? 方案适用场景:对RDD执行reduceByKey等聚合类shuffle算子或者在Spark SQL中使用group by
语句进行分组聚合时,比较适用这种方案。
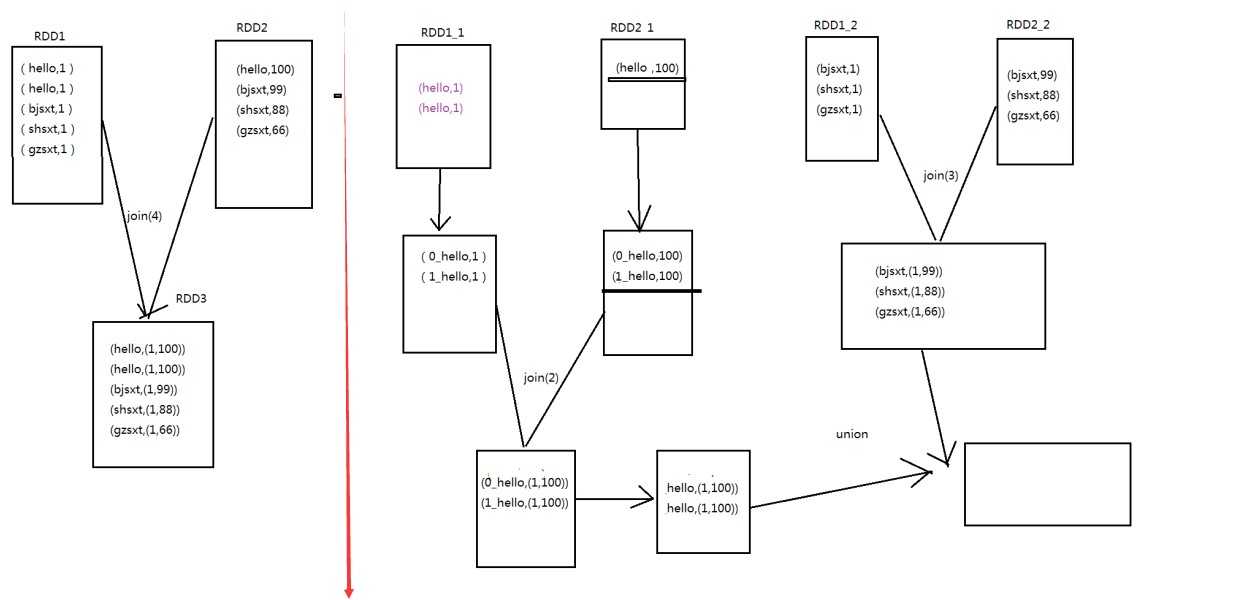
? 方案实现思路:这个方案的核心实现思路就是进行两阶段聚合。第一次是局部聚合,先给每个key
都打上一个随机数,比如10以内的随机数,此时原先一样的key就变成不一样的了,比如(hello, 1)
(hello, 1) (hello, 1) (hello, 1),就会变成(1_hello, 1) (1_hello, 1) (2_hello, 1) (2_hello, 1)。接着
对打上随机数后的数据,执行reduceByKey等聚合操作,进行局部聚合,那么局部聚合结果,就会
变成了(1_hello, 2) (2_hello, 2)。然后将各个key的前缀给去掉,就会变成(hello,2)(hello,2),再次
进行全局聚合操作,就可以得到最终结果了,比如(hello, 4)。
? 方案实现原理:将原本相同的key通过附加随机前缀的方式,变成多个不同的key,就可以让原本被
一个task处理的数据分散到多个task上去做局部聚合,进而解决单个task处理数据量过多的问题。
接着去除掉随机前缀,再次进行全局聚合,就可以得到最终的结果