标签:art 特征 algo lin stream nod lock cluster 分区

RDD是spark抽象的基石,可以说整个spark编程就是对RDD进行的操作
RDD是弹性的分布式数据集,它是只读的,可分区的,这个数据集的全部或者部分数据可以缓存在内存中,在多次计算间重用。所谓的弹性意思是:内存不够时可以与磁盘进行交换。这是RDD另一个特性:内存计算。就是将数据保存到内存中,同时为了解决内存容量大小的问题,他允许所有的数据我们可以自由的设置cache,和 是否cache
RDD的特征:
(1)有一个分片列表,就是这个RDD可以被切分,和hadoop一样,能被切分的数据才能并行计算
(2)每一个分片由一个函数计算,这个函数是compute函数
(3)对其他RDD的依赖列表,依赖分为:宽依赖和窄依赖(narrow)。并不是所有的RDD都有依赖
(4)可选:key-value型的RDD是根据哈希值来区分的,类似于mapreduuce的parttioner接口,控制key分配到那个reduce
(5)可选:每一个分片的优先计算位置,就像hdfs的block的位置是优先计算的
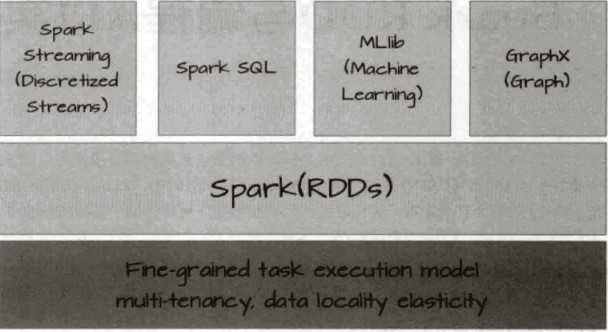
基于RDD进行抽象,spark可以以一致的方式处理不同的大数据场景,包括mapreduce,streaming,sql,maching learning以及Graph等,正是RDD让spark有了无可比拟处理大数据的平台的优势
RDD是一个容错的,并行的数据结构。可以让用户显示的将数据存储到磁盘或内存中,并能够控制数据的分区。
通常来讲,针对数据处理有不同的处理模型:iterative algorithms,relational queries,mapreduce, stream proccessing模型,比如hadoop使用的是mapreduce模型,strom使用是stream processing模型。而spark混合了这四种模型,所以spark可以处理各种大数据处理场景.
RDD的数据结构
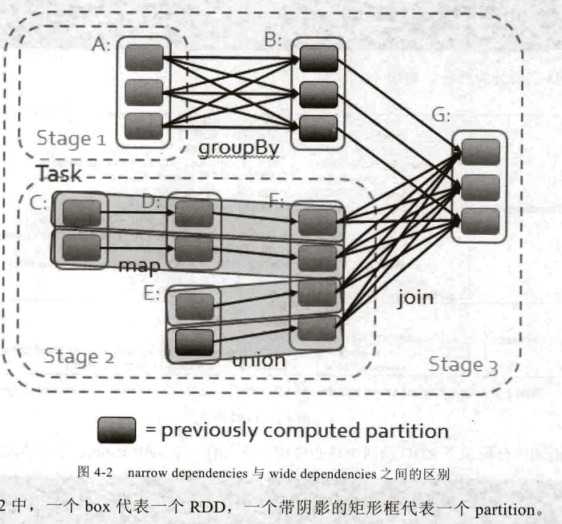
RDD作为数据结构,本质上是一个只读的,可分区的数据集,每一个分区都是一个datasets片段。RDD可以相互依赖,如果RDD的每一个分区都只能被一个child RDD使用,那这个RDD就是narrow(窄) dependency;如果RDD的每一个分区可以被多个child RDD使用,那么这个RDD就是shuffle(wide) dependency,不同的操作根据其特性会产生不同的依赖,比如:map操作会产生narrow dependency,keybyreduce会产生shuffle dependency。
spark将依赖分为narrow dependnecy和shuffle dependency主要是因为两点:
一:narrow dependency可以支持在同一个cluster node上以pipeline的形式执行多条命令。shuflle dependency要求所有的父分区都是可用的
二:从失败恢复的角度考虑
narrow dependency的恢复更加有效,因为它只需要重新计算丢失的parent parttion就可,并且可以并行的在不同的节点进行计算。而shuffle dependency它涉及到RDD各级多个parent parttions
解析spark RDD
标签:art 特征 algo lin stream nod lock cluster 分区
原文地址:http://www.cnblogs.com/zhangXingSheng/p/6512439.html