标签:title ring 结构 string类 href link .com head 它的
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:
()1)、Tag
就是html中的标签,如图所示
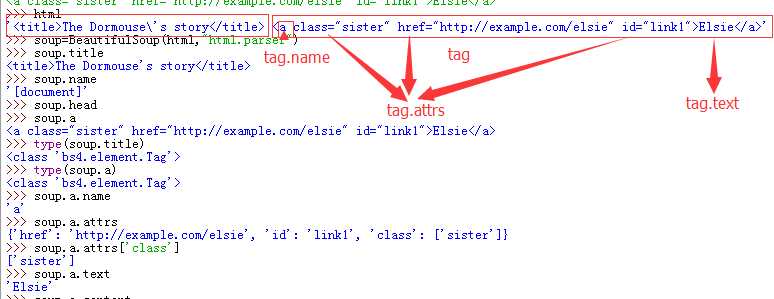
代码:
html ‘<title>The Dormouse\‘s story</title> <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>‘ >>> soup=BeautifulSoup(html,"html.parser") >>> soup.title <title>The Dormouse‘s story</title> >>> soup.name ‘[document]‘ >>> soup.head >>> soup.a <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a> >>> type(soup.title) <class ‘bs4.element.Tag‘> >>> type(soup.a) <class ‘bs4.element.Tag‘> >>> soup.a.name ‘a‘ >>> soup.a.attrs {‘href‘: ‘http://example.com/elsie‘, ‘id‘: ‘link1‘, ‘class‘: [‘sister‘]} >>> soup.a.attrs[‘class‘] [‘sister‘] >>> soup.a.text ‘Elsie‘
(2)NavigableString
要想获取标签内部的文字怎么办呢
很简单,用 .string 即可,例如
>>> soup.a.string ‘Elsie‘ >>>type(soup.a) <class ‘bs4.element.Tag‘> >>> type(soup.a.name) <class ‘str‘> >>> type(soup.a.text) <class ‘str‘> >>> type(soup.a.string) <class ‘bs4.element.NavigableString‘>
可以看出来,soup.a.sting获取到的是一个NavigableString类型
(3)BeautifulSoup
BeautifulSoup 对象表示的是一个文档的全部内容.大部分时候,可以把它当作 Tag 对象,是一个特殊的 Tag,我们可以分别获取它的类型,名称,以及属性来感受一下
>>> soup.name ‘[document]‘ >>> type(soup) <class ‘bs4.BeautifulSoup‘>
(4)Comment
Comment 对象是一个特殊类型的 NavigableString 对象,其实输出的内容仍然不包括注释符号,
>>> html="""<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>""" >>> soup=BeautifulSoup(html,"html.parser") >>> soup.a <a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a> >>> soup.a.string ‘ Elsie ‘ >>> soup.a.text ‘‘
标签:title ring 结构 string类 href link .com head 它的
原文地址:http://www.cnblogs.com/duole/p/6539714.html