标签:实现 匹配 计算公式 nbsp 过滤 不能 情况 strong 概率
目前大多数中文文本分类系统都采用词作为特征项,作为特征项的词称作特征词。这些特征词作为文档的中间表示形式,用来实现文档与文档、文档与用户目标之间的相似度计算 。
基于频率的过滤方法中,一条留言中一个词语出现一次以上都是按照一次计算。本文采用了长匹配优先的方式对其进行匹配。如果一个词语包含另一个词语,则被包含的词语的次数不能加一,例如第一条留言中出现“清楚”,包含“清”,第二条留言中包含“清”,则“清出现的次数只能是一次,而不是两次”,还有一种特殊情况是“松”被分作了两个词性,“松/a”和“松/ng”,对于这种情况我们把所有词语的词性去掉之后再统计这个词语出现的次数。
基于信息增益的过滤方法中,根据IG计算公式计算需要留下的IG值,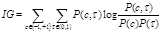
c表示类别,属于此类或者不属于;τ表示此特征出现与否,布尔型。若特征与类别无关,则IG=0。
基于条件概率比的过滤方法,根据下面公式计算,
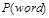 ,
,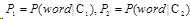
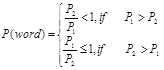
在这里越小越好,即其值越小越有意义,说明word在不同类别中出现的概率差异大。若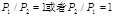
,说明word的出现与类别判断无关,可去掉;若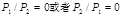
,说明word的出现与类别高度有关,此类词语需保留。
基于期望值差异的过滤方法,根据以下计算方法计算,一个词项word在类中出现的期望值=word在所有数据表中出现的总次数,令=word在类中出现的实际次数,则
, 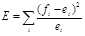
对于E值,E越大越有意义。
标签:实现 匹配 计算公式 nbsp 过滤 不能 情况 strong 概率
原文地址:http://www.cnblogs.com/nurbs/p/6568951.html