标签:gty 配置文件 group by 结合 情况 对象 conf hadoop1 default


package com.hzf.spark.exercise;import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaSparkContext;import org.apache.spark.sql.DataFrame;import org.apache.spark.sql.SQLContext;publicclassTestSparkSQL02{publicstaticvoid main(String[] args){SparkConf conf =newSparkConf().setAppName("DataFrameOps").setMaster("local");JavaSparkContext sc =newJavaSparkContext(conf);SQLContext sqlContext =newSQLContext(sc);DataFrame df = sqlContext.read().json("people.json");/* * 操作DataFrame的第一种方式 * *///类似 SQL的select from table; df.show();//desc table df.printSchema();//select age from table; df.select("age").show();//select name from table; df.select("name").show();//select name,age+10 from table; df.select(df.col("name"),df.col("age").plus(10)).show();//select * from table where age > 20 df.filter(df.col("age").gt(20)).show();}}
package com.hzf.spark.exercise;import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaSparkContext;import org.apache.spark.sql.DataFrame;import org.apache.spark.sql.SQLContext;publicclassTestSparkSQL01{publicstaticvoid main(String[] args){SparkConf conf =newSparkConf().setAppName("DataFrameOps").setMaster("local");JavaSparkContext sc =newJavaSparkContext(conf);SQLContext sqlContext =newSQLContext(sc);DataFrame df = sqlContext.read().json("people.json");//将DataFrame中封装的数据注册为一张临时表,对临时表进行sql操作 df.registerTempTable("people");DataFrame sql = sqlContext.sql("SELECT * FROM people WHERE age IS NOT NULL"); sql.show();}}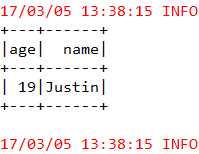
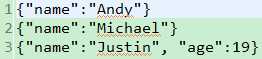
package com.bjsxt.java.spark.sql.json;import java.util.ArrayList;import java.util.List;import org.apache.spark.SparkConf;import org.apache.spark.SparkContext;import org.apache.spark.api.java.JavaPairRDD;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.api.java.JavaSparkContext;import org.apache.spark.api.java.function.Function;import org.apache.spark.api.java.function.PairFunction;import org.apache.spark.sql.DataFrame;import org.apache.spark.sql.Row;import org.apache.spark.sql.RowFactory;import org.apache.spark.sql.SQLContext;import org.apache.spark.sql.types.DataTypes;import org.apache.spark.sql.types.StructField;import org.apache.spark.sql.types.StructType;import scala.Tuple2;/** * JSON数据源 * @author Administrator * */publicclassJSONDataSource{publicstaticvoid main(String[] args){SparkConf conf =newSparkConf().setAppName("JSONDataSource")// .set("spark.default.parallelism", "100").setMaster("local");JavaSparkContext sc =newJavaSparkContext(conf);SQLContext sqlContext =newSQLContext(sc);DataFrame studentScoresDF = sqlContext.read().json("student.json"); studentScoresDF.registerTempTable("student_scores");DataFrame goodStudentScoresDF = sqlContext.sql("select name,count(score) from student_scores where score>=80 group by name");List<String> goodStudentNames = goodStudentScoresDF.javaRDD().map(newFunction<Row,String>(){privatestaticfinallong serialVersionUID =1L;@OverridepublicString call(Row row)throwsException{return row.getString(0);}}).collect();for(String str: goodStudentNames){System.out.println(str);}}}
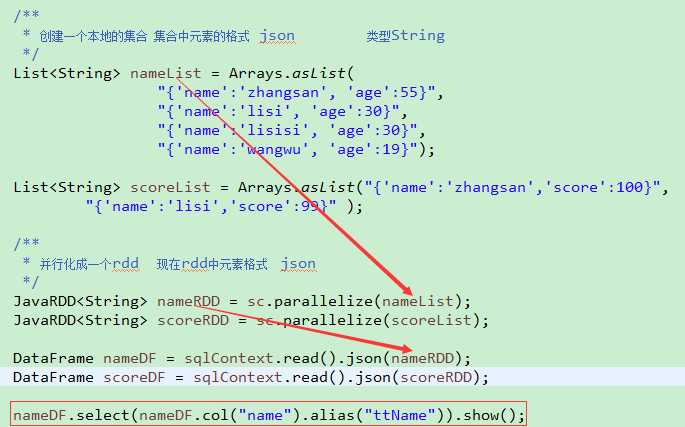
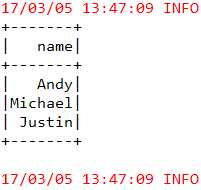
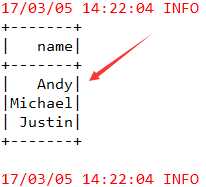
parquet是一个基于列的存储格式,列式存储布局可以加速查询,因为它只检查所有需要的列并对它们的值执行计算,因此只读取一个数据文件或表的小部分数据。Parquet 还支持灵活的压缩选项,因此可以显著减少磁盘上的存储。
如果在 HDFS 上拥有基于文本的数据文件或表,而且正在使用 Spark SQL 对它们执行查询,那么强烈推荐将文本数据文件转换为 Parquet 数据文件,以实现性能和存储收益。当然,转换需要时间,但查询性能的提升在某些情况下可能达到 30 倍或更高,存储的节省可高达 75%!


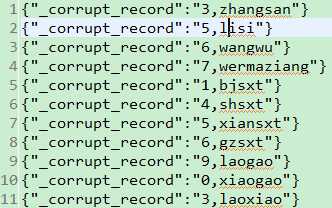
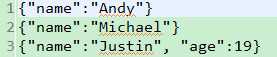
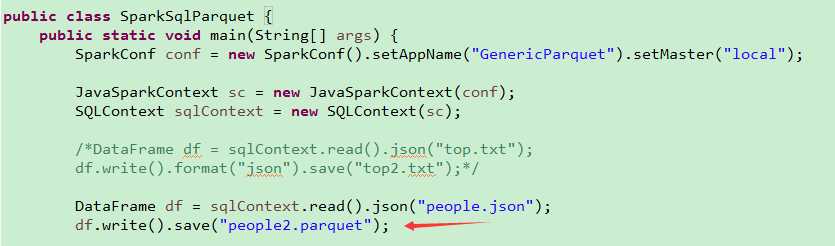

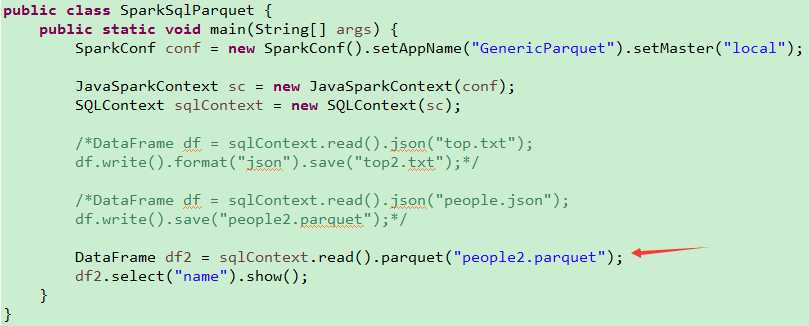

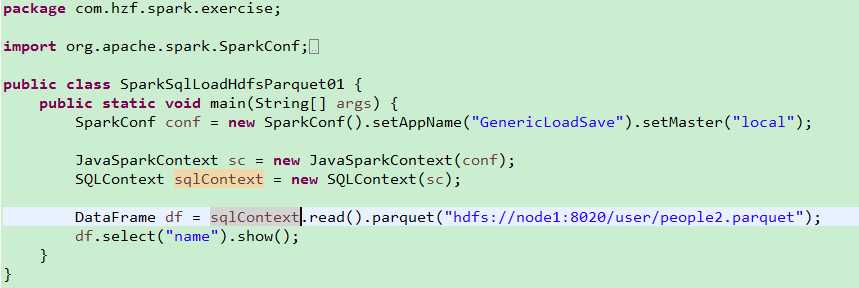
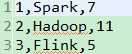
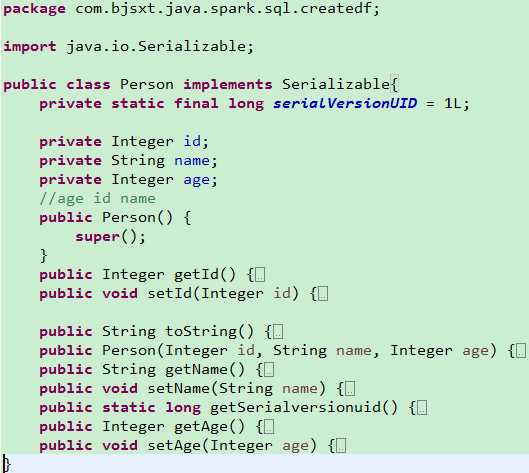
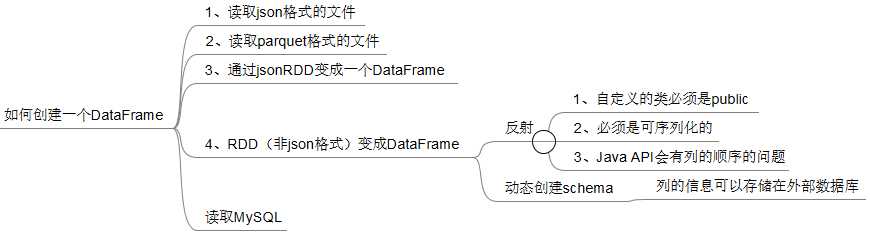
package com.bjsxt.java.spark.sql.createdf;import java.util.List;import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.api.java.JavaSparkContext;import org.apache.spark.api.java.function.Function;import org.apache.spark.sql.DataFrame;import org.apache.spark.sql.Row;import org.apache.spark.sql.SQLContext;/** * 使用反射的方式将RDD转换成为DataFrame * 1、自定义的类必须是public * 2、自定义的类必须是可序列化的 * 3、RDD转成DataFrame的时候,他会根据自定义类中的字段名进行排序。 * @author zfg * */publicclass RDD2DataFrameByReflection {publicstaticvoid main(String[] args){SparkConf conf =newSparkConf().setMaster("local").setAppName("RDD2DataFrameByReflection");JavaSparkContext sc =newJavaSparkContext(conf);SQLContext sqlcontext =newSQLContext(sc);JavaRDD<String> lines = sc.textFile("Peoples.txt");JavaRDD<Person> personsRdd = lines.map(newFunction<String,Person>(){privatestaticfinallong serialVersionUID =1L;@OverridepublicPerson call(String line)throwsException{String[] split = line.split(",");Person p =newPerson(); p.setId(Integer.valueOf(split[0].trim())); p.setName(split[1]); p.setAge(Integer.valueOf(split[2].trim()));return p;}});//传入进去Person.class的时候,sqlContext是通过反射的方式创建DataFrame//在底层通过反射的方式或得Person的所有field,结合RDD本身,就生成了DataFrameDataFrame df = sqlcontext.createDataFrame(personsRdd,Person.class);//命名table的名字为person df.registerTempTable("personTable");DataFrame resultDataFrame = sqlcontext.sql("select * from personTable where age > 7"); resultDataFrame.show();//将df转成rddJavaRDD<Row> resultRDD = resultDataFrame.javaRDD();JavaRDD<Person> result = resultRDD.map(newFunction<Row,Person>(){privatestaticfinallong serialVersionUID =1L;@OverridepublicPerson call(Row row)throwsException{Person p =newPerson(); p.setAge(row.getInt(0)); p.setId(row.getInt(1)); p.setName(row.getString(2));return p;}});List<Person> personList = result.collect();for(Person person : personList){System.out.println(person.toString());}}}

package com.bjsxt.java.spark.sql.createdf;import java.util.ArrayList;import java.util.List;import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.api.java.JavaSparkContext;import org.apache.spark.api.java.function.Function;import org.apache.spark.sql.DataFrame;import org.apache.spark.sql.Row;import org.apache.spark.sql.RowFactory;import org.apache.spark.sql.SQLContext;import org.apache.spark.sql.types.DataTypes;import org.apache.spark.sql.types.StructField;import org.apache.spark.sql.types.StructType;publicclass RDD2DataFrameByProgrammatically {publicstaticvoid main(String[] args){SparkConf conf =newSparkConf().setMaster("local").setAppName("RDD2DataFrameByReflection");JavaSparkContext sc =newJavaSparkContext(conf);SQLContext sqlcontext =newSQLContext(sc);/** * 在RDD的基础上创建类型为Row的RDD */JavaRDD<String> lines = sc.textFile("Peoples.txt");JavaRDD<Row> rowRDD = lines.map(newFunction<String,Row>(){privatestaticfinallong serialVersionUID =1L;@OverridepublicRow call(String line)throwsException{String[] split = line.split(",");returnRowFactory.create(Integer.valueOf(split[0]),split[1],Integer.valueOf(split[2]));}});/** * 动态构造DataFrame的元数据,一般而言,有多少列以及每列的具体类型可能来自于Json,也可能来自于DB */ArrayList<StructField> structFields =newArrayList<StructField>(); structFields.add(DataTypes.createStructField("id",DataTypes.IntegerType,true)); structFields.add(DataTypes.createStructField("name",DataTypes.StringType,true)); structFields.add(DataTypes.createStructField("age",DataTypes.IntegerType,true));//构建StructType,用于最后DataFrame元数据的描述StructType schema =DataTypes.createStructType(structFields);/** * 基于已有的MetaData以及RDD<Row> 来构造DataFrame */DataFrame df = sqlcontext.createDataFrame(rowRDD, schema);/** *注册成为临时表以供后续的SQL操作查询 */ df.registerTempTable("persons");/** * 进行数据的多维度分析 */DataFrame result = sqlcontext.sql("select * from persons where age > 7"); result.show();/** * 对结果进行处理,包括由DataFrame转换成为RDD<Row> */List<Row> listRow = result.javaRDD().collect();for(Row row : listRow){System.out.println(row);}}}

package com.bjsxt.java.spark.sql.jdbc;import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaSparkContext;import org.apache.spark.sql.DataFrame;import org.apache.spark.sql.DataFrameReader;import org.apache.spark.sql.SQLContext;/** * JDBC数据源 * * @author Administrator * */publicclassJDBCDataSource{publicstaticvoid main(String[] args){SparkConf conf =newSparkConf().setAppName("JDBCDataSource").setMaster("local");JavaSparkContext sc =newJavaSparkContext(conf);SQLContext sqlContext =newSQLContext(sc);// 方法1、分别将mysql中两张表的数据加载为DataFrame/* * Map<String, String> options = new HashMap<String, String>(); * options.put("url", "jdbc:mysql://hadoop1:3306/testdb"); * options.put("driver", "com.mysql.jdbc.Driver"); * options.put("user","spark"); * options.put("password", "spark2016"); * options.put("dbtable", "student_info"); * DataFrame studentInfosDF = sqlContext.read().format("jdbc").options(options).load(); * options.put("dbtable", "student_score"); * DataFrame studentScoresDF = sqlContext.read().format("jdbc") .options(options).load(); */// 方法2、分别将mysql中两张表的数据加载为DataFrameDataFrameReader reader = sqlContext.read().format("jdbc"); reader.option("url","jdbc:mysql://node4:3306/testdb"); reader.option("driver","com.mysql.jdbc.Driver"); reader.option("user","root"); reader.option("password","123"); reader.option("dbtable","student_info");DataFrame studentInfosDF = reader.load(); reader.option("dbtable","student_score");DataFrame studentScoresDF = reader.load();// 将两个DataFrame转换为JavaPairRDD,执行join操作 studentInfosDF.registerTempTable("studentInfos"); studentScoresDF.registerTempTable("studentScores");String sql ="SELECT studentInfos.name,age,score "+" FROM studentInfos JOIN studentScores"+" ON (studentScores.name = studentInfos.name)"+" WHERE studentScores.score > 80";DataFrame sql2 = sqlContext.sql(sql); sql2.show();}}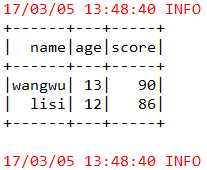

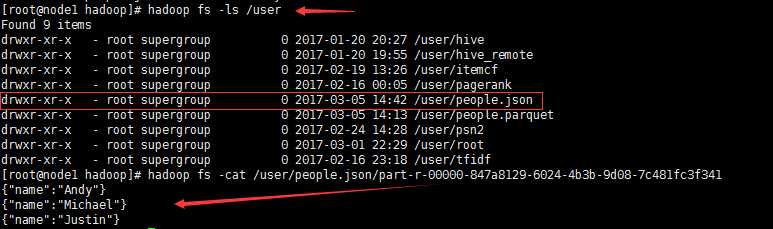
scala>import org.apache.spark.sql.hive.HiveContextscala>val hiveContext =newHiveContext(sc)scala>hiveContext.sql("show tables").show标签:gty 配置文件 group by 结合 情况 对象 conf hadoop1 default
原文地址:http://www.cnblogs.com/haozhengfei/p/22bba3b1ef90cbfaf073eb44349c0757.html