标签:bcd 工作 taf 并集 1.4 key for dataframe 技术分享
在pandas里面,另一种数据何必运算也被称为连接(concatenation)、绑定(binding)或堆叠(stacking)。
Numpy有一个用于合并原始Numpy数组的concatenation函数:
In [4]: arr = np.arange(12).reshape((3, 4)) In [5]: arr Out[5]: array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]]) In [7]: np.concatenate([arr, arr], axis=1) Out[7]: array([[ 0, 1, 2, 3, 0, 1, 2, 3], [ 4, 5, 6, 7, 4, 5, 6, 7], [ 8, 9, 10, 11, 8, 9, 10, 11]])
需要考虑的问题:
1. 如果各对象其他轴上的索引不同, 那些轴应该是做并集还是交集?
2. 结果对象中的分组需要各不相同吗?
3. 用于连接的轴重要吗?
用concat将值和索引粘合在一起:
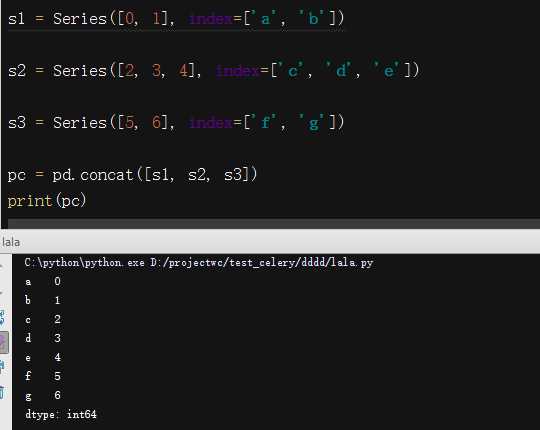
默认情况下, concat是在axis=0上工作。如果传入传入axis=1, 则结果就会变成一个DataFrame
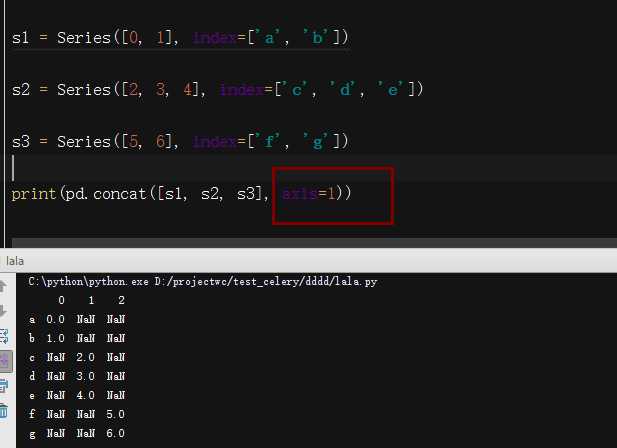

指定索引名称:join_axes

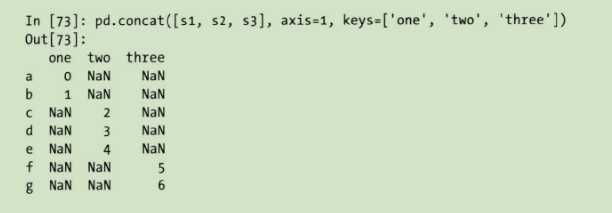
如果参与连接的片段中区分不开。假设你想要在连接轴上创建一个层次化索引。使用keys参数即可达到这个目的:

如果使用unstack()方法呢

如果沿着axis=1对Series进行合并, 则keys就会成为DataFrame的列头:
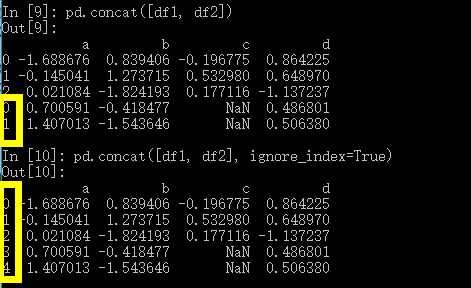
DataFrame的对象也是一样:


In [2]: from pandas import Series, DataFrame In [3]: import pandas as pd In [4]: import numpy as np In [5]: df1 = DataFrame(np.random.randn(3, 4), columns=[i for i in "abcd"]) In [6]: df2 = DataFrame(np.random.randn(2, 3), columns=[i for i in "bda"]) In [7]: df1 Out[7]: a b c d 0 -1.688676 0.839406 -0.196775 0.864225 1 -0.145041 1.273715 0.532980 0.648970 2 0.021084 -1.824193 0.177116 -1.137237 In [8]: df2 Out[8]: b d a 0 -0.418477 0.486801 0.700591 1 -1.543646 0.506380 1.407013

标签:bcd 工作 taf 并集 1.4 key for dataframe 技术分享
原文地址:http://www.cnblogs.com/renfanzi/p/6484438.html
