标签:日志 liunx 为什么 3.1 数据 image 基本 ado 脚本
首先,先明确,为什么Sqoop需要规范的脚本开发呢?
答:是因为,Sqoop import HDFS/Hive/HBase这些都是手动。但是在实际生产里,有时候,需要用脚本来完成。
比如,通过shell脚本来操作对Sqoop、Hive、HBase、MapReduce、HDFS、Spark、Storm等各种。
目录规范
1.目录结构体系
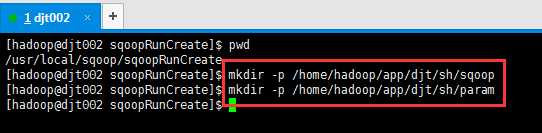
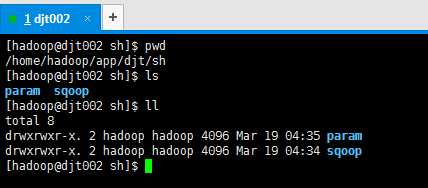
/home/hadoop(开发用户)/app/djt(数据来源、业务)/sh/sqoop
示例:/home/hadoop/app/djt/sh/sqoop (这里专门用来放sqoop开发脚本)
/home/hadoop/app/djt/sh/hive (这里专门用来放hive开发脚本)
/home/hadoop/app/djt/sh/hbase (这里专门用来放hbase开发脚本)
home/hadoop(开发用户)/app/djt(数据来源、业务)/sh/param (这里专门用来放参数)
示例:/home/hadoop/app/djt/sh/param
[hadoop@djt002 sqoopRunCreate]$ mkdir -p /home/hadoop/app/djt/sh/sqoop
[hadoop@djt002 sqoopRunCreate]$ mkdir -p /home/hadoop/app/djt/sh/param
2.脚本文件命名规范
2.1文件名规范:数据库类型_数据层_日期_表实体命名。
2.2文件扩展名规范:扩展名为sh。
示例:sq_ods_d_djt_user_copy.sh
sqoop就用sq , ods层(操作数据存储层)就用ods,mapreduce就用mr,表名是djt_user_copy。
3.脚本运行、调试、编辑
3.1脚本运行环境
在liunx操作系统上运行,通过命令方式调用脚本
3.2调用脚本和终止脚本
3.2.1可以用多种方式调用脚本如下
a)Sh 脚本名
b)./脚本名
c)Source 脚本名
/xxxx/xxx/脚本名 -----脚本的全路径
3.2.2终止脚本
通过ps命令查询到正在执行脚本的进程,用kill命令杀掉执行中的脚本。
ps –ef|grep 脚本名;
kill 脚本的进程
3.2.3编辑工具
使用linux系统自带的vi编辑,UE等
4.脚本注释说明
脚本中需要有基本的注释信息方便以后维护,如参数、执行示例、脚本存放位置、日志文件地址、创建人、创建日期等信息。
脚本注释示例:
###################################################################
#说明:将用户数据从HDFS导入MySQL
#参数CONNECTURL 说明:MySQL 连接地址 示例:jdbc:mysql://dajiangtai/djtdb_test
#参数USERNAME 说明:MySQL 账号 示例:root
#参数PASSWORD 说明:MySQL 密码 示例:root
#执行示例: sh /home/hadoop/app/djt/sh/sqoop/sq_ods_d_djt_user_copy.sh
#脚本存放地址:/home/hadoop/app/djt/sh/sqoop
#日志文件地址:/home/hadoop/app/djt/sh/log
#创建人:dajiangtai
#创建日期:20161201
#最新修改日期:20170101
#修改人、修改时间、修改内容:xxxxxxxxxxxxxxxxx
#修改人、修改时间、修改内容:xxxxxxxxxxxxxxxxx
###################################################################
5.脚本变量、参数命名规范
1)脚本变量命名
变量名:v_开头
2)参数命名
表名参数: v_tableName
导出字段参数:v_fields
导出文件目录:v_src
6.脚本环境变量配置文件规范
配置文件是脚本中用到的环境变量,mysql连接,公共脚本地址等都放到配置文件用方便以后管理。
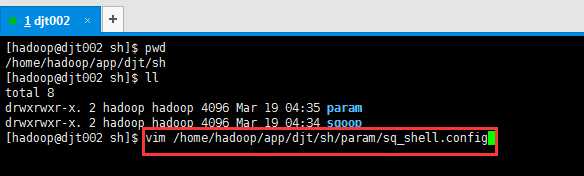
1) 配置文件存放路径及其命名配置文件路径及命名:/home/hadoop/app/djt/sh/param/sq_shell.config
2) 配置文件中示例内容如下
CONNECTURL=jdbc:mysql://dajiangtai/djtdb_test
USERNAME=root
PASSWORD=root
3) 配置文件编写规范:配置文件中以等号做分割符,第一列是变量名需要大写
7.编写脚本环境变量配置文件
vim /home/hadoop/app/djt/sh/param/sq_shell.config
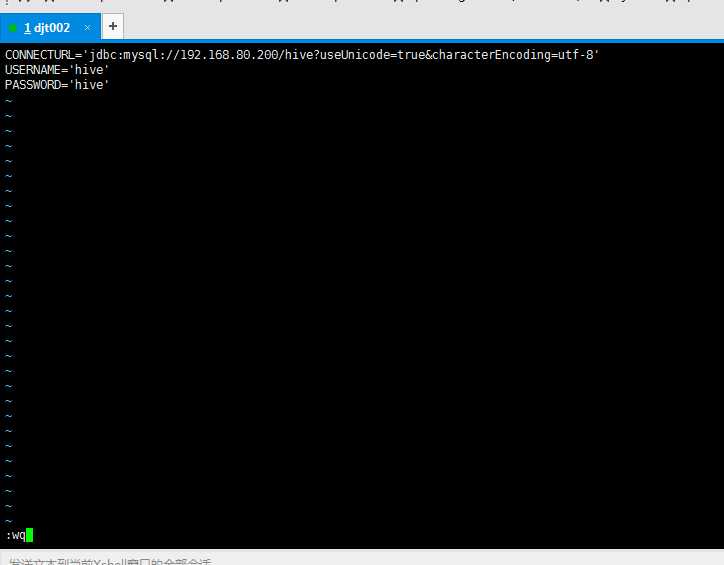
CONNECTURL=‘jdbc:mysql://192.168.8.200/djtdb_test?useUnic
ode=true&characterEncoding=utf-8‘
USERNAME=‘root‘
PASSWORD=‘111111‘
我这里是,
vim /home/hadoop/app/djt/sh/param/sq_shell.config
CONNECTURL=‘jdbc:mysql://192.168.80.200/hive?useUnicode=true&characterEncoding=utf-8‘ USERNAME=‘hive‘ PASSWORD=‘hive‘
8.编写sqoop执行脚本
vim /home/hadoop/app/djt/sh/sqoop/sq_ods_d_djt_user_copy.sh
#! /bin/sh
source /etc/profile
source /home/hadoop/app/djt/sh/param/sq_shell.config
#表名称
v_tableName=djt_user_copy
#需要导入的表字段
v_fields=name,sex,age,profile
#HDFS数据存放地址
v_src=/sqoop/test/djt_user
sqoop export \
--connect $CONNECTURL \
--username $USERNAME \
--password $PASSWORD \
--table $v_tableName \
--columns $v_fields \
--export-dir $v_src \
--input-fields-terminated-by "@" \
-m 1
我这里是,
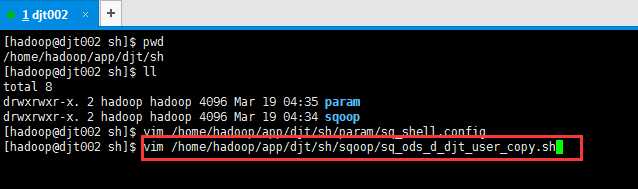
vim /home/hadoop/app/djt/sh/sqoop/sq_ods_d_djt_user_copy.sh
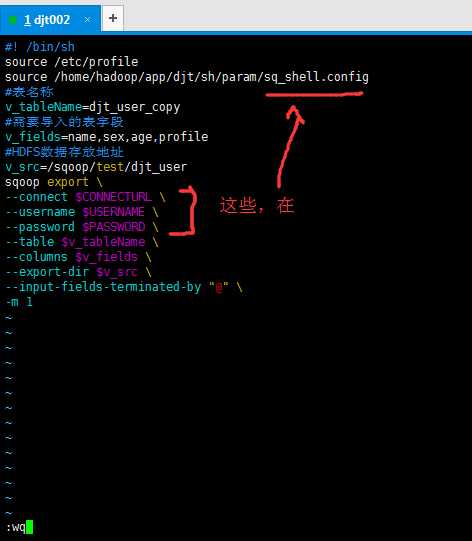
#! /bin/sh source /etc/profile source /home/hadoop/app/djt/sh/param/sq_shell.config #表名称 v_tableName=djt_user_copy #需要导入的表字段 v_fields=name,sex,age,profile #HDFS数据存放地址 v_src=/sqoop/test/djt_user sqoop export --connect $CONNECTURL --username $USERNAME --password $PASSWORD --table $v_tableName --columns $v_fields --export-dir $v_src --input-fields-terminated-by "@" -m 1
我这里,只是做个引子,每次自己可以更改为自己需要的。
实例
首先,开启mysql。
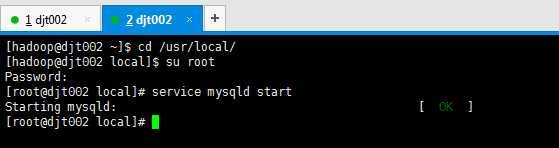
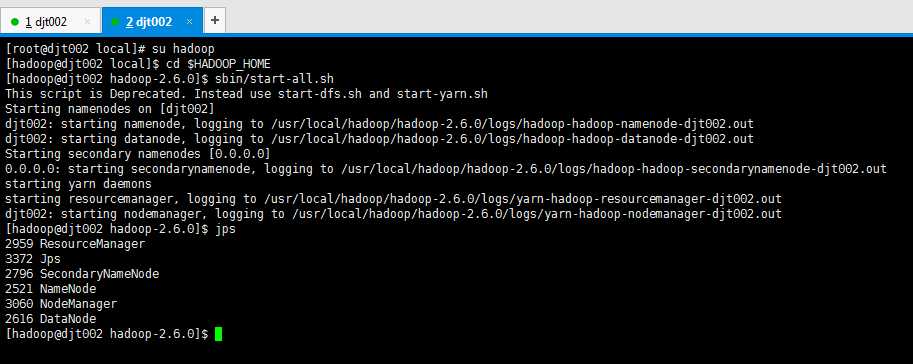
然后,再开启Hadoop集群。
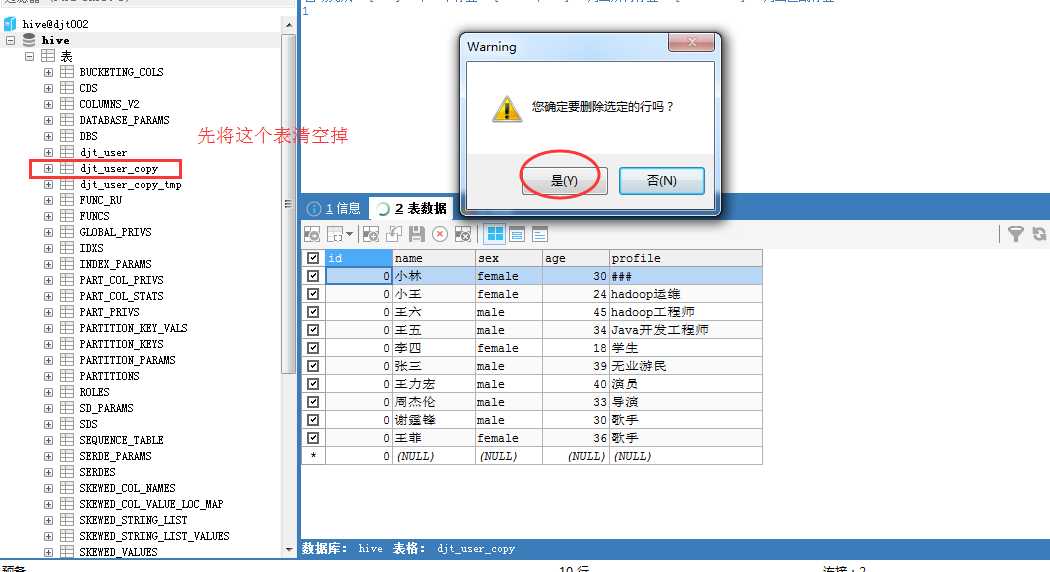
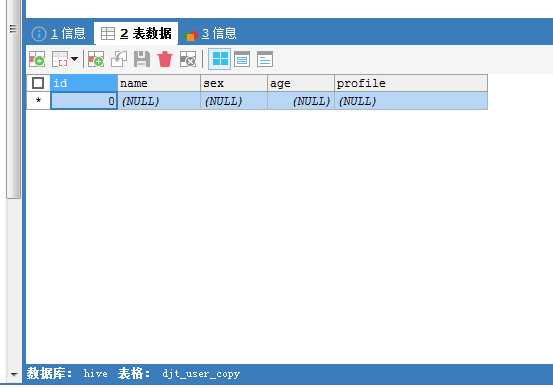
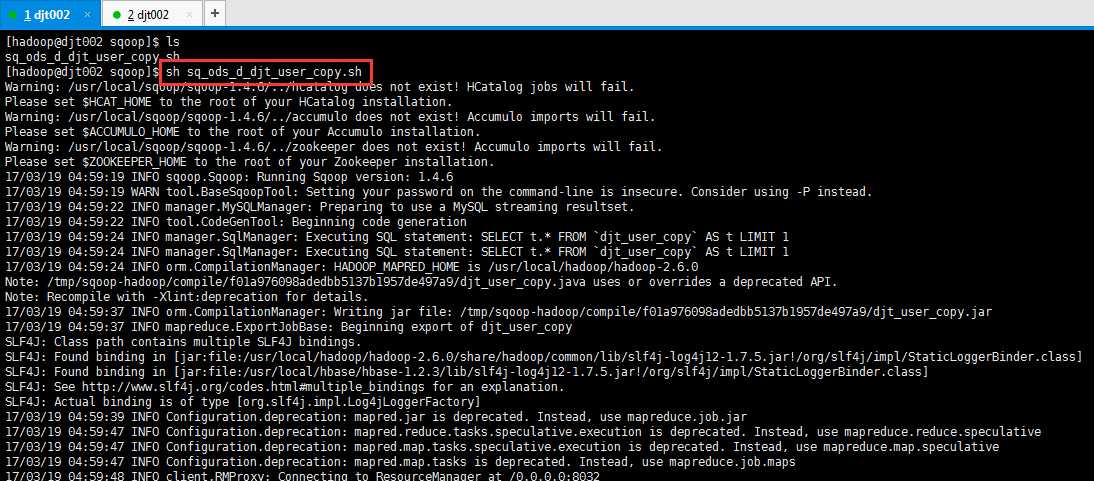
[hadoop@djt002 sqoop]$ pwd /home/hadoop/app/djt/sh/sqoop [hadoop@djt002 sqoop]$ ls sq_ods_d_djt_user_copy.sh [hadoop@djt002 sqoop]$ sh sq_ods_d_djt_user_copy.sh
或者
[hadoop@djt002 sqoop]$ source sq_ods_d_djt_user_copy.sh
或者
[hadoop@djt002 sqoop]$ ./ sq_ods_d_djt_user_copy.sh
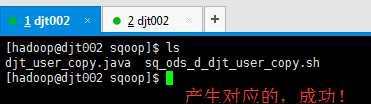
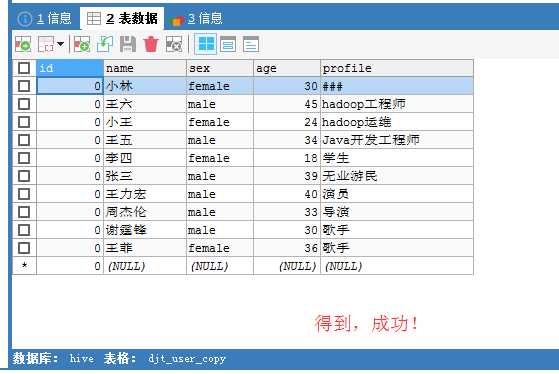
这里,我的id没自动键。以后再修改
Sqoop 脚本开发规范(实例手把手带你写sqoop export和sqoop import)
标签:日志 liunx 为什么 3.1 数据 image 基本 ado 脚本
原文地址:http://www.cnblogs.com/zlslch/p/6576128.html