标签:过拟合 模型 分类 conf 提升 选择 precision rman test
继上一篇得到的初步数据,我们基本上已经得到了用于分类的数据了。接下来可以考虑建模了,建模可以有多种方法那么评估模型的最简单粗暴的方法就是匹配准确率。但是这次的评分规则是:

简单说下赛方为什么不用匹配准确率来评价模型,本身数据结构中“没得助学金”的个体已经占了85%左右的比例,如果计算整体的匹配率对好的模型的检验不够。所以从这个比赛规则,我们也可以收到启发,下次做这种数据结构不均衡的分类时,评价体系可以采用上面这个比赛规则。那么先把得分函数写出来:
from sklearn import metrics #metrics 可以给出分类的score,recall,precision的一个模块
from sklearn.metrics import precision_recall_fscore_support
def surescore(x,y,clf):
y_pred=clf.predict(x)
p,r,f1,s=precision_recall_fscore_support(y,y_pred)
f1_score=f1*s/s.sum()
result=f1_score[1:].sum()
print result
或者可以将多几个其他指标项的函数写出如下:
from sklearn import metrics from sklearn.metrics import precision_recall_fscore_support def measure_performance(X,y,clf, show_accuracy=True, show_classification_report=True, show_confusion_matrix=True): y_pred=clf.predict(X) if show_accuracy: print("Accuracy:{0:.3f}".format(metrics.accuracy_score(y,y_pred)),"\n")###准确度 if show_classification_report: print("Classification report") print(metrics.classification_report(y,y_pred),"\n") ##量化结果的表 p,r,f1,s=precision_recall_fscore_support(y,y_pred) f1_score=f1*s/s.sum() result=f1_score[1:].sum() print result if show_confusion_matrix: ###得到一个混合矩阵 print("Confusion matrix") print(metrics.confusion_matrix(y,y_pred),"\n")
-----------------------------------------------------------------------------------------------------------------------------------------------------------
(1)randforest分类是建立在已经将train_data,test_data都已经完全弄好的基础下:(1)进行cross-validation看看结果是不是存在过拟合(2)对test_data进行拟合得到结果,并且对结果进行评分。
from sklearn.ensemble import RandomForestClassifier
from sklearn.naive_bayes import GaussianNB
##cross-validation
import matplotlib.pyplot as plt
import numpy as np
from sklearn.learning_curve import validation_curve
param_range = [1,10,100]
train_scores, test_scores = validation_curve(RandomForestClassifier(),data_train, target_train, param_name="n_estimators", param_range=param_range, cv=10,scoring="accuracy", n_jobs=1)
print "333"
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.title("Validation Curve with SVM")
plt.xlabel("$\n_estimators$")
plt.ylabel("Score")
plt.ylim(0.0, 1.1)
lw = 2
plt.semilogx(param_range, train_scores_mean, label="Training score",
color="darkorange", lw=lw)
plt.fill_between(param_range, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.2,
color="darkorange", lw=lw)
plt.semilogx(param_range, test_scores_mean, label="Cross-validation score",
color="navy", lw=lw)
plt.fill_between(param_range, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.2,
color="navy", lw=lw)
plt.legend(loc="best")
plt.show()
#from sklearn import svm
import datetime
estimatorforest = RandomForestClassifier(n_estimators =100)
estimators = estimatorforest.fit(data_train,target_train)
print("准确率为:{:.2f}".format(estimators.score(data_test,target_test)))
from sklearn import metrics
from sklearn.metrics import precision_recall_fscore_support
def measure_performance(X,y,clf, show_accuracy=True,
show_classification_report=True,
show_confusion_matrix=True):
y_pred=clf.predict(X)
if show_accuracy:
print("Accuracy:{0:.3f}".format(metrics.accuracy_score(y,y_pred)),‘\n‘)
if show_classification_report:
print("Classification report")
print(metrics.classification_report(y,y_pred),"\n")
p,r,f1,s=precision_recall_fscore_support(y,y_pred)
f1_score=f1*s/s.sum()
result=f1_score[1:].sum()
print result
if show_confusion_matrix:
print("Confusion matrix")
print(metrics.confusion_matrix(y,y_pred),"\n")
measure_performance(data_test,target_test,estimators,show_classification_report=True, show_confusion_matrix=True)
上述运行后最后的结果得分(并非准确率):0.0158左右
这个时候我们可以进一步优化:首先看看cross_validation得到的图:
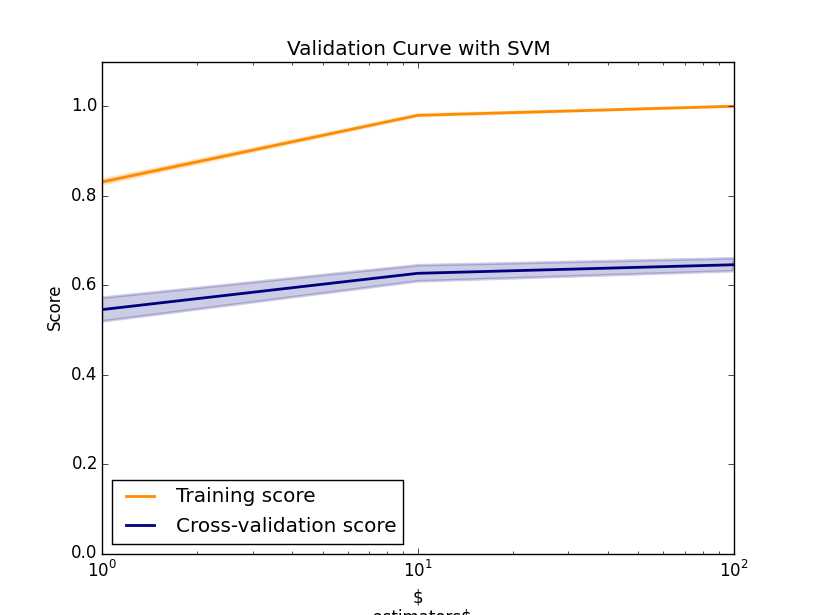
从这个图可以看到training_score 和cross-validation score 相差较大,一般这个都说明过拟合。一般缓解过拟合的方法(1)降低数据的维度(2)换一种算法模型(捂脸,这基本等于废话)。
(1)那么现在我第一考虑的降低数据维度是用选择现有的维度当中最有用的几个,这个可以用下面方法做到,运行后得分果然有提升蛮多。
from sklearn.feature_selection import RFE ##原理就是将所有的变量放入svm等去构建模型看准确度,然后排名得到的哪些维度比较好 from sklearn.linear_model import LogisticRegression from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier() rfe = RFE(model, 4) rfe = rfe.fit(data_train,target_train) print(rfe.support_) print(rfe.ranking_)
(2)接下要试试其他的算法模型(1)贝叶斯 (2)adaboost ------明日待续
标签:过拟合 模型 分类 conf 提升 选择 precision rman test
原文地址:http://www.cnblogs.com/xyt-cathy/p/6477335.html