标签:关系 进制 执行 数学 组成 深度 数据 中心 ppm
1、它是后面处理地图的基础,最简单的点云地图就是把不同位置的点云进行拼接得到的。
2、由于从RGB-D相机里可以采集到两种形式的数据:彩色图像和深度图像。如果有kinect和ros,那么可以运行如下
roslaunch openni_launch openni.launch
来使Kinect工作。如果PC机连上Kinect,那么彩色图像和深度图像会发布在/camera/rgb/image_color 和 /camera/depth_registered/image_raw 中;可以通过运行如下
rosrun image_view image_view image:=/camera/rgb/image_color
来显示彩色图像,或者也可以在Rviz里看到图像与点云的可视化数据。
3、rgb图像与对应的深度图像,如下


这两张图是来自于数据集nyuv2:http://cs.nyu.edu/~silberman/datasets/ 原图格式是ppm和pgm的,目前格式是png。
在实际的Kinect里(或其他rgb-d相机里)直接采到的RGB图和深度图可能会有些小问题,比如
1)有一些时差(约几到十几个毫秒)。这个时差的存在,会产生“RGB图已经向右转了,深度图还没转”的感觉。
2)光圈中心未对齐。因为深度毕竟是靠另一个相机获取的,所以深度传感器和彩色传感器参数可能不一致。
3)深度图里有很多“洞”。因为RGB-D相机不是万能的,它有一个探测距离的限制啦!太远或太近的东西都是看不见的呢。关于这些“洞”,我们暂时睁一只眼闭一只眼,不去理它。以后我们也可以靠双边bayes滤波器去填这些洞。但是!这是RGB-D相机本身的局限性。软件算法顶多给它修修补补,并不能完全弥补它的缺陷。
在以上给出的图当中,都进行了预处理,可以认为“深度图就是彩色图里每个像素距传感器的距离“。
4、现在需要把这两个图转成点云,因为计算每个像素的空间点位置,是后面配准、拼图等一系列事情的基础,比如:在配准时,必须知道特征点的3D位置,这时候就需要用到这里讲的东西。
5、从2D到3D(数学部分)
上面两张图像给出了机器人外部世界的一个局部信息,假设这个世界由一个点云来描述:X={x1,x2,...xn}。其中每一个点由六个分量组成:r,g,b,x,y,z,分别表示该点的颜色与空间位置;颜色方面,主要由彩色图像记录;而空间位置,可由图像和相机模型、姿态一起计算出来。
对于常规相机,SLAM里使用针孔相机模型(图来自http://www.comp.nus.edu.sg/~cs4243/lecture/camera.pdf ):
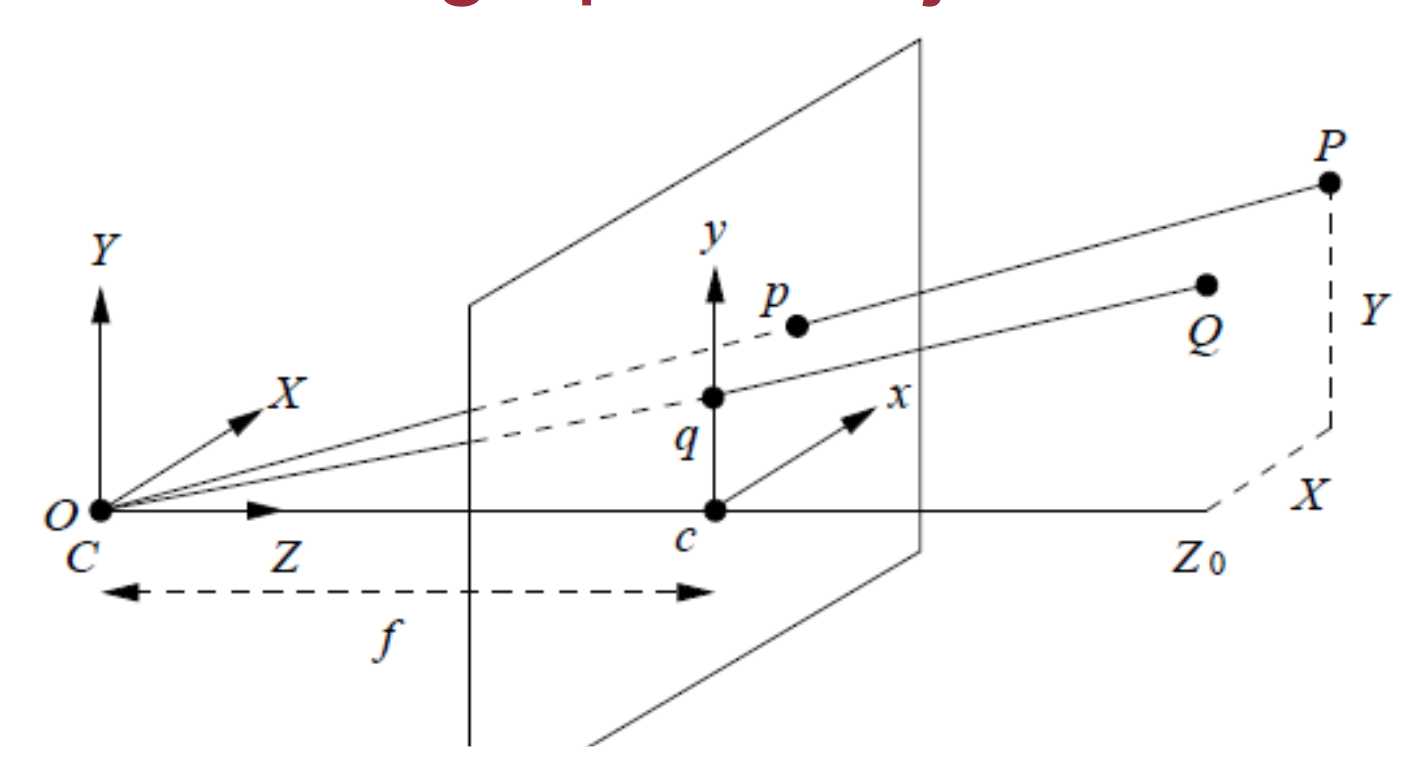
一个空间点[x,y,z]和它在图像中的像素坐标[u,v,d](d指深度数据)的对应关系式这样的:
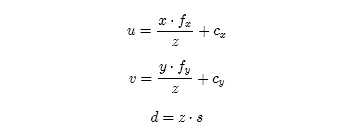
其中,fx,fy指相机在x,y两个轴上的焦距,cx,cy指相机的光圈中心,s指深度图的缩放因子。
上面的公式是从(x,y,z)推导到(u,v,d),反之,也可以已知(u,v,d),推导到(x,y,z)的方式,推导如下
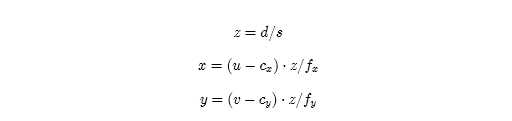
那么就可以根据上式构建点云了。
通常把fx,fy,cx,cy这四个参数定义为相机的内参矩阵C,也就是相机做好之后就不会变得参数。相机的内参可以用很多方法来标定,详细的步骤比较繁琐;在给定内参之后,每个点的空间位置与像素坐标就可以用简单的矩阵模型来表示了:
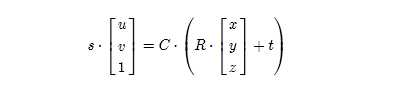
其中,R和t是相机的姿态。R代表旋转矩阵,t代表位置矢量。目前我们做的是单幅图像的点云,故认为相机没有旋转和平移;所以把R射程单位矩阵I,把t设成了零。s是scaling factor,即深度图里给的数据与实际距离的比例。由于深度图给的都是short (mm单位),s通常为1000。
如果相机发生了位移和旋转,那么只要对这些点进行位移和旋转操作即可。
6、从2D到3D (编程部分)
完成从图像到点云的转换,在上一节讲到的代码根目录/src/ 文件夹中新建一个generatePointCloud.cpp文件:
touch src/generatePointCloud.cpp

在一个工程里可以有多个main函数,因为cmake允许你自己定义编译的过程,我们会把这个cpp也编译成一个可执行的二进制,只要在cmakelists.txt里作相应的更改便行了,更改如下
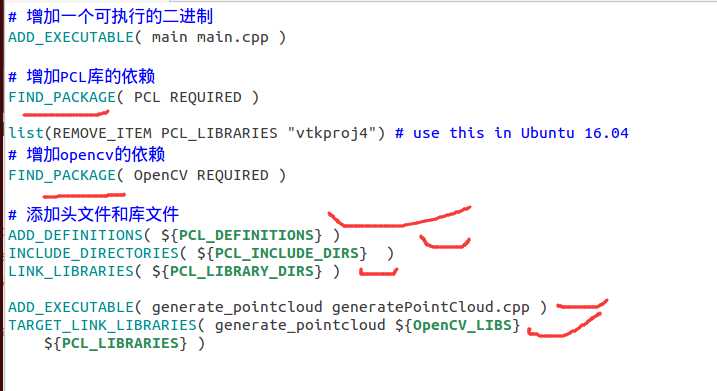
然后在新建的文件generatePointCloud.cpp里面编写如下代码
标签:关系 进制 执行 数学 组成 深度 数据 中心 ppm
原文地址:http://www.cnblogs.com/gary-guo/p/6542141.html