标签:之间 测试数据 develop 矩阵分解 log sys 介绍 制造 ini
异常检测,广泛用于欺诈检测(例如“此信用卡被盗?”)。 给定大量的数据点,我们有时可能想要找出哪些与平均值有显着差异。 例如,在制造中,我们可能想要检测缺陷或异常。 我们展示了如何使用高斯分布来建模数据集,以及如何将模型用于异常检测。
我们还将涵盖推荐系统,这些系统由亚马逊,Netflix和苹果等公司用于向其用户推荐产品。 推荐系统查看不同用户和不同产品之间的活动模式以产生这些建议。 在这些课程中,我们介绍推荐算法,如协同过滤算法和低秩矩阵分解。
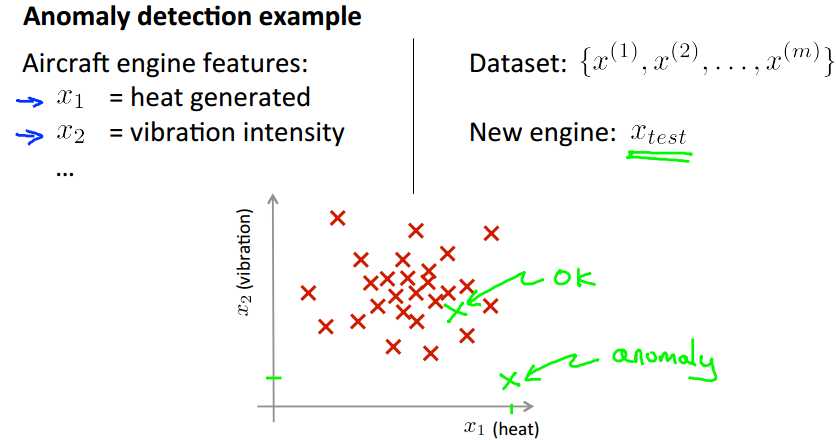
上面是一个异常检测的例子。一个飞机发动机生厂商,需要检测新生产的发动机是否正常。使用的feature为产热,震动程度等,根据上面的可视化,我们可以很直观的看出异常检测的思想:那些远离主体分布的点,我们就把它们当作异常点来处理。所以在后面的讨论中,我们的主要目的就是如何来选择这个“主体区域”。
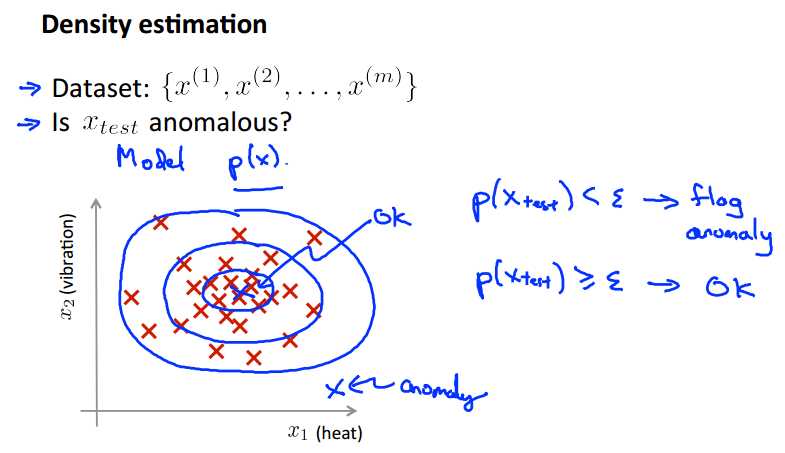
我们需要做一个关于观测数据分布的密度估计,建立一个概率模型,数据出现在数据集中心的概率很高,然后越向外扩张,概率就越小。所以,我们设置一个阈值sigma,当我们的测试数据的应用于模型的概率小于这个阈值时,我们就把它标记为 异常值。总的来说,异常检测有如下步骤:

1.设计用户活动的feature,这里可以是针对购物帐户,工厂产品等;
2.根据数据集建立概率模型P(x);
3.通过检测测试数据P(xtest)是否小于阈值Sigma,来判定它是否为异常点。

有概率论基础的同学都知道高斯分布,又称为正太分布。均值mu,方差sigma^2.其概率曲线是一个“钟形”对称图形,其中mu是对称轴,sigma是数据分布的宽度。在此不再赘述。
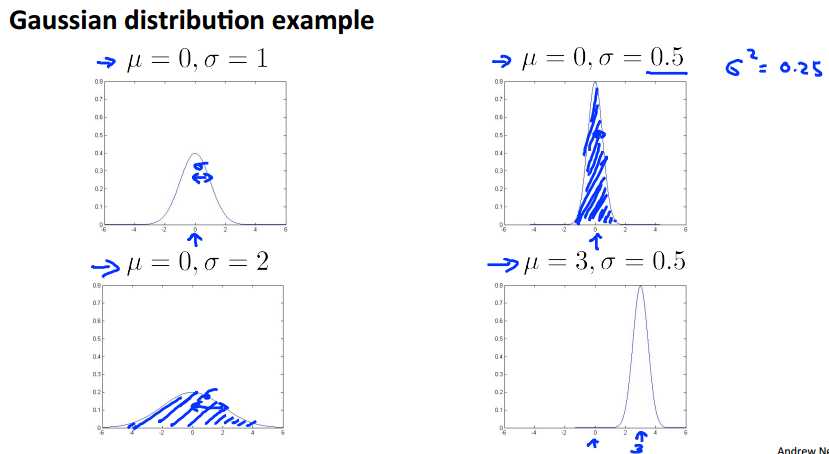
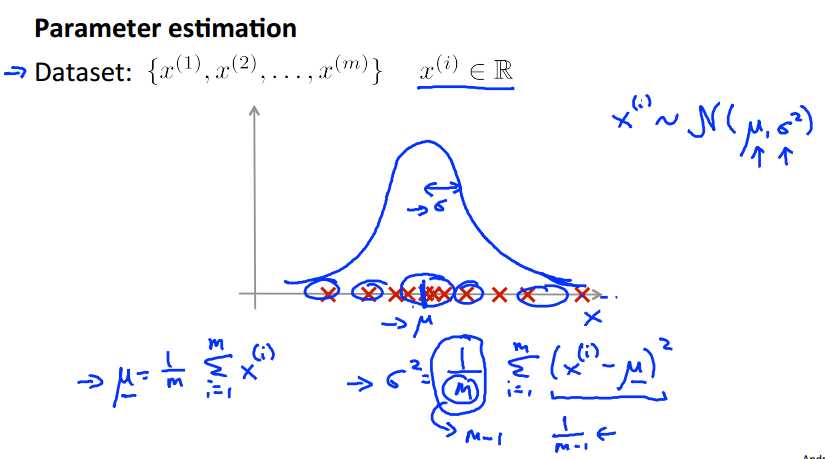
其分布的基本特点是大部分数据都分布在以mu为中心的一段区域中,越向两边延伸概率越小。

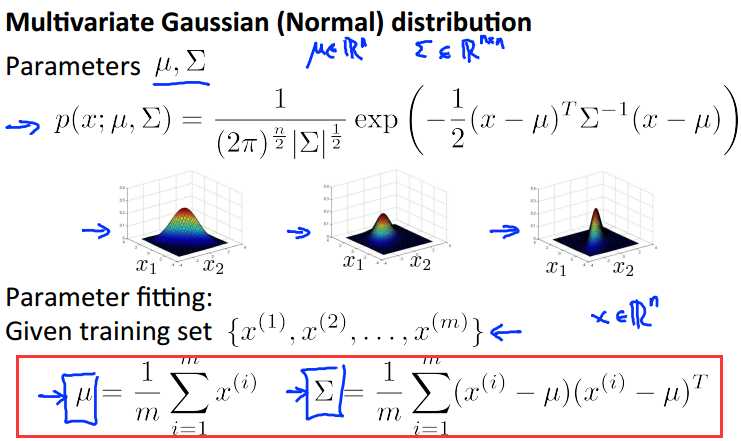
假设每个feature都服从不同的高斯分布N(u1,a^2),N(u2,a^2),.....,我们要建立的概率模型就是使用概率的乘法规则,P(x) = P(x1)*p(x2)*....*p(xn)。
一定要注意,这里是认为feature都来自不同的高斯分布。

这里所讲的步骤和上面一样,主要解释了关于P(x)模型的建立,也就是求解参数mu,和sigma,上面画框部分就是计算公式。
下面是一个例子,我们建立起一个二维模型P(x) = p(x1)*p(x2)。
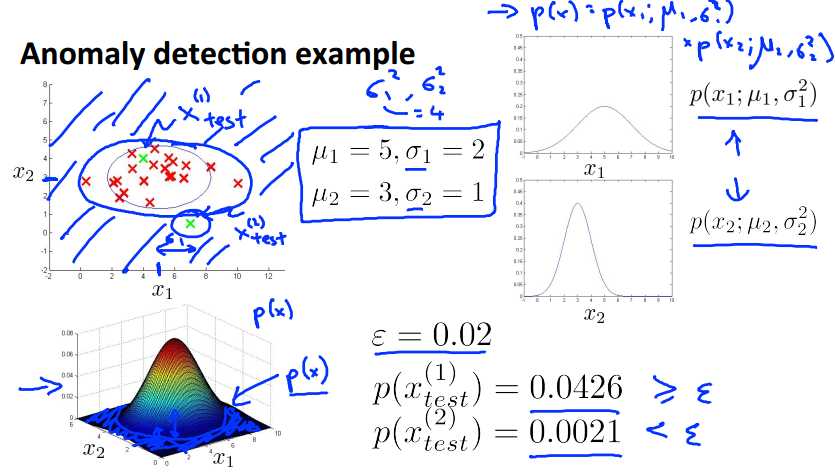
设置阈值为0.02,有两个测试数据,p(Xtest1) = 0.0426 >= 0.02,所以定义为正常点;而p(Xtest2) = 0.0021 < 0.02,标记为异常点。从上面高斯分布的二维图,可以看到,最高点就是(u1,u2),越往下概率越小,当小于阈值时,就把它标记为异常点,思想极其简单。
我们知道,如果可以用一个数值来评判一个算法的好坏,这个对于算法的选择是很大的帮助,那么我们如何来评价一个异常检测系统的好坏呢?
其实这个和监督性学习的评价标准类似。
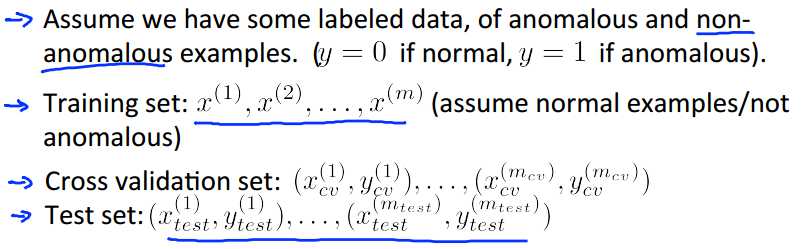
假设我们有含标记的数据集,y=0表示正常,y=1表示异常。
同样的,我们也将数据集分为training Set,Cross Validation Set和Test set。不同的是,我们的training set只包含正常点,即y=0的点。
再来看看之前的例子。

有10000个正常样本,和20个异常样本,怎么来分配?
training set:只包含6000个正常样本(y=0) ->训练得到概率模型P(x);
CV:2000个正常样本,10个异常样本,用于模型判定和选择;
Test:4000正常样本,10个异常样本,用于测试。

这里我们依然使用F1-score来评价模型好坏,这个和之前的用法一样,忘记的同学可以查以前的笔记。根据CV测试的结果选择最好的模型。
上面讲到了很多异常检测和监督性学习的相似之处,下面我们来谈谈它们之间的区别。

总的来说有以下几点:
1.异常检测的y=1的样本极少(通常只有0-20),而有大量的y=0的样本;相对于监督学习,y=0和y=1的样本都较多;
2.异常检测的异常值通常有很多种类型,所以算法无法学习到它们的特征;而监督学习的样本特征是可以通过足够的样本学习到的;
3.需要检测的异常值在之前的训练中很可能是没有出现过的;而监督学习的测试样本却更可能是之前出现过的。
下面给出应用范围的比较:

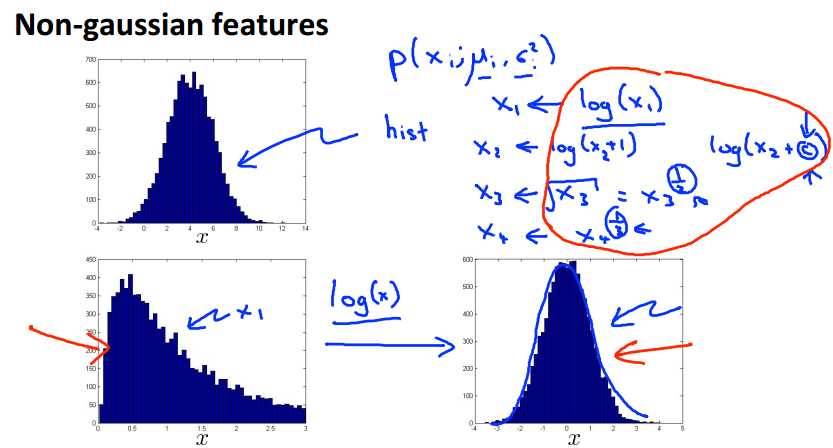
通过log,或者指数函数,将feature转化成较为明显的高斯分布,这种对称的“钟形”曲线。
这是我们设计模型的目标:使正常样本的概率偏大,使异常样本的概率偏小。

所以有时候我们需要根据实际情况自己设计合理的feature。

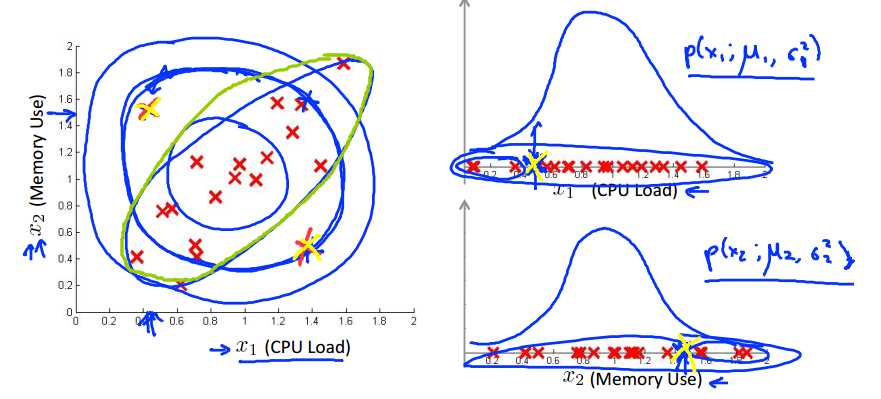
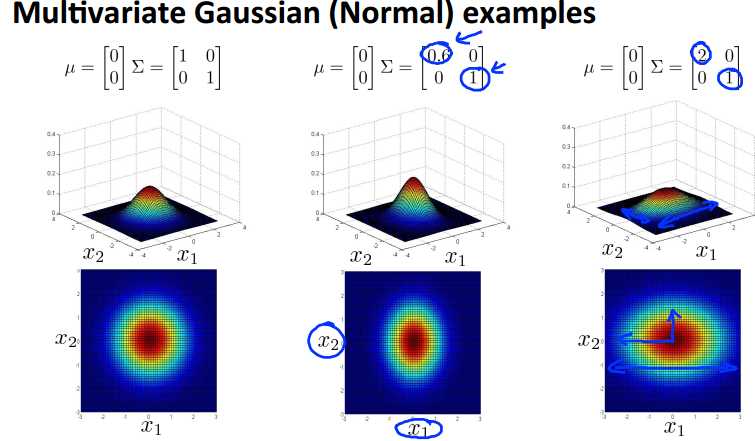
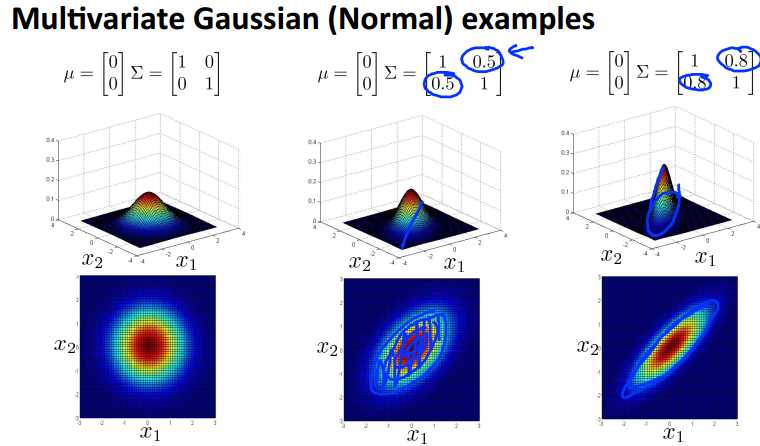
如果按照之前我们讨论的高斯模型来看,我们的概率应该是按照左图中蓝色圈的方向递减的,那么图中的黄色点应该是概率比较高,但是图中数据趋势明显是沿45度展开的,按理说黄色点更应该是异常点,可是在我们之前的模型中却认为他们是正常的,所以我们下面将引入混合高斯模型来解决这个问题。

不再对每个feature单独建模,而是使用统一的模型,参数是n维向量u和n×n的协方差矩阵Sigma。下面是一些混合高斯模型的例子。
上面是混合高斯模型的函数表示,和参数求解公式。

关于算法步骤,和之前的高斯分布类似,只是现在参数不同而已。使用混合高斯分布,便可以拟合出上面的分布,可以看出和标准的高斯分布的明显区别吧。

混合高斯模型和传统高斯模型的关系:当混合高斯模型的协方差矩阵为对角矩阵时,就是对应的传统高斯模型,而对角以外的参数,就控制着高斯分布的方向。

上面是传统高斯分布和混合高斯分布的对比,混合高斯分布有更高的计算复杂度,但是可以自己捕捉相关feature,使用时必须满足m > n,保证协方差矩阵Sigma为可逆矩阵。
斯坦福机器学习视频笔记 Week9 异常检测和高斯混合模型 Anomaly Detection
标签:之间 测试数据 develop 矩阵分解 log sys 介绍 制造 ini
原文地址:http://www.cnblogs.com/yangmang/p/6537773.html