标签:类别 下载 asi 最大的 sam 数组 blank gui ict
scikit-learn是一个基于NumPy、SciPy、Matplotlib的开源机器学习工具包。採用Python语言编写。主要涵盖分类、
回归和聚类等算法,比如knn、SVM、逻辑回归、朴素贝叶斯、随机森林、k-means等等诸多算法,官网上代码和文档
都非常不错,对于机器学习开发人员来说。是一个使用方便而强大的工具,节省不少开发时间。
scikit-learn官网指南:http://scikit-learn.org/stable/user_guide.html
sklearn 中的数据一般存放为二维数组,形状为 [n_samples, n_feartures]。比如著名的 iris 数据集(鸢尾花)包含了三种类别的花(target),共 150 组数据(samples),每组数据由 4 个特征组成,具体来说就是:萼片的长度、萼片的宽度、花瓣的长度、花瓣的宽度。那么,iris 数据集的 data 就由 150*4 的二维数组组成。
sklearn 提供了很多数据集,一类比较小,直接打包在库中,可以通过 datasets.load_ + Tab 来查看,另一类比较大,需要下载,可以通过 datasets.fetch_ + Tab 查看,下载的目录可以通过sklearn.datasets.get_data_home()查看。
更详细的信息请参考 notebook 中的 02_sklearn_data.ipynb 文件。
创建一个机器学习的模型很简单:
from sklearn.linear_model import LinearRegression model = LinearRegression() print model
所有模型提供的接口有:
监督模型提供:
非监督模型提供:
下面这个图展示了这些接口在机器学习模型中的位置:
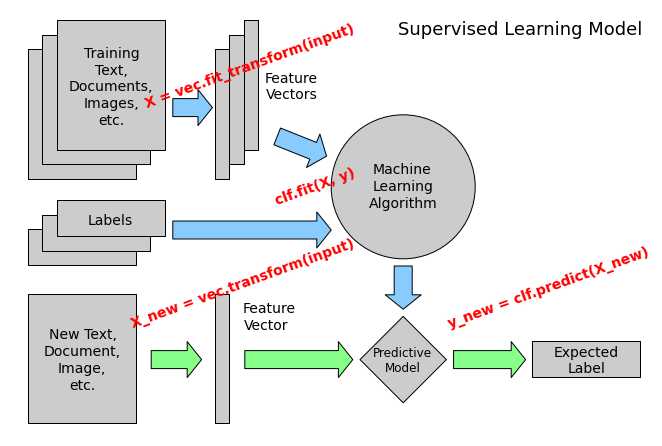
使用scikit-learn中的算法包kNN(k近邻)、SVM(支持向量机)、NB(朴素贝叶斯)来解决问题,解决问题的关键步骤有两个:
1、处理数据。2、调用算法
参考:http://www.cnblogs.com/daniel-D/
推荐博客:http://blog.csdn.net/u012162613/article/details/41929171
标签:类别 下载 asi 最大的 sam 数组 blank gui ict
原文地址:http://www.cnblogs.com/Allen-rg/p/6523290.html