标签:images 并且 vector 指示 scala over tor 问题 方式
一开始觉得这个不是问题,因为DT本身就是处理类别型数据的,加上之前自己写代码的时候也都是支持类别型数据的。所以按照自己的理解,如果数据是
a,h,y
b,c,x
这种类别型的,就直接输入到spark即可。但是看到网上说由于spark的Vector不支持string,所以需要将其转为数值型。那么如何转换呢?
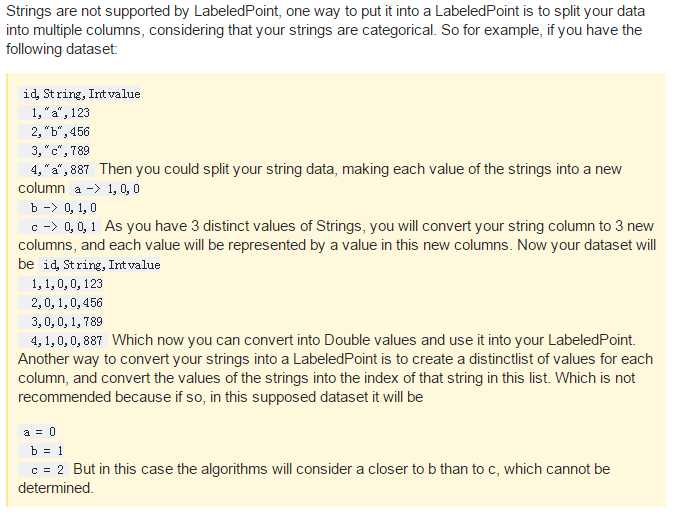
这是个问题,一般的转换方式是采用one-hot编码,具体的可以看这个
就是说将a,b,c这三个变成一个3*3的矩阵。那么这个有啥好处呢?
首先对于上面所说的,如果a=0,b=1,c=2,那么算法就会认为b比a更接近c,但事实上没有这个关系
而one-hot编码则没有这样的度量
并且在某种意义上来说,还扩充了特征。
但是这样做无疑也增加了空间,不过利用dense matrix应该也还好。
好咧,言归正传,那么在spark中如何搞类别型数据呢?
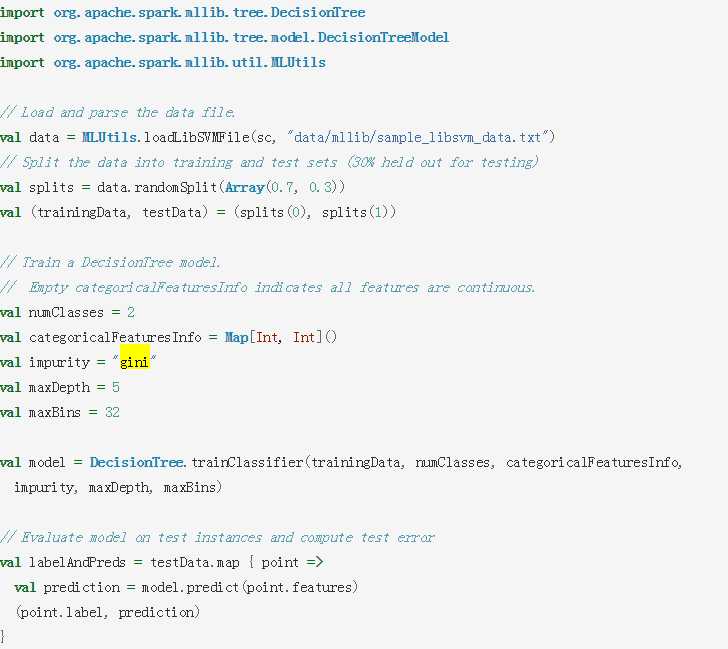
先放个例子:
从上面一眼就能看出来,categoricalFeatureInfo这个是用来指示
就是说Map中的key值是说明那一列是类别型数据,而value值表示该列有多少种属性值,嗯,就是这么简单。
有点不明白那些人,就不会网上搜一下么,你纠结了一天,我网上一搜,2分钟给你答案,何必呢。
决策树对类别型数据的处理
标签:images 并且 vector 指示 scala over tor 问题 方式
原文地址:http://www.cnblogs.com/sunrye/p/6504889.html