标签:let 引擎 als group groups parser depend hub 远程
关于MR的工作原理不做过多叙述,本文将对MapReduce的实例WordCount(单词计数程序)做实践,从而理解MapReduce的工作机制。
WordCount:
1.应用场景,在大量文件中存储了单词,单词之间用空格分隔
2.类似场景:搜索引擎中,统计最流行的N个搜索词,统计搜索词频率,帮助优化搜索词提示。
3.采用MapReduce执行过程如图
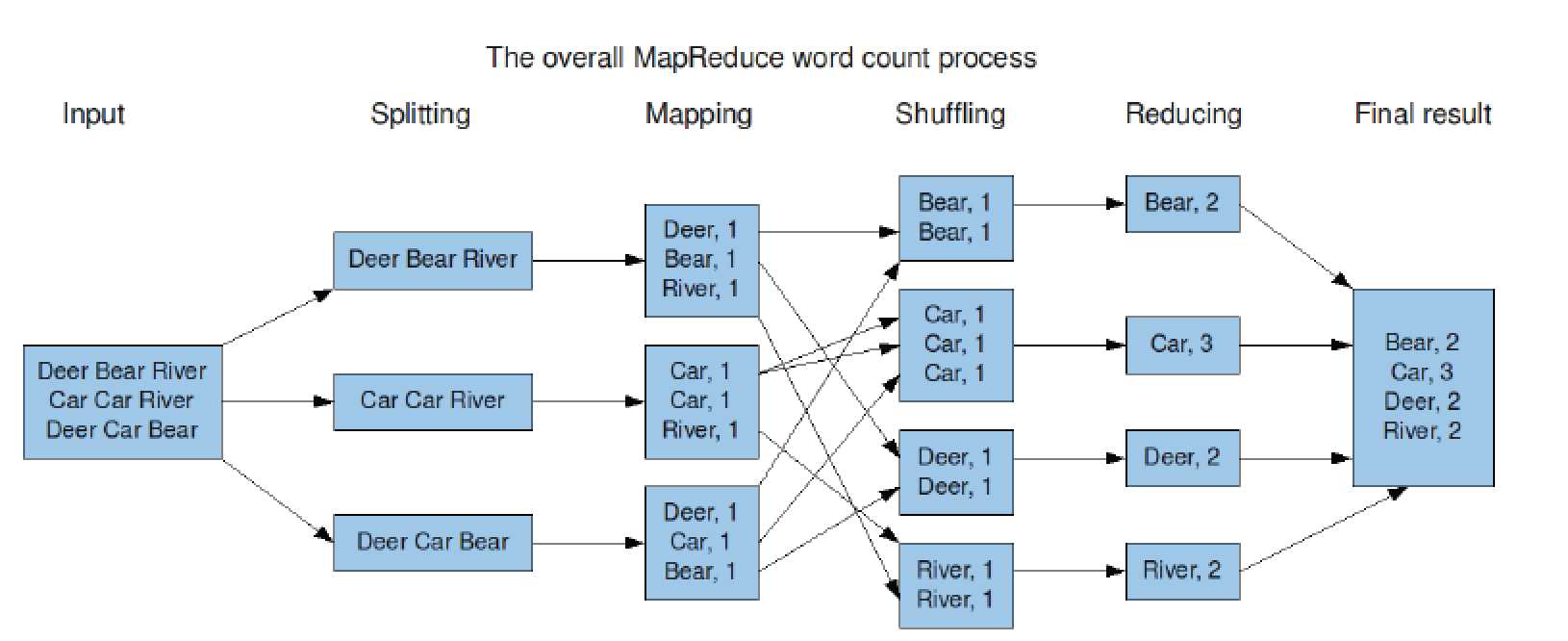
3.1MapReduce将作业的整个运行过程分为两个阶段
3.1.1Map阶段和Reduce阶段
Map阶段由一定数量的Map Task组成
输入数据格式解析:InputFormat
输入数据处理:Mapper
数据分组:Partitioner
3.1.2Reduce阶段由一定数量的Reduce Task组成
数据远程拷贝
数据按照key排序
数据处理:Reducer
数据输出格式:OutputFormat
4.介绍代码结构
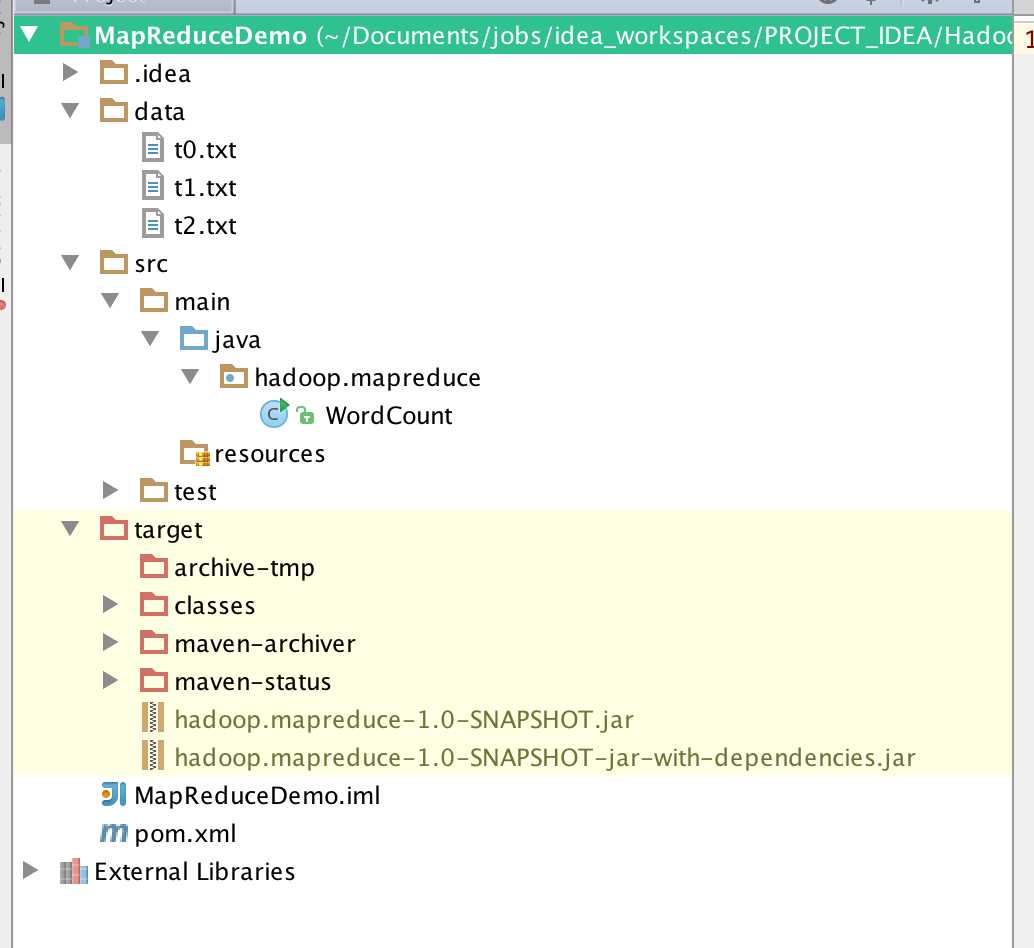
4.1 pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>hadoop</groupId>
<artifactId>hadoop.mapreduce</artifactId>
<version>1.0-SNAPSHOT</version>
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-client</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.7.3</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.3</version>
<configuration>
<classifier>dist</classifier>
<appendAssemblyId>true</appendAssemblyId>
<descriptorRefs>
<descriptor>jar-with-dependencies</descriptor>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
4.2 WordCount.java
package hadoop.mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.IOException;
public class WordCount {
public static class WordCountMap
extends Mapper<Object, Text, Text, IntWritable> {
public void map(Object key,Text value, Context context) throws IOException, InterruptedException {
//在此处写map代码
String[] lines = value.toString().split(" ");
for (String word : lines) {
context.write(new Text(word), new IntWritable(1));
}
}
}
public static class WordCountReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//在此处写reduce代码
int count=0;
for (IntWritable cn : values) {
count=count+cn.get();
}
context.write(key, new IntWritable(count));
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
//设置输入路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
//设置输出路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//设置实现map函数的类
job.setMapperClass(WordCountMap.class);
//设置实现reduce函数的类
job.setReducerClass(WordCountReducer.class);
//设置map阶段产生的key和value的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置reduce阶段产生的key和value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//提交job
job.waitForCompletion(true);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
4.3 data目录下文件内容:
to.txt
hadoop spark hive hbase hive
t1.txt
hive spark mapReduce spark
t2.txt
sqoop spark hadoop
5. 数据准备
5.1 maven 打jar包为hadoop.mapreduce-1.0-SNAPSHOT.jar,传入master服务器上

5.2 将需要计算的数据文件放入datajar/in (临时目录无所谓在哪里)
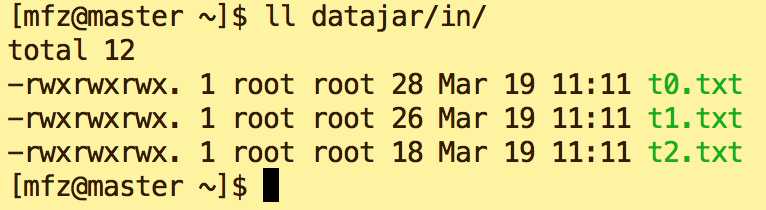
5.3 启动hadoop ,关于hadoop安装可参考我写的文章 大数据系列之Hadoop分布式集群部署
将datajar/in文件传至hdfs 上
hadoop fs -put in /in
#查看文件
hadoop fs -ls -R /in

5.4 执行jar
两种命令方式
#第一种:hadoop jar hadoop jar hadoop.mapreduce-1.0-SNAPSHOT.jar hadoop.mapreduce.WordCount /in/* /out #OR #第二种:yarn jar yarn jar hadoop.mapreduce-1.0-SNAPSHOT.jar hadoop.mapreduce.WordCount /in/* /yarnOut
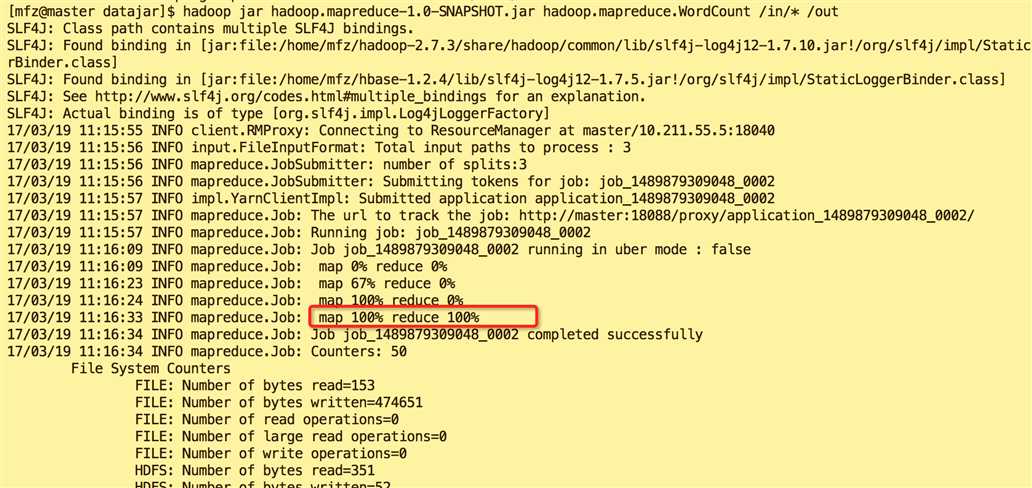
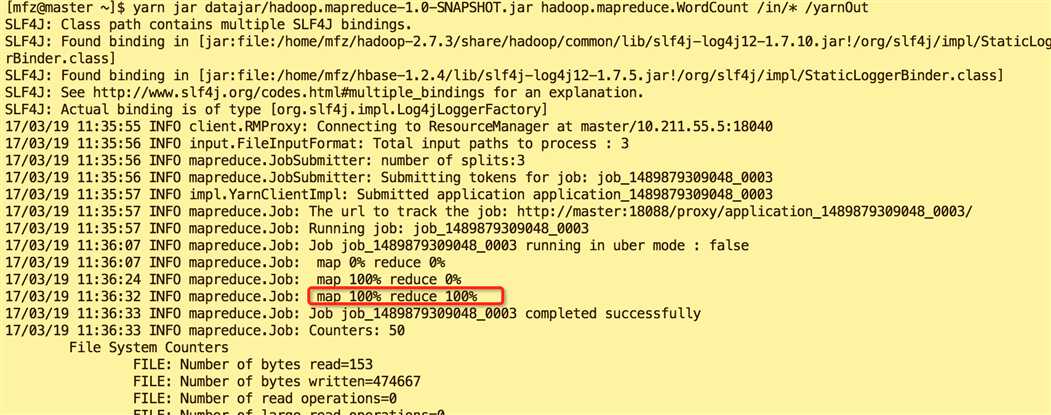
5.5.执行后输出内容分别如图
hadoop jar ...结果
yarn jar ... 结果
6.查看结果内容
#查看hadoop ja 执行后输出结果目录 hadoop fs -ls -R /out #查看yarn jar 执行后输出结果目录 hadoop fs -ls -R /yarnOut
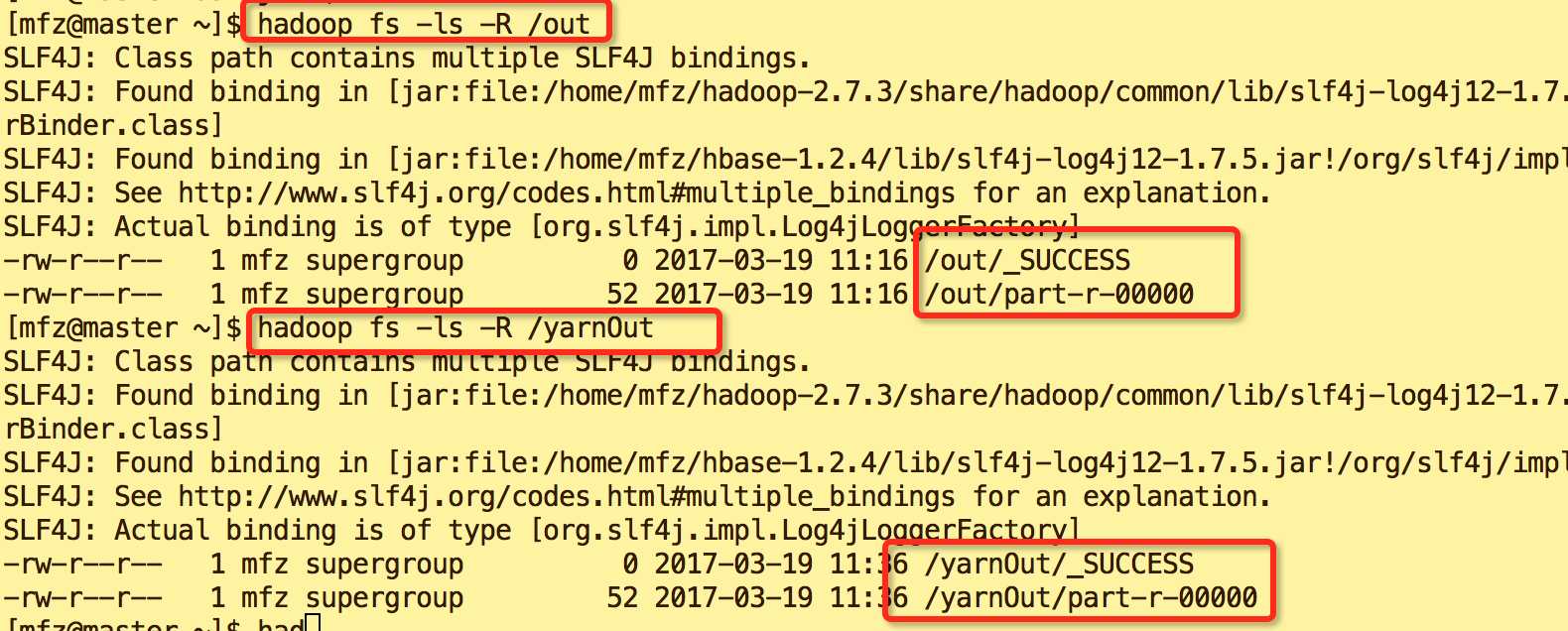
目录说明:目录中_SUCCESS 是日志文件,part-r-00000是计算结果文件
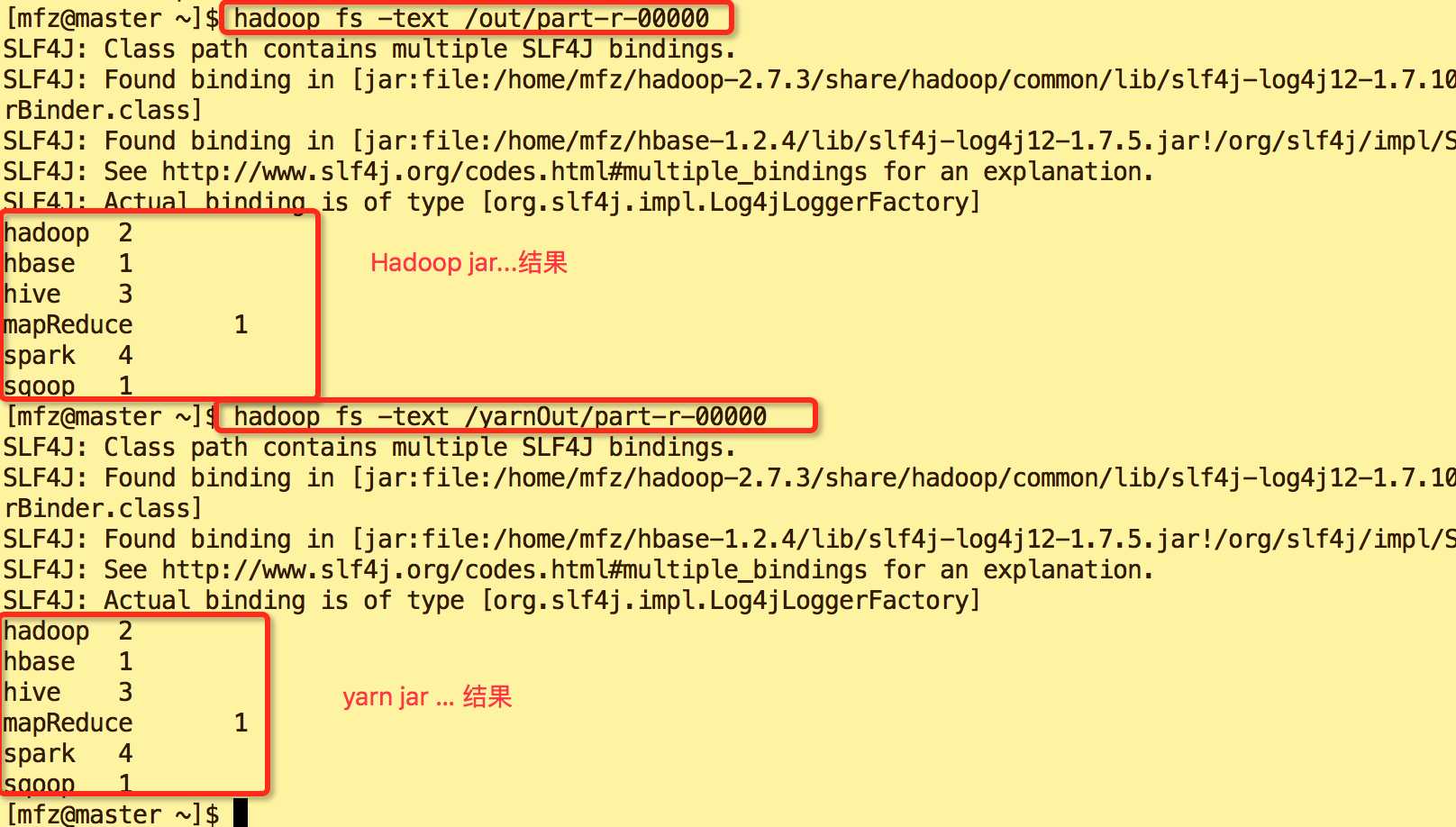
查看计算结果
#查看out/part-r-00000文件 hadoop fs -text /out/part-r-00000 #查看yarnOut/part-r-00000文件 hadoop fs -text /yarnOut/part-r-00000
完~~~,Java代码内容已上传至GitHub https://github.com/fzmeng/MapReduceDemo
标签:let 引擎 als group groups parser depend hub 远程
原文地址:http://www.cnblogs.com/cnmenglang/p/6579940.html