设离散无记忆信源X包含N个符号{x1,x2,…,xi,..,xN},信源发出K重符号序列,则此信源可发出N^k个不同的符号序列消息,其中第j个符号序列消息的出现概率为PKj,其信源编码后所得的二进制代码组长度为Bj,代码组的平均长度B为
设某信道有r个输入符号,s个输出符号,信道容量为C,当信道的信息传输率R<C,码长N足够长时,总可以在输入的集合中(含有r^N个长度为N的码符号序列),找到M ((M<=2^(N(C-a))),a为任意小的正数)个码字,分别代表M个等可能性的消息,组成一个码以及相应的译码规则,使信道输出端的最小平均错误译码概率Pmin达到任意小。
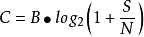
注:B为信道带宽;S/N为信噪比,通常用分贝(dB)表示。
香农第三定理(保失真度准则下的有失真信源编码定理)
保真度准则下的信源编码定理,或称有损信源编码定理。只要码长足够长,总可以找到一种信源编码,使编码后的信息传输率略大于率失真函数,而码的平均失真度不大于给定的允许失真度,即D‘<=D.
设R(D)为一离散无记忆信源的信息率失真函数,并且选定有限的失真函数,对于任意允许平均失真度D>=0,和任意小的a>0,以及任意足够长的码长N,则一定存在一种信源编码W,其码字个数为M<=EXP{N[R(D)+a]},而编码后码的平均失真度D‘(W)<=D+a。
行程编码
RLE(Run LengthEncoding行程编码)算法是一个简单高效的无损数据压缩算法,其基本思路是把数据看成一个线性序列,而这些数据序列组织方式分成两种情况:一种是连续的重复数据块,另一种是连续的不重复数据块。对于连续的重复数据快采用的压缩策略是用一个字节(我们称之为数据重数属性)表示数据块重复的次数,然后在这个数据重数属性字节后面存储对应的数据字节本身,例如某一个文件有如下的数据序列AAAAA,在未压缩之前占用5个字节,而如果使用了压缩之后就变成了5A,只占用两个字节,对于连续不重复的数据序列,表示方法和连续的重复数据块序列的表示方法一样,只不过前面的数据重数属性字节的内容为1。一般的这里的数据块取一个字节,这篇文章中数据块都默认为一个字节。为了更形象的说明RLE算法的原理我们给出最原始的RLE算法:
给出的数据序列为:A-A-A-A-A-B-B-C-D
未压缩前:A-A-A-A-A-B-B-C-D
(0x41-0x41-0x41-0x41-0x41-0x42-0x42-0x43-0x44)
压缩后:5-A-2-B-1-C-1-D
(0x05-0x41-0x02-0x42-0x01-0x43-0x01-0x44)
霍夫曼编码
霍夫曼编码使用变长编码表对源符号(如文件中的一个字母)进行编码,其中变长编码表是通过一种评估来源符号出现机率的方法得到的,出现机率高的字母使用较短的编码,反之出现机率低的则使用较长的编码,这便使编码之后的字符串的平均长度、期望值降低,从而达到无损压缩数据的目的。
算数编码
术编码用到两个基本的参数:符号的概率和它的编码间隔。信源符号的概率决定压缩编码的效率,也决定编码过程中信源符号的间隔,而这些间隔包含在0到1之间。编码过程中的间隔决定了符号压缩后的输出。
给定事件序列的算术编码步骤如下:
(1)编码器在开始时将“当前间隔” [ L, H) 设置为[0,1)。
(2)对每一事件,编码器按步骤(a)和(b)进行处理
(a)编码器将“当前间隔”分为子间隔,每一个事件一个。
(b)一个子间隔的大小与下一个将出现的事件的概率成比例,编码器选择子间隔对应于下一个确切发生的事件相对应,并使它成为新的“当前间隔”。
(3)最后输出的“当前间隔”的下边界就是该给定事件序列的算术编码。
设Low和High分别表示“当前间隔”的下边界和上边界,CodeRange为编码间隔的长度,LowRange(symbol)和HighRange(symbol)分别代表为了事件symbol分配的初始间隔下边界和上边界。上述过程的实现可用伪代码描述如下:
set Low to 0
set High to 1
while there are input symbols do
take a symbol
CodeRange = High – Low
High = Low + CodeRange *HighRange(symbol)
Low = Low + CodeRange * LowRange(symbol)
end of while
output Low
算术码解码过程用伪代码描述如下:
get encoded number
do
find symbol whose range straddles the encoded number
output the symbol
range = symbo.LowValue – symbol.HighValue
substracti symbol.LowValue from encoded number
divide encoded number by range
until no more symbols
词典编码
LZW算法
LZW算法先将可能的信源符号,创建一个初始词典,然后再编码过程中,遇到词典中没有的短语就加到词典中,动态创建词典。
参考:
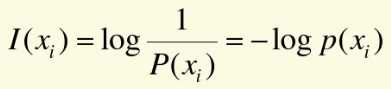

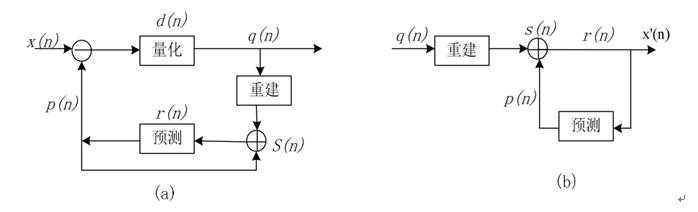
 帧间预测编码
帧间预测编码