标签:pascal size 查询 估计 基础 不同的 流程 调度 and
【说明】今天白天有事外出了,晚上会图书馆做了下面的任务,时间有点紧,好多没完成,明天要补上今天的!
一:今日完成
1)插入数据时要注意主键约束
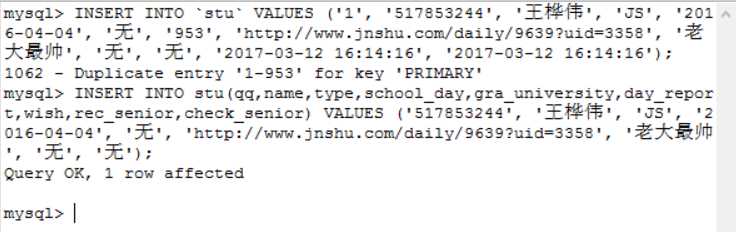
2)有了一个想法,将主键stu_id和online_id设置为自动增长,时间戳设置默认自动获取
然后有了下面的问题
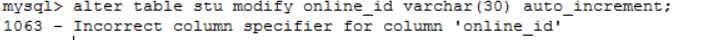
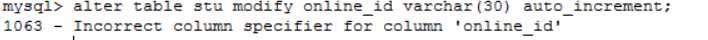
查过后发现:
自增列不能直接修改,必须将原有ID列删除,然后重新添加一列具有identity属性的ID字段。比如你要修改的字段名为ID:
alter table 表名 drop column ID
alter table 表名 add ID int identity(1,1)
为了不节外生枝,还是打消了给online_id 设置自增长,不过还要试一下时间戳的自动获取(插入数据的时候)
不过发现最开始创建表的时候时间戳的默认值是null

那就不能是add添加了,而应该是更改modify

不过下一条就没那么顺利了
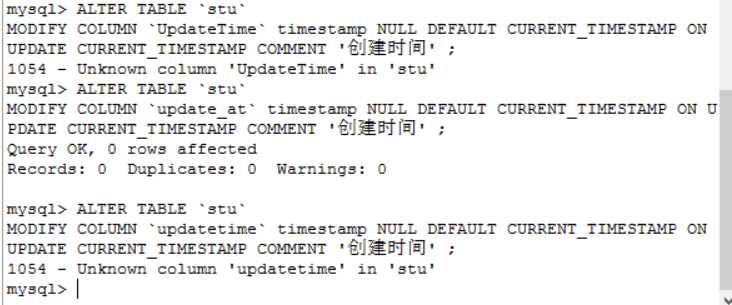
这才意识到createtime和updatetime是哪来的?但是createtime修改成功了,updatetime没有???
看了看表的设计,发现是这样的

这 和 “由数据数据库获取当前时间自动记录创建时间;”有什么区别??
原来是设置了默认更新时间,就是下面的update_at! 那create_at 呢??

再次确认了一下最开始的任务,发现:
create_at,update_at(所有的时间都用Long) 并没有指定时间类型是datetime还是datestamp ,看来是自己想多了,好了,不再纠结这个问题了
3)又想到可不可以随机生成大量模拟数据,然后插入?
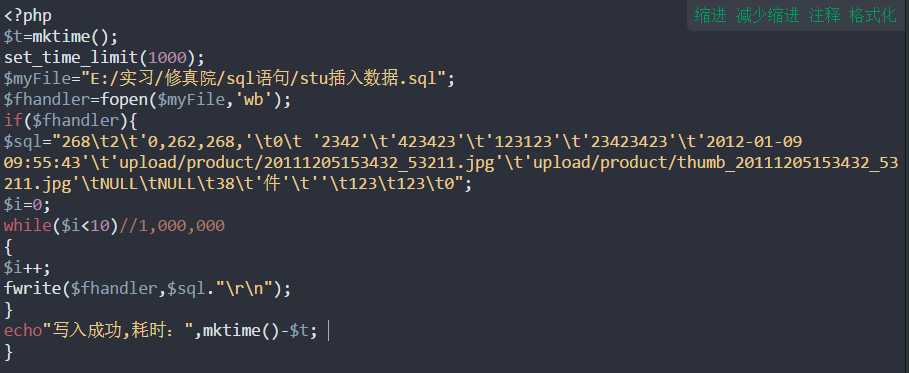
结果是php语句不会用,也看不懂【囧】
那试试另外的方法吧,比如

结果还是不行,不仅仅是因为这是从网上搜来的,还因为我根本就看不懂【(/ □ \)】,罢了罢了
4)一条一条插吧

好吧,循环了十遍,语句是一样的,反正是模拟数据!
5) 如果是比较有无索引情况下的查找速度,那我肯定是认为索引是可以加快速度的,不过还是看一下时间吧
下面是查看已经建立的索引

名?栏位?不都是column吗?!
这时候又有问题了,昨天的索引忘了怎么建了!!!幸好有日报!
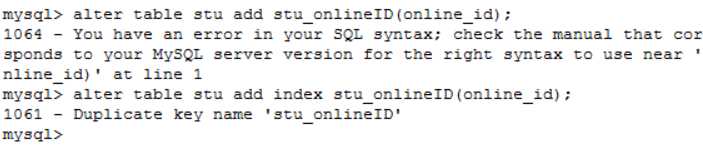
发现是先命名一个索引,再去添加到具体某一列的,那该怎么查呢
先等等,来看这个!
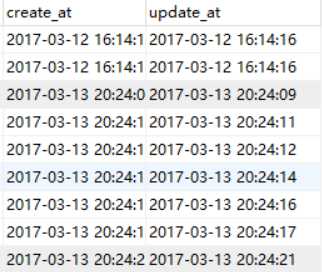
我明明插入的时间选择了3.12 ,可是,原来是之前设置获取当前时间的问题,也就是说之前的设置 起作用了!!!!
好,接下来继续测试 索引 的功能!
可是数据太少了,根本就不显示时间啊啊啊。那去看看别人怎么测!
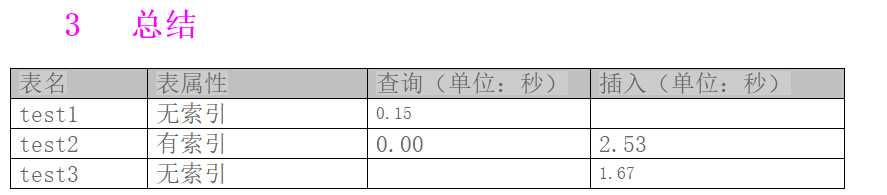
一目了然嘛,放上博客地址 http://blog.itpub.net/26736162/viewspace-1466094/
and http://lib.csdn.net/article/mysql/4248
这时又发现问题了,自己对数据库的了解真是渣啊,看看别人用的东西(reset query cache ; explain 使用解释:开启profile,用来查看sql执行时间),我要晕~~~~~~
1) 这个问题看过之后发现今天估计是给废了,,,理由看下面(这么多相关问题让我怎么回答!!??哭晕在厕所)
开始补上昨天没写的答案!
发现几个同门师兄写的不错

5.为什么DB的设计中要使用Long来替换掉Date类型?
自己理解:之前看的date类型有好多,比如YYMMDD,还有加上时分秒的,类型比较复杂,操作起来不如long方便,特别是插入数据的时候
参考同门:

6.自增ID有什么坏处?什么样的场景下不使用自增ID?
自己理解:
所有插入的数据id必须是顺序排列的,如果遇到id是无序的,不能自己操作
参考同门:
优点:节省时间,根本不用考虑怎么来标识唯一记录,写程序也简单了,数据库帮我们维护着这一批ID号。
缺点:for example, 在做分布式数据库时,要求数据同步时,这种自增ID就会出现严重的问题,因为你无法用该ID来唯一标识记录。同时在数据库做移植时,也会出现各种问题,总之,对此自增ID有依赖的情况,都有可能出现问题。
7.什么是DB的索引,多大的数据量下建索引会有性能的差别,什么样的情况下该对字段建索引?
自己理解:
有时候查数据的时候不是查出所有的,只是个别数据的话会遍历整个表,极大的影响效率,而建立的索引可以将之前查出的数据通过索引备份,下次查找的话优先查找索引,降低重复率。
参考同门:
表的主关键字
自动建立唯一索引
如zl_yhjbqk(用户基本情况)中的hbs_bh(户标识编号)
表的字段唯一约束
ORACLE利用索引来保证数据的完整性
如lc_hj(流程环节)中的lc_bh+hj_sx(流程编号+环节顺序)
直接条件查询的字段
在SQL中用于条件约束的字段
如zl_yhjbqk(用户基本情况)中的qc_bh(区册编号)
select * from zl_yhjbqk where qc_bh=’<????甼曀???>7001’
查询中与其它表关联的字段
字段常常建立了外键关系
如zl_ydcf(用电成份)中的jldb_bh(计量点表编号)
select * from zl_ydcf a,zl_yhdb b where a.jldb_bh=b.jldb_bh and b.jldb_bh=’540100214511’
查询中排序的字段
排序的字段如果通过索引去访问那将大大提高排序速度
select * from zl_yhjbqk order by qc_bh(建立qc_bh索引)
select * from zl_yhjbqk where qc_bh=’7001’ order by cb_sx(建立qc_bh+cb_sx索引,注:只是一个索引,其中包括qc_bh和cb_sx字段)
查询中统计或分组统计的字段
select max(hbs_bh) from zl_yhjbqk
select qc_bh,count(*) from zl_yhjbqk group by qc_bh
8.唯一索引和普通索引的区别是什么,什么时候需要建唯一索引。
自己理解:
区别是表的列有没有和其它列组合。当列属性查找频率极高,建议是唯一索引。
参考同门:
唯一索引(unique) :不允许任意两行具有相同索引值的索引。
主键索引(primary):数据表中经常有一列或多列组合,其职唯一标识要求主键中的每表中的每一行,则该列称为主键。个值都是唯一的,当查询时使用主键索引,他还允许对数据的快速访问。
聚集索引():表中行的物理顺序和表中的逻辑顺序相同。一个标志能有一个聚集索引。
如果一个索引不是聚集索引,则表中的数据的物理顺序和表中的逻辑顺序不相同。
9.如果对学员QQ号做了一个唯一索引,在插入数据的时候,是否需要先判断这个QQ号已经存在了?
自己理解:
不需要吧,索引和表中的数据是对应的,肯定存在。
参考同门:
唯一索引判重走的是索引,程序查询表判重走完索引还要返回给程序,显然唯一索引快。
要根据你的业务来确定:比如你这张表的数据在删除时并不是真正删除而是 将 is_deleted 字段设置为 1 这样你就不能依靠数据库的唯一索引在防止重复数据
肯定是建立唯一索引判断重复数据最安全,最保险
唯一索引,则由数据库判断,一次 insert 即可,然后程序捕获异常处理。在大多数情况下效率略高。
10.CreateAt和UpdateAt的意义分别是创建时间和修改时间,这两个时间应该在什么情况下赋值?是否应该开放给外部调用的接口?
自己理解:刚刚插入数据的时候给创建时间赋值,修改数据的时候给修改时间赋值。应该吧,这是客户应该知道的信息。
参考同门:
11.修真类型应该是直接存储Varchar,还是应该存储int?
自己理解:字符型和整形,你说呢。
参考同门:
int是整数型
varchar是字符串类型,并且varchar的字符串长度是可以变化的
因此varchar可以在数据长度不够的时候,按照实际的长度来分配空间,避免了空间浪费,但是在查询的时候会耗费一定的时间。
当然用varchar存数字也不是不可以,一般还是用int存数字,用varchar存字符串(不太用char)
12.varchar类型的长度怎么确定?有什么样的原则,和Text和LongText的区别是什么?
自己理解:一个varchar字符占4位,30位的长度按说可以容纳8个字符。必须是尽量多给。区别是varchar()是动态分配内存的
参考同门:
又查了一下varchar 字节和字符的关系:
4.0版本以下,varchar(20),指的是20字节,如果存放UTF8汉字时,只能存6个(每个汉字3字节) ;
5.0版本以上,varchar(20),指的是20字符,无论存放的是数字、字母还是UTF8汉字(每个汉字3字节),都可以存放20个,最大大小是65532字节 ;
又查了一下比特,字节,字符的关系
1位”表示为1bit
“1个字节”表示为1Byte
“1个字节”=“8位” 即1Bytes=8bit
因此“4个字节”=4*8位=32位
此外,字母用用1个字节(即8位)进行表示和存储,而一个汉字则使用两个字节(即16位)进行表示和存储。
两个字节表示一个有符号整数,范围是-32768~32767
一个字节表示一个有符号整数,范围是-128~127
13.怎么进行分页数据的查询,如何判断是否有下一页?
自己理解:
限制显示数据的数量,好像是limit关键字。看游标的末尾指向是不是当前显示的条数。
参考同门:
limit 后面两个量分别是 起始条数 和 取出的条数。
用变量来代替数值啊,这样才可以实现动态的分页
sql="select * from userdetail where userid limit " +((pageNow-1)*pageSize)+","+pageSize;
1)这里找到了插入大量重复数据的办法

实验过之后如下

对比如下:
还是有问题,不过是函数的

那该怎么办呢,研究一下navicat的命令行!
果然是有问题的

那该怎么办呢?此问题有待解决???
14.为什么不可以用Select * from table?
自己理解:
不可以用?我平时查看表的时候都是这样用的啊?!
参考同门:
可能是认为*会忽略索引全表扫描什么的,其实这关键看where字句怎么写.不过用select *会有一些额外的IO开销.最好还是写字段把,作为你的编程习惯.
*和列出全部字段在神马表扫描上没有区别。唯一有区别就是,*列出的字段是按照table的列来的,如果数据库那边把列换了位置,你就悲剧了。要是列出字段,就不存在这个问题了。这个没有任何效率可言
| 尽量在SELECT后写明列名,有很多好处,如:减少不必要的输出(网络包大小)、安全性等等.. |
| select * from table 还是要先被解释成 select all column from table |
还多一个查询数据字典的过程
跳着来,上面的问题留到后面【贱贱的表情】
1)先说自己没搜索前的看法:
jdk是java的类库,各种API,各种已有功能的实现都被java开发者放到了这个库里面。
jre是java运行时环境,编译的字节码.class文件需要在这里面被解释运行
2)再来看看网上的解释:
1、JVM -- java virtual machine
JVM就是我们常说的java虚拟机,它是整个java实现跨平台的 最核心的部分,所有的java程序会首先被编译为.class的类文件,这种类文件可 以
在虚拟机上执行,也就是说class并不直接与机器的操作系统相对应,而是经过虚拟机间接与操作系统交互,由虚拟机将程序解 释给本地系统执行。
JVM 是 Java 平台的基础,和实际的机器一样,它也有自己的指令集,并且在运行 时操作不同的内存区域。 JVM 通过抽象操作系统和 CPU 结构,
提供了一种与平台无关的代码执行方法,即与特殊的实现方 法、主机硬件、主机操作系统无关。但是在一些小的方面, JVM 的实现也是互不相同的,
比如垃圾回收 算法,线程调度算法(可能不同 OS 有不同的实现)。
JVM 的主要工作是解释自己的指令集(即字节码)到 CPU 的指令集或 OS 的系统调用,保护用户免被恶意程序骚扰。 JVM 对上层的 Java 源文件是不关心的,
它关注的只是由源文件生成的类文件( class file )。类文件的 组成包括 JVM 指令集,符号表以及一些补助信息。
2、JRE -- java runtime environment
JRE是指java运行环境。光有JVM还不能成class的 执行,因为在解释class的时候JVM需要调用解释所需要的类库lib。
在JDK的安装目 录里你可以找到jre目录,里面有两个文件夹bin和lib,在 这里可以认为bin里的就是jvm,lib中则是jvm工 作所需要的类库,而jvm和 lib和起来就称为jre。
所以,在你写完java程序编译成.class之后,你可以把这个.class文件 和jre一起打包发给朋友,这样你的朋友就 可以运行你写程序了。(jre里有运行.class的java.exe)
JRE 是 Sun 公司发布的一个更大的系统,它里面就有一个 JVM 。 JRE 就与具体的 CPU 结构和操作系统有关,
我们从 Sun 下载 JRE 的时候就看到了不同的各种版本。同 JVM 一起组成 JRE 的还有一些 API (如 awt , swing 等)。 JRE 是运行 Java 程序必不可少的。
JRE ( Java Runtime Environment ),是运行 Java 程序必不可少的(除非用其他一些编译环境编译成.exe可执行文件……),
JRE的 地位就象一台PC机一样,我们写好的Win32应用程序需要操作系统帮 我们运行,同样的,我们编写的Java程序也必须要JRE才能运行。
JRE里面有一个 JVM , JRE 与具体的 CPU 结构和操作系统有关,我们从 Sun 下载 JRE 的时候就看到了不同的各种版本,
同 JVM 一起组成 JRE 的还有 一些 API (如 awt , swing 等), JRE 是 运行 Java 程序必不可少的.
3、JDK -- java development kit
JDK是java开发工具包,基本上每个学java的人都会先在机器 上装一个JDK,
那他都包含哪几部分呢?让我们看一下JDK的安装目录。在目录下面有 六个文件夹、一个src类库源码压缩包、和其他几个声明文件。
其中,真正在运行java时起作用的 是以下四个文件夹:bin、include、lib、 jre。现在我们可以看出这样一个关系,JDK包含JRE,而JRE包 含JVM。
bin:最主要的是编译器(javac.exe)
include:java和JVM交互用的头文件
lib:类库
jre:java运行环境
(注意:这里的bin、lib文件夹和jre里的bin、lib是 不同的)总的来说JDK是用于java程序的开发,而jre则 是只能运行class而没有编译的功能。
eclipse、idea等 其他IDE有自己的编译器而不是用JDK bin目录中自带的,所以在安装时你会发现他们只要求你 选中jre路径就ok了。
二、 三者联系
Java 喊出的带有标志性的口号“ Write Once , Run Anywhere (一次编写,到处运行)”,正是建立在 JRE 的基础之上。何以实现?就是在 Java 应用程序和操作系统之间增加了一虚拟层—— JRE 。
程序源代码不是直 接编译、链接成机器代码,而是先转化到字节码( bytecode ) 这种特殊的中间形式,字节码再转换成机器码或系统调用。
前者是传统的编译方法,生成的机器代码就不可避免地跟特殊的操作系统和特殊的机器结构相关。
而 Java 程序的字节码文件可以放到任意装有 JRE 的计算机运行,再由不同 JRE 的将它们转化成相应的机器代码,这就实现了 Java 程序的可移植性。
这样程序员也不用去 关心程序运行的具体环境,而可以专心编写软件。这种分层抽象、隐藏细节的思想在计算机科学中处处可见,比如机器组织结构的设计、
网络协议的实现等。 Pascal 语言的发明者 Niklaus Wirth ,就富有预见性地指出应该有这样一种可移植的语言,其生成的中间代码可以在一台假想的机器( a hypothetical machine )上运行。
而 Java 虚拟机( Java virtual machine 或 JVM )就是这样的一台机器,它模拟实际处理器的结构,解释字节码。 怎么一会说是 JRE ,一会儿又成了 JVM ,两者是否同物不同名? 回答是否定的。
JRE的地位就象一台PC机一样,我们写好的Win32应用程序需要操作系统帮 我们运行,同样的,我们编写的Java程序也必须要JRE才能运行。
要运行Applet,在客户端必须安装有 JRE,即“运行时”,容易一点理解,就象所谓的“插件”,要开发JAVA应用程序\Web应用,就必须在服务器端安装相应的 JVM+JDK 了
开发应用 Java web应用 时,客户端不需要安装任何的JVM)
如果你使用JAVA开发应用,就需要安装 JRE+JDK,就是 J2SE.
如果在客户端运行Applet,客户端浏览器必须嵌有JAVA JVM,如果没有,就需要安装,即: 在客户端创建JRE(运行时,包含JVM),而客户端是不需要做开发的,所以,JDK就没有必要安装 了。
不同版本的Applet在不同的JVM下可能无法正常运行,而Microsoft JVM只是Sun JVM的“低版本”,微软在windows xp/2003中干脆将JVM去掉了.
3)一句话总结:java程序员通过依赖的jdk开发工具包编写java程序经过编译之后然后放在jre环境中的jvm中运行
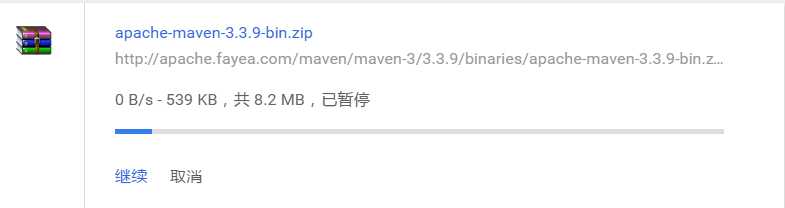
为什么这么慢!!!,马上图书馆就要闭馆了,呜呜呜~~~~~
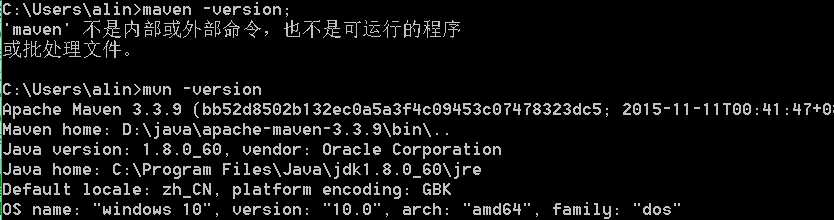
还有这个配置

二:明日计划
一定要充分考虑时间!一定要充分考虑时间!一定要充分考虑时间!
三:疑难问题
数据库的问题比较多。还有好多没解决,,
四:思考总结
这个回寝室用手机做,,,,
来了,趁着刚做完运动,思维敏姐敏捷!现在想来,自己查资料的时候有一个问题,那就是看过之后能不能几句话总结作者想说明白的东西并且模仿作者用到的方法,直到能化为己用!这些以后要注意!
技术总结就是Navicat的命令行工具不好用(可能是我不了解),明天查查去!
标签:pascal size 查询 估计 基础 不同的 流程 调度 and
原文地址:http://www.cnblogs.com/yishengyishiduaini321/p/6545236.html