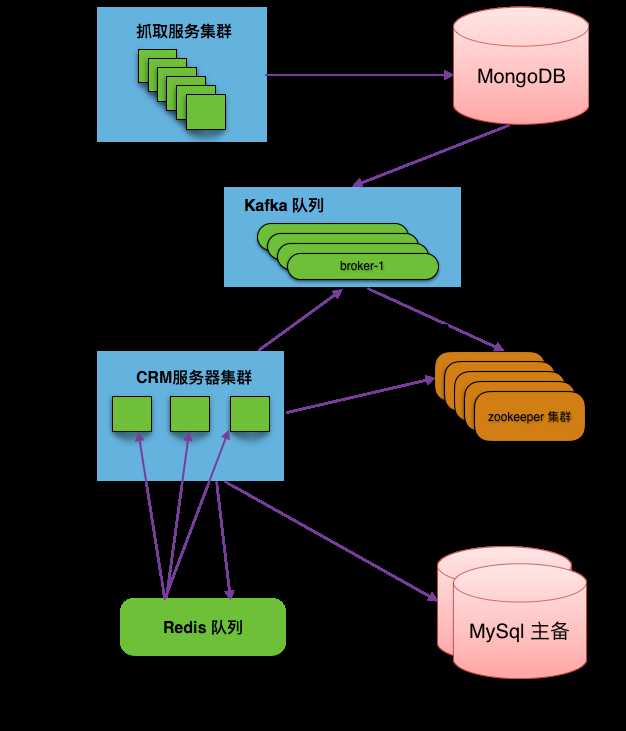
继上面单台司南服务器接收到线索消息后,进行消息推送,其处理序列图如下。
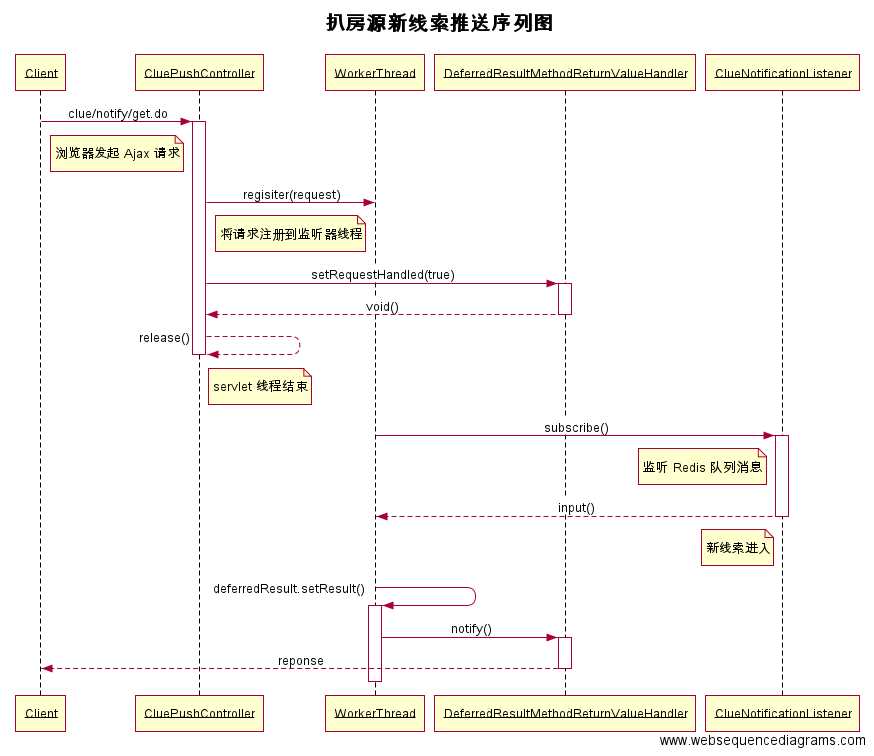
采用长连接的方式实现消息推送,涉及到几个时间点。
标签:订阅 zookeeper 分享 序列 增量更新 连接 mon 保存 logs
原文地址:http://www.cnblogs.com/seanvon/p/6478927.html