标签:param 创建 png src raw_input request lib adl 发布
现在我们用XPath来做一个简单的爬虫,我们尝试爬取某个贴吧里的所有帖子,并且将该这个帖子里每个楼层发布的图片下载到本地。
# tieba_xpath.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import os
import urllib
import urllib2
from lxml import etree
class Spider:
def __init__(self):
self.tiebaName = raw_input("请需要访问的贴吧:")
self.beginPage = int(raw_input("请输入起始页:"))
self.endPage = int(raw_input("请输入终止页:"))
self.url = ‘http://tieba.baidu.com/f‘
self.ua_header = {"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1 Trident/5.0;"}
# 图片编号
self.userName = 1
def tiebaSpider(self):
for page in range(self.beginPage, self.endPage + 1):
pn = (page - 1) * 50 # page number
word = {‘pn‘ : pn, ‘kw‘: self.tiebaName}
word = urllib.urlencode(word) #转换成url编码格式(字符串)
myUrl = self.url + "?" + word
# 示例:http://tieba.baidu.com/f? kw=%E7%BE%8E%E5%A5%B3 & pn=50
# 调用 页面处理函数 load_Page
# 并且获取页面所有帖子链接,
links = self.loadPage(myUrl) # urllib2_test3.py
# 读取页面内容
def loadPage(self, url):
req = urllib2.Request(url, headers = self.ua_header)
html = urllib2.urlopen(req).read()
# 解析html 为 HTML 文档
selector=etree.HTML(html)
#抓取当前页面的所有帖子的url的后半部分,也就是帖子编号
# http://tieba.baidu.com/p/4884069807里的 “p/4884069807”
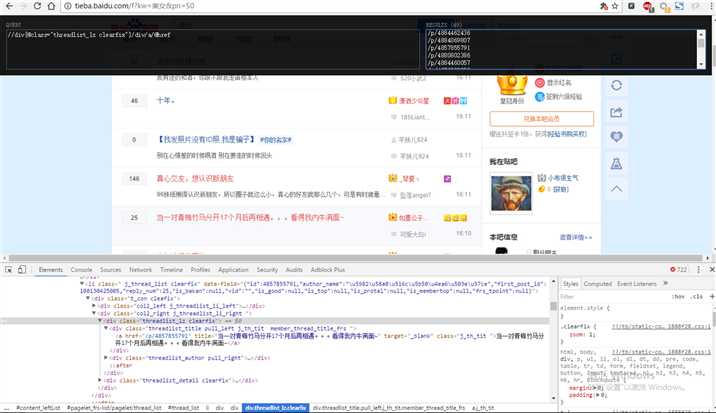
links = selector.xpath(‘//div[@class="threadlist_lz clearfix"]/div/a/@href‘)
# links 类型为 etreeElementString 列表
# 遍历列表,并且合并成一个帖子地址,调用 图片处理函数 loadImage
for link in links:
link = "http://tieba.baidu.com" + link
self.loadImages(link)
# 获取图片
def loadImages(self, link):
req = urllib2.Request(link, headers = self.ua_header)
html = urllib2.urlopen(req).read()
selector = etree.HTML(html)
# 获取这个帖子里所有图片的src路径
imagesLinks = selector.xpath(‘//img[@class="BDE_Image"]/@src‘)
# 依次取出图片路径,下载保存
for imagesLink in imagesLinks:
self.writeImages(imagesLink)
# 保存页面内容
def writeImages(self, imagesLink):
‘‘‘
将 images 里的二进制内容存入到 userNname 文件中
‘‘‘
print imagesLink
print "正在存储文件 %d ..." % self.userName
# 1. 打开文件,返回一个文件对象
file = open(‘./images/‘ + str(self.userName) + ‘.png‘, ‘wb‘)
# 2. 获取图片里的内容
images = urllib2.urlopen(imagesLink).read()
# 3. 调用文件对象write() 方法,将page_html的内容写入到文件里
file.write(images)
# 4. 最后关闭文件
file.close()
# 计数器自增1
self.userName += 1
# 模拟 main 函数
if __name__ == "__main__":
# 首先创建爬虫对象
mySpider = Spider()
# 调用爬虫对象的方法,开始工作
mySpider.tiebaSpider()
标签:param 创建 png src raw_input request lib adl 发布
原文地址:http://www.cnblogs.com/wzjbg/p/6507363.html