标签:导致 测试 sel logs 情况 ima iperf 最大 个数
cmm03 刀片 和 cmm02刀片的 cpu的型号是一样的:
2颗6核的物理CPU,开启了超线程
CPU型号: Intel(R) Xeon(R) CPU E5-2620 v2 @ 2.10GHz
cmm03上有10Gb, 56Gb 两张网卡, cmm02上有40Gb的网卡。
用iperf测试三种网卡的性能,由于2KB包长是最后江门取数的典型包长,下面的三组测试都是在2KB包长下,不同线程数时的带宽。
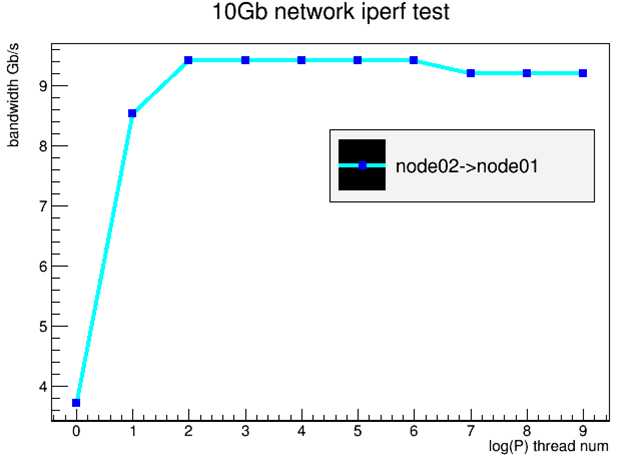
10Gb的网卡。在4个线程时,网卡性能达到最大值9.4Gb/s。
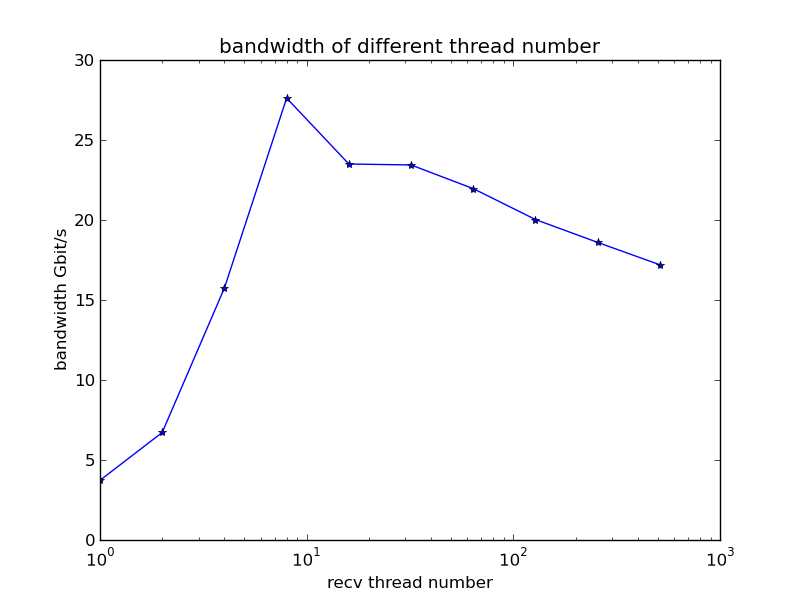
56Gb的网卡,在8个线程时达到27.62Gb/s,没有达到网卡的最大带宽,然后带宽随着线程数的增加逐渐降低。
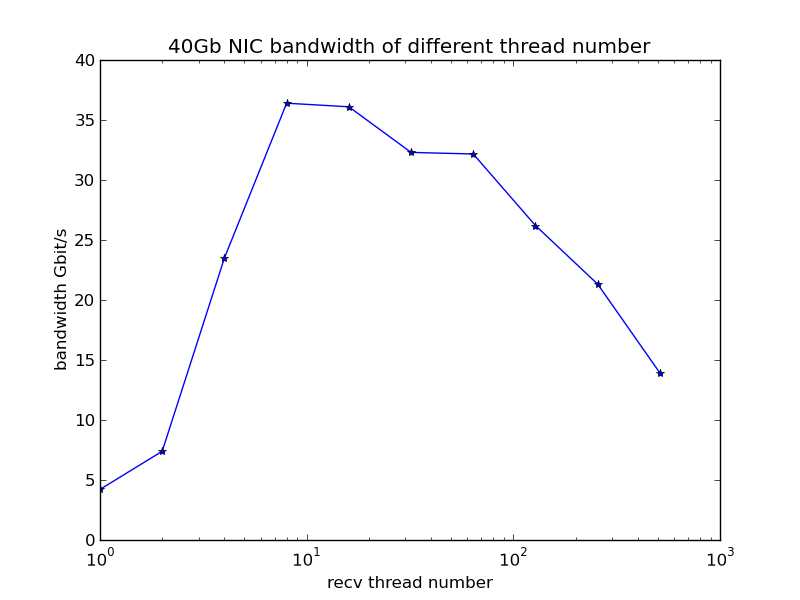
40Gb的网卡,在8个线程时带宽达到36.4Gb/s,线程数继续增加时,带宽逐渐降低。
上面三组测试结果能得出以下结论:
1. 同样的CPU,对不同的网卡,10Gb的网卡达到了极限性能,CPU有余;56Gb的网卡未达到极限性能,CPU不够用;40Gb的网卡在现有CPU能力下能到36.4Gb/s,接近网卡的最大性能。
2. 线程数超过8以后,多线程的开销增加会导致带宽的降低。
由以上的结论可知:
1. 应该将ROS布置在cmm02刀片上,能发挥网卡和CPU的最大能力,得到较好的性能;
2. 若采用单线程+select的接收数据的模型, 单个节点上ROS布置的个数为8较为合适(这是不考虑除了ROS线程以外的其他线程的情况下),考虑到还有发送数据到SFI的线程(还有其他线程吗?), 单个节点上布置的ROS个数应该小于8。
iperf对10Gb, 40Gb, 56Gb的网卡的性能测试
标签:导致 测试 sel logs 情况 ima iperf 最大 个数
原文地址:http://www.cnblogs.com/zengtx/p/6509056.html