标签:客户端 apache figure empty types 个数 balance replicat image
hadoop项目地址:http://hadoop.apache.org/
分布式文件系统概述:
HDFS的简单使用:
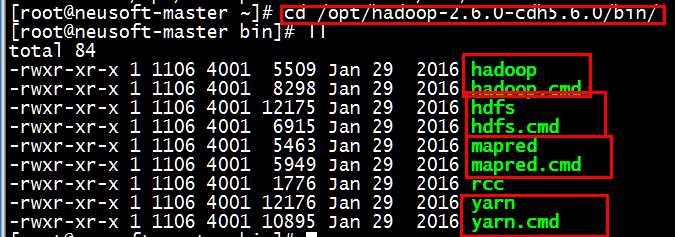
通过hdfs命令查看所有的可使用参数
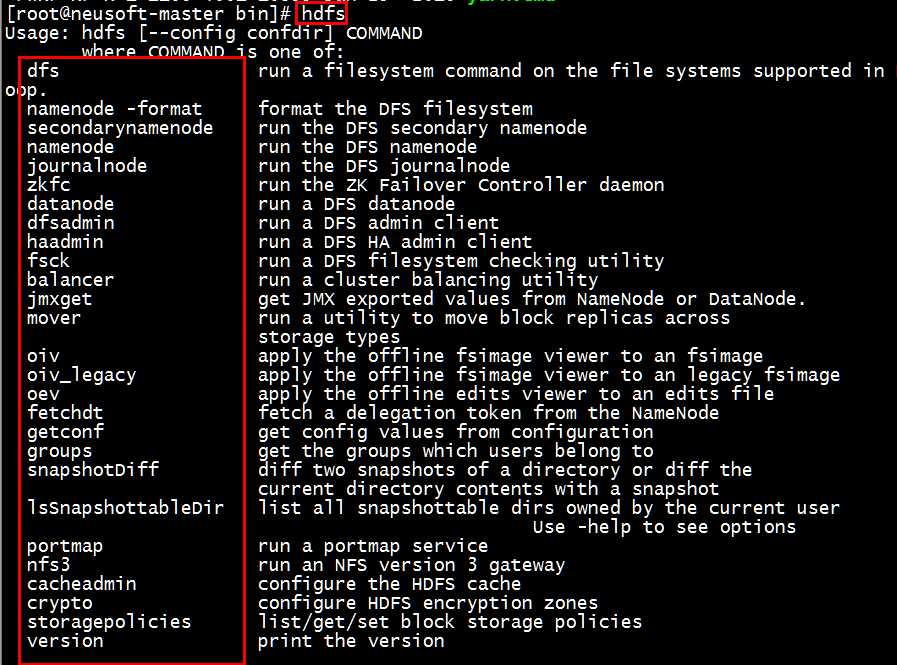
[root@neusoft-master bin]# hdfs Usage: hdfs [--config confdir 可选项,指定配置文件目录,默认在/etc/hadoop目录下] COMMAND where COMMAND is one of: dfs run a filesystem command on the file systems supported in Hadoop. #重点 namenode -format format the DFS filesystem #最好只执行一次 secondarynamenode run the DFS secondary namenode #在hadoop2中不用 namenode run the DFS namenode journalnode run the DFS journalnode zkfc run the ZK Failover Controller daemon datanode run a DFS datanode dfsadmin run a DFS admin client haadmin run a DFS HA admin client fsck run a DFS filesystem checking utility balancer run a cluster balancing utility jmxget get JMX exported values from NameNode or DataNode. mover run a utility to move block replicas across storage types oiv apply the offline fsimage viewer to an fsimage oiv_legacy apply the offline fsimage viewer to an legacy fsimage oev apply the offline edits viewer to an edits file fetchdt fetch a delegation token from the NameNode getconf get config values from configuration groups get the groups which users belong to snapshotDiff diff two snapshots of a directory or diff the current directory contents with a snapshot lsSnapshottableDir list all snapshottable dirs owned by the current user Use -help to see options portmap run a portmap service nfs3 run an NFS version 3 gateway cacheadmin configure the HDFS cache crypto configure HDFS encryption zones storagepolicies list/get/set block storage policies version print the version Most commands print help when invoked w/o parameters.
如果对某一个命令不知道怎么使用,可以直接输入命令即可,如下
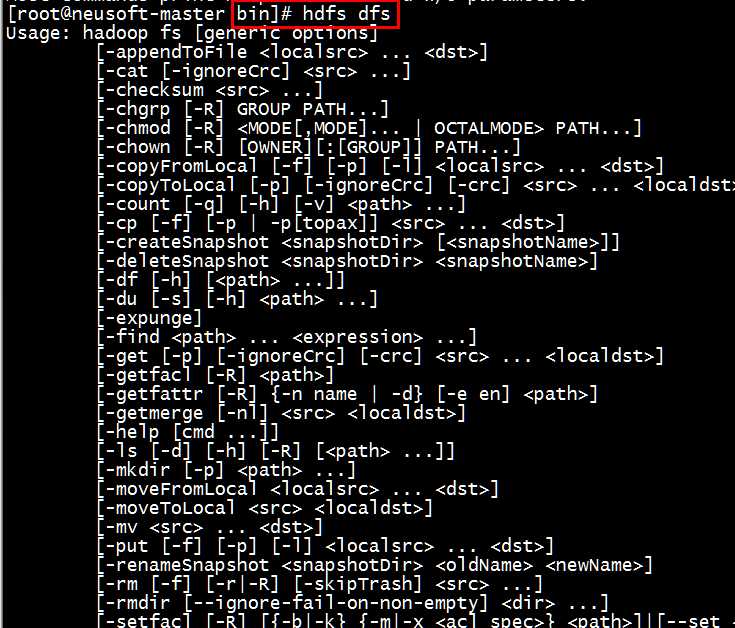
[root@neusoft-master bin]# hdfs dfs #一定在bin目录下执行hdfs命令 Usage: hadoop fs [generic options] [-appendToFile <localsrc> ... <dst>] [-cat [-ignoreCrc] <src> ...] [-checksum <src> ...] [-chgrp [-R] GROUP PATH...] [-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...] [-chown [-R] [OWNER][:[GROUP]] PATH...] [-copyFromLocal [-f] [-p] [-l] <localsrc> ... <dst>] [-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] [-count [-q] [-h] [-v] <path> ...] [-cp [-f] [-p | -p[topax]] <src> ... <dst>] [-createSnapshot <snapshotDir> [<snapshotName>]] [-deleteSnapshot <snapshotDir> <snapshotName>] [-df [-h] [<path> ...]] [-du [-s] [-h] <path> ...] [-expunge] [-find <path> ... <expression> ...] [-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] [-getfacl [-R] <path>] [-getfattr [-R] {-n name | -d} [-e en] <path>] [-getmerge [-nl] <src> <localdst>] [-help [cmd ...]] [-ls [-d] [-h] [-R] [<path> ...]] [-mkdir [-p] <path> ...] [-moveFromLocal <localsrc> ... <dst>] [-moveToLocal <src> <localdst>] [-mv <src> ... <dst>] [-put [-f] [-p] [-l] <localsrc> ... <dst>] [-renameSnapshot <snapshotDir> <oldName> <newName>] [-rm [-f] [-r|-R] [-skipTrash] <src> ...] [-rmdir [--ignore-fail-on-non-empty] <dir> ...] [-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]] [-setfattr {-n name [-v value] | -x name} <path>] [-setrep [-R] [-w] <rep> <path> ...] [-stat [format] <path> ...] [-tail [-f] <file>] [-test -[defsz] <path>] [-text [-ignoreCrc] <src> ...] [-touchz <path> ...] [-usage [cmd ...]] Generic options supported are -conf <configuration file> specify an application configuration file -D <property=value> use value for given property -fs <local|namenode:port> specify a namenode -jt <local|resourcemanager:port> specify a ResourceManager -files <comma separated list of files> specify comma separated files to be copied to the map reduce cluster -libjars <comma separated list of jars> specify comma separated jar files to include in the classpath. -archives <comma separated list of archives> specify comma separated archives to be unarchived on the compute machines. The general command line syntax is bin/hadoop command [genericOptions] [commandOptions]
在hadoop1中使用hadoop dfs ...,上述的命令提示还是老版本的命令。在hadoop2中使用hdfs dfs ... 命令,如下图所示:
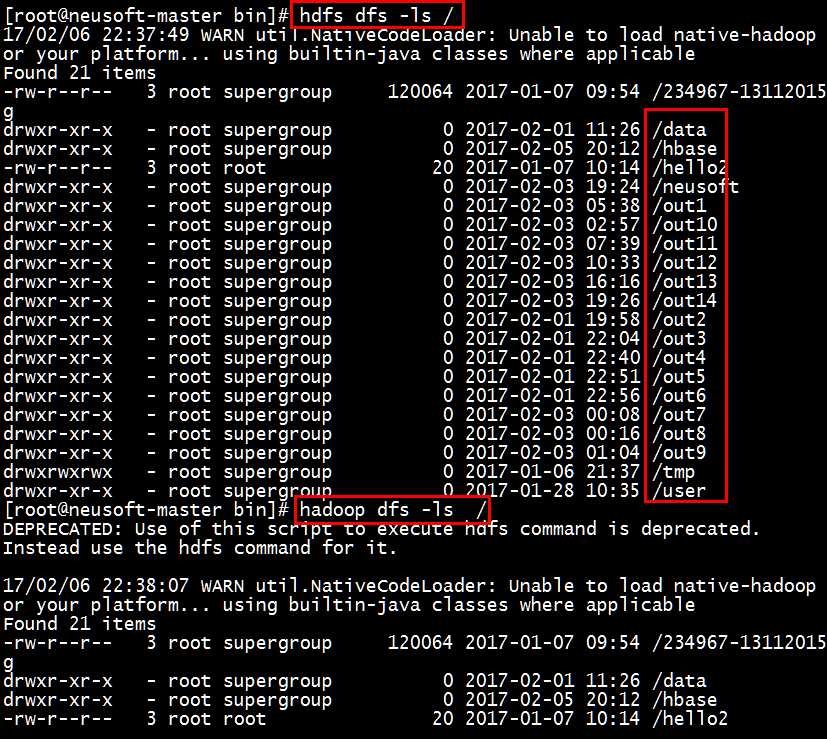
提示:linux中的ls -l命令,需要明确了解显示的内容的含义

d表示目录。-表示文件,l表示链接,之后9位的每三位是一组,第一组表示创建者,第二组表示创建者所在组,第三个表示其他人。
HttpFS访问方式
1:httpfs是一个hadoop hdfs的一个http接口,通过WebHDFS REST API 可以对hdfs进行读写等访问
2:与WebHDFS的区别是不需要客户端可以访问hadoop集群的每一个节点,通过httpfs可以访问放置在防火墙后面的hadoop集群
3:httpfs是一个Web应用,部署在内嵌的tomcat中
操作方式如下:
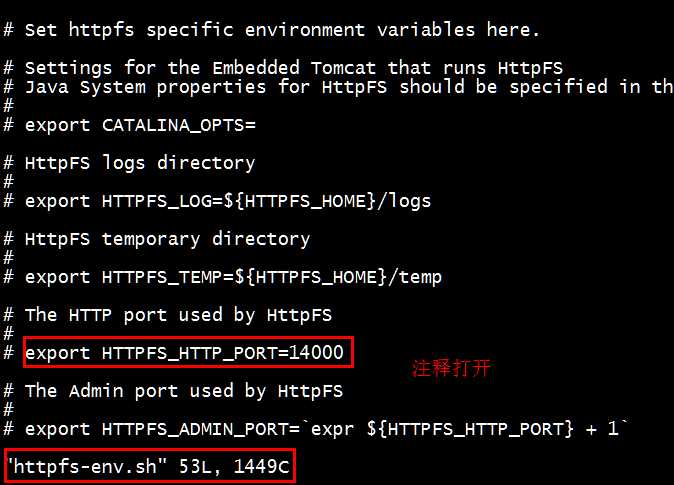
1.编辑文件httpfs-env.sh,将端口为14000的打开即可
2.编辑文件core-site.xml,添加
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
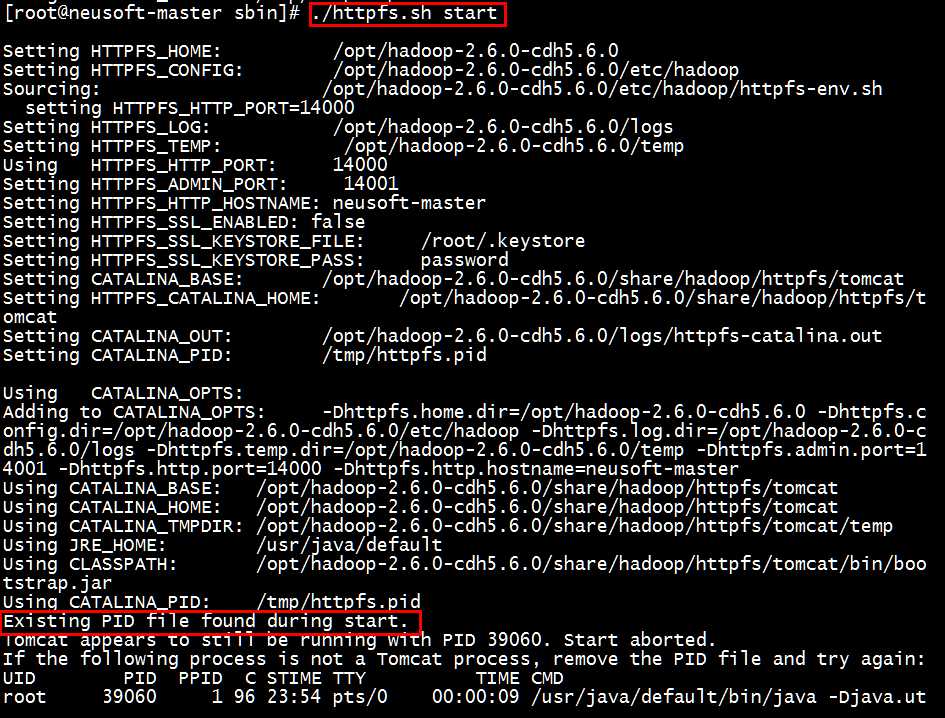
3.重新启动namenode,执行sbin/httpfs.sh start
[root@neusoft-master sbin]# ./stop-all.sh #停止集群 [root@neusoft-master sbin]# ./start-all.sh #重新开启集群 [root@neusoft-master sbin]# jps 38143 NameNode 38444 SecondaryNameNode 38696 NodeManager 38248 DataNode 38835 Jps 38599 ResourceManager [root@neusoft-master sbin]# ./httpfs.sh start #开启httpfs
开启后为了确认httpfs命令已开启,重新执行该命令,可以查看到PID已经存在的信息。
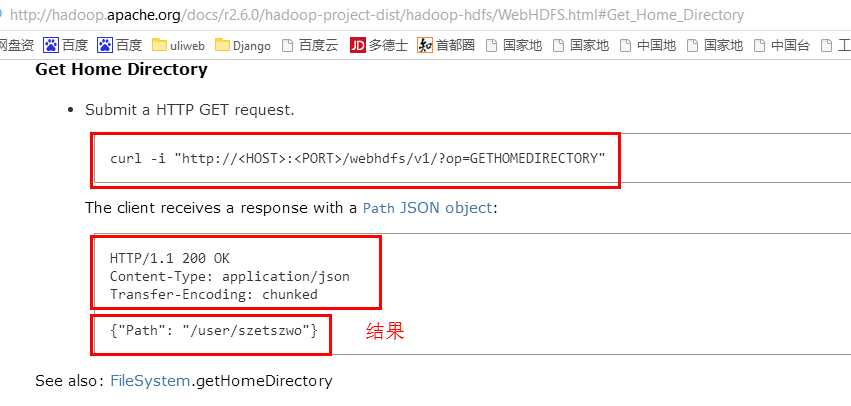
4.执行命令curl -i "http://neusoft-master:14000/webhdfs/v1/?user.name=root&op=GETHOMEDIRECTORY"
[root@neusoft-master sbin]# curl -i "http://neusoft-master:14000/webhdfs/v1/?user.name=root&op=GETHOMEDIRECTORY"
下面的红色信息为http所带的head信息 HTTP/1.1 200 OK Server: Apache-Coyote/1.1 Set-Cookie: hadoop.auth="u=root&p=root&t=simple-dt&e=1486432504558&s=o83ImIOyH8z6T2ZhI/YRH3secGk="; Path=/; Expires=Tue, 07-Feb-2017 01:55:04 GMT; HttpOnly Content-Type: application/json Transfer-Encoding: chunked Date: Mon, 06 Feb 2017 15:55:06 GMT
GETHOMEDIRECTORY查看主文件目录的结果如下:
{"Path":"\/user\/root"} #结果信息
更多命令参考http://hadoop.apache.org/docs/r2.6.0/hadoop-project-dist/hadoop-hdfs/WebHDFS.html
HDFS体系结构
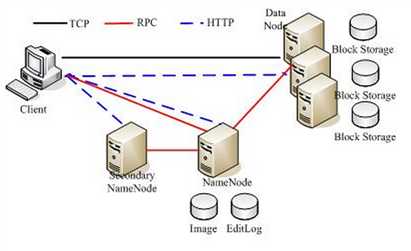
Client客户端+Namenode+DataNode
Namenode
是整个文件系统的管理节点。它维护着1.整个文件系统的文件目录树,2.文件/目录的元信息和每个文件对应的数据块列表。3.接收用户的操作请求。
(见源码) 文件包括:(hdfs-site.xml的dfs.namenode.name.dir属性)
总结:
NameNode维护着2张表:
1.文件系统的目录结构,以及元数据信息
2.文件与数据块(block)列表的对应关系
元数据存放在fsimage中,在运行的时候加载到内存中的(读写比较快)。
操作日志写到edits中。(类似于LSM树中的log)
(刚开始的写文件会写入到内存中和edits中,edits会记录文件系统的每一步操作,当达到一定的容量会将其内容写入fsimage中)
实验:
(a)通过maven下载源代码,查看hdfs-default.xml配置文件
<property> <name>dfs.namenode.name.dir</name> <value>file://${hadoop.tmp.dir}/dfs/name</value> <description>Determines where on the local filesystem the DFS name node should store the name table(fsimage). If this is a comma-delimited list of directories then the name table is replicated in all of the directories, for redundancy. </description> </property>
描述信息为:确定在本地文件系统上的DFS名称节点应存储名称表(fsimage)。 fsimage的内容会被存储到以逗号分隔的列表的目录中,然后在所有的目录中复制名称表目录,用于冗余。
****在实际应用中只需要将上述的源代码复制到hdfs-site.xml中,将<value>中的值改为以逗号分隔的列表即可。(注意:逗号后千万不可加空格在写文件)
(b)通过源代码信息的查找,寻找dfs.namenode.name.dir的信息,首先应该找到hadoop.tmp.dir的配置信息,从而寻找到core-site.xml
[root@neusoft-master sbin]# vi ../etc/hadoop/core-site.xml <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>fs.default.name</name> <value>hdfs://neusoft-master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop-2.6.0-cdh5.6.0/tmp</value> </property>
(c)根据上述分析查找tmp目录以及其子目录的详细信息

(d)VERSION信息的内容
[root@neusoft-master sbin]# more /opt/hadoop-2.6.0-cdh5.6.0/tmp/dfs/namesecondary/current/VERSION
显示内容:
#Mon Feb 06 23:54:55 CST 2017 namespaceID=457699475 #命名空间,hdfs格式化会改变命名空间id,当首次格式化的时候datanode和namenode会产生一个相同的namespaceID,然后读取数据就可以,如果你重新执行格式化的时候,namenode的namespaceID改变了,但是datanode的namespaceID没有改变,两边就不一致了,如果重新启动或进行读写hadoop就会挂掉。 clusterID=CID-409e0084-39f0-4386-8184-dd555478a3d6 #hdfs集群 cTime=0 storageType=NAME_NODE blockpoolID=BP-625280320-192.168.191.130-1483628038952 #hdfs联邦中使用,就是里面的namenode是共享的 layoutVersion=-60
多次格式化namenode的问题原因解释?
答:hdfs格式化会改变命名空间id,当首次格式化的时候datanode和namenode会产生一个相同的namespaceID,然后读取数据就可以,如果你重新执行格式化的时候,namenode的namespaceID改变了,但是datanode的namespaceID没有改变,两边就不一致了,如果重新启动或进行读写hadoop就会挂掉。
解决方案:hdfs namenode -format -force 进行强制的格式化会同时格式化namenode和datanode
-format [-clusterid cid ] [-force] [-nonInteractive] (完整的命令为hdfs namenode [-format [-clusterid cid ] [-force] [-nonInteractive]])。
查看NameNode内容


Datanode
(这样设置可以减轻namenode压力,因为namonode维护者文件与数据块列表的对应大小)
(1)Hdfs块大小如何设定?
hdfs-default.xml
<property> <name>dfs.blocksize</name> #block块存储的配置信息 <value>134217728</value> #这里的块的容量最大是128M,请注意 <description> The default block size for new files, in bytes. You can use the following suffix (case insensitive): k(kilo), m(mega), g(giga), t(tera), p(peta), e(exa) to specify the size (such as 128k, 512m, 1g, etc.), Or provide complete size in bytes (such as 134217728 for 128 MB). </description> </property>
描述信息翻译:
新文件的默认块大小(以字节为单位)。
您可以使用以下后缀(不区分大小写):
指定大小(例如128k,512m,1g等)的k(千),m(兆),g(giga),t(tera),p(peta)
或提供完整的大小(以128 MB为单位的134217728)。
***如何修改默认大小的blocksize?答:只需要修改上述配置文件即可。但是这种方式是全局的修改。 64M=67108864
如果想针对文件修改,只需要使用命令修改即可 hadoop fs -Ddfs.blocksize=134217728 -put ./test.txt /test
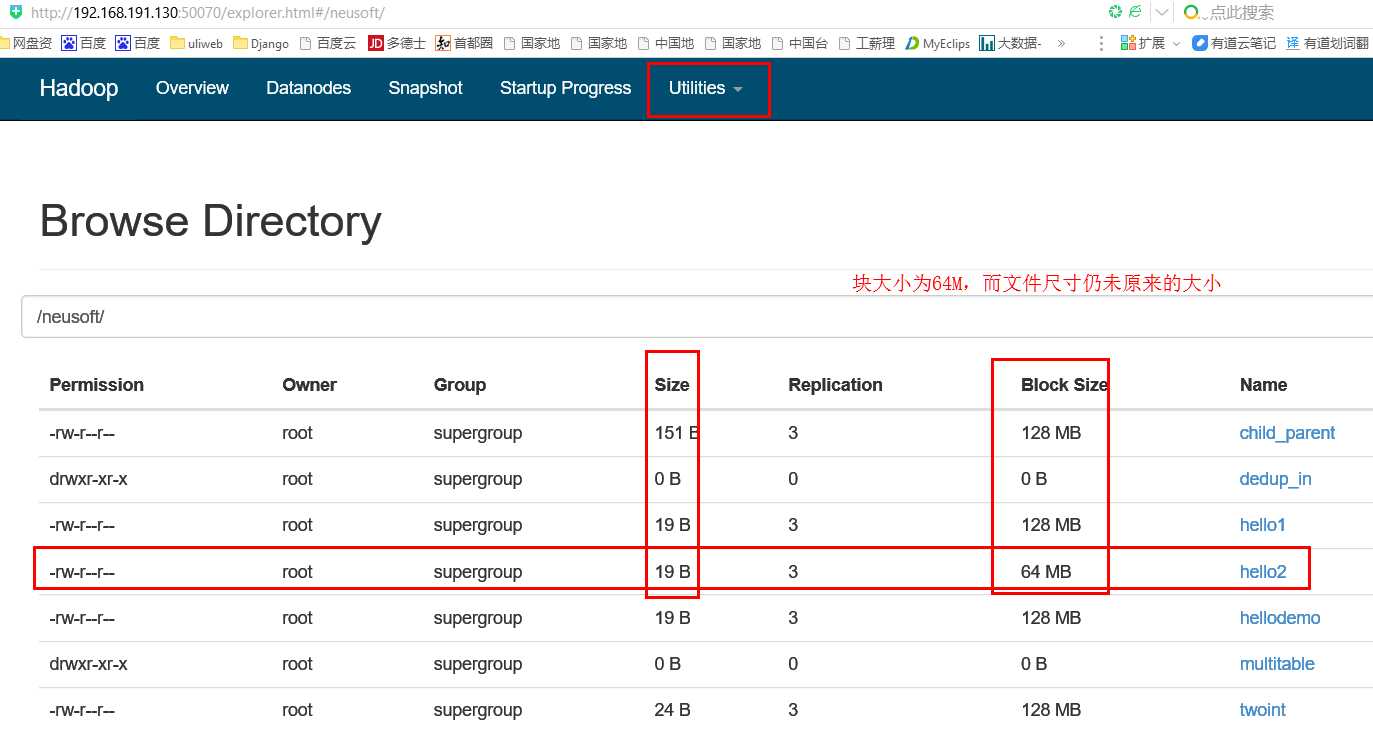
(2)修改数据块的测试:
[root@neusoft-master filecontent]# hdfs dfs -Ddfs.blocksize=67108864 -put hellodemo /neusoft/hello2
![]()
源数据信息:![]()
上传之后在hdfs的配置目录查看,其大小等于19字节,而非64M
或者 下面通过浏览器查看:
http://192.168.191.130:50070/explorer.html#/neusoft/ #如果windows上配置了hosts,这里可以写主机名

注意区别:一个文件可以产生多个快,多个文件是不可能成为一个块信息的,处于减轻namenode的压力,最好的方式就是一个文件一个块
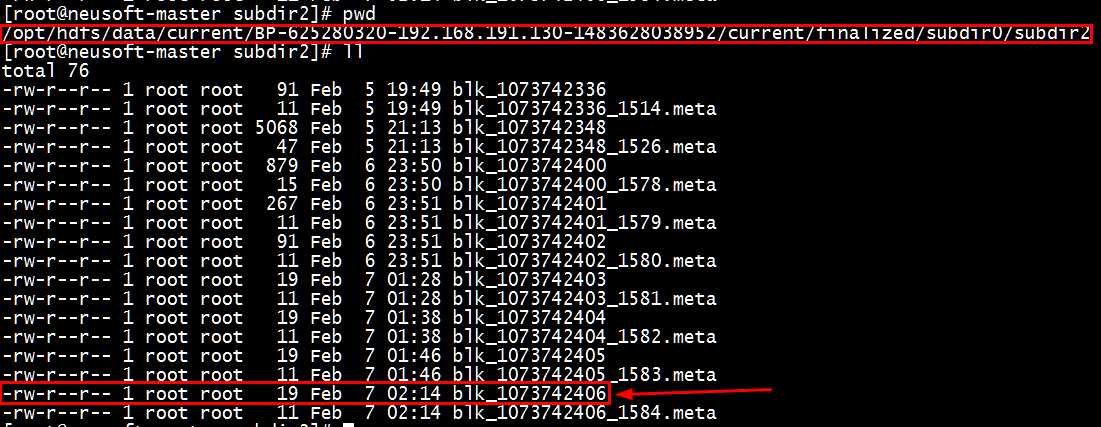
(3)文件块存放路径查看与具体信息解释
(a)查找datanode存放数据的位置,配置信息在hdfs-site.xml中
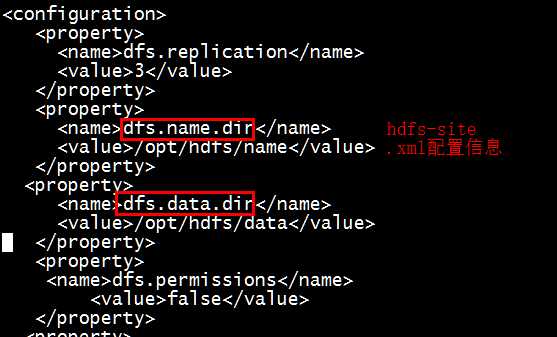
(b)进入datanode存放信息的目录查看
[root@neusoft-master subdir0]# cd /opt/hdfs/data/current/BP-625280320-192.168.191.130-1483628038952/current/finalized/subdir0/subdir0
可以查看到元数据的信息以及数据信息
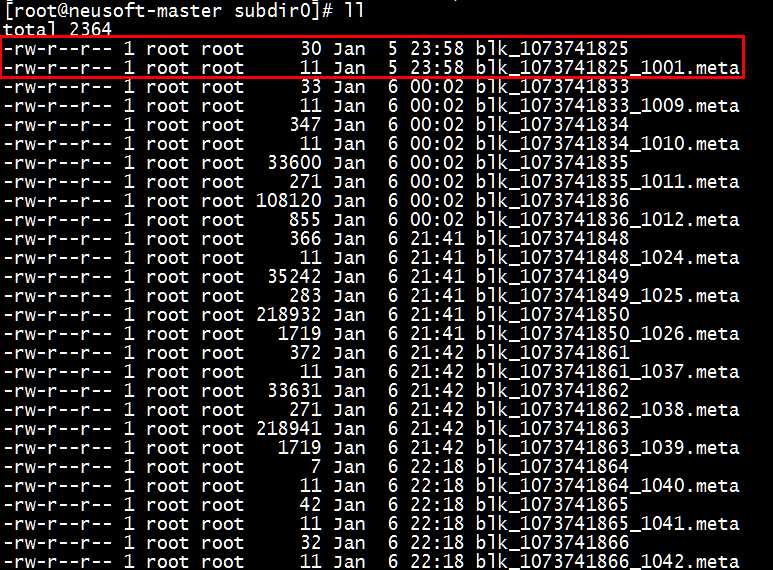
Tips:可以在本地新建一个文件,上传到HDFS中,查看是否增加了块信息。
副本机制:默认为3
vi hdfs-site.xml,可以修改,配置文件对全局生效
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
如果想一部分文件副本为3,一部分文件副本位2,这个需求也同样在命令行执行操作即可

[root@neusoft-master hadoop]# hdfs dfs -setrep 2 /neusoft/hello1
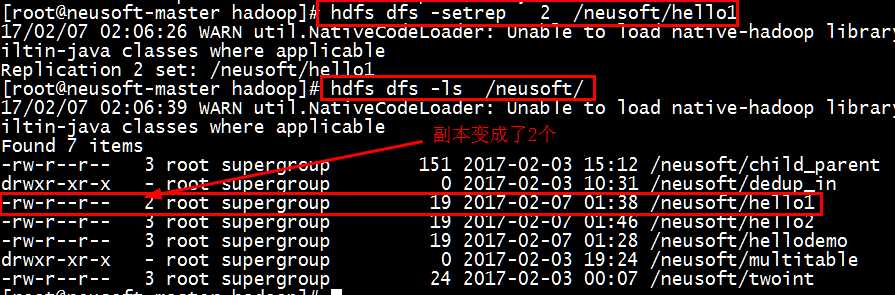
总结:DataNode
使用block形式存储。在hadoop2中,默认的大小是128MB。
使用副本形式保存数据的安全,默认的数量是3个。
标签:客户端 apache figure empty types 个数 balance replicat image
原文地址:http://www.cnblogs.com/jackchen-Net/p/6506321.html