标签:聚类 int clear grid nan dev fit 最大 vector
作者:桂。
时间:2017-03-22 06:13:50
链接:http://www.cnblogs.com/xingshansi/p/6597796.html
声明:欢迎被转载,不过记得注明出处哦~

前言
分布拟合与曲线拟合系列本想简单梳理,却啰嗦的没完没了。本文主要介绍:多直线的拟合,多曲线可以依次类推。全文主要包括:
1)背景介绍
2)理论推导
3)代码实现
4)关于拟合的思考
内容多有借鉴他人,最后一并附上链接。
一、背景介绍
对于单个直线,可以借助MLE或者最小二乘进行求参,对于多条直线呢?
假设一堆数据点($x_j,l_j$),它由两个线性模型产生:
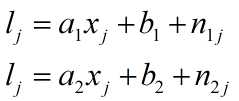
其中$n_{1j}、n_{2j}$分别为对应的随机噪声。
在分析最小二乘与最大似然联系的时候,知道二者可相互转化;另外在分析混合模型(GMM,LMM)时,都是借助最大似然函数。同样,多直线拟合问题是含有隐变量的最小二乘拟合,也就可以转化为最大似然问题,故求解与混合模型(GMM,LMM)方法类似。
二、理论推导
假设误差服从高斯分布,故可借助GMM来解决该问题(误差服从拉普拉斯分布,则借助LMM来解决)。
A-E-Step
1)求解隐变量,转化为完全数据
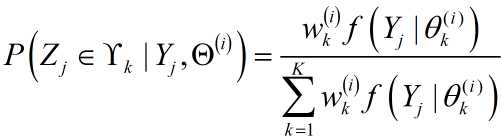
${{Z_j} \in {\Upsilon _k}}$表示第$j$个观测点来自第$k$个分模型。
2)构造Q函数
$Q\left( {\Theta ,{\Theta ^{\left( i \right)}}} \right) = \sum\limits_{j = 1}^N {\sum\limits_{k = 1}^K {\log \left( {{w_k}} \right)P\left( {{Z_j} \in {\Upsilon _k}|{Y_j},{\Theta ^{\left( i \right)}}} \right)} } + \sum\limits_{j = 1}^N {\sum\limits_{k = 1}^K {\log \left( {{f_k}\left( {{Y_j}|{Z_j} \in {\Upsilon _k},{\theta _k}} \right)} \right)} } P\left( {{Z_j} \in {\Upsilon _k}|{Y_j},{\Theta ^{\left( i \right)}}} \right)$
其中${{\theta _k}} = [\mu_k,\sigma_k,a_k, b_k]$为分布$k$对应的参数,$\Theta$ = {$\theta _1$,$\theta _2$,...,$\theta _K$}为参数集合,$N$为样本个数,$K$为混合模型个数。
得到$Q$之后,即可针对完全数据进行MLE求参,可以看到每一个分布的概率(即权重w)与该分布的参数在求参时,可分别求解。由于表达式为一般形式,故该性质对所有混合分布模型都适用。所以对于混合模型,套用Q并代入分布具体表达式即可。
B-M-Step
1)利用MLE求参
由于$\sum\limits_{k = 1}^M {{w_k}} = 1$,利用Lagrange乘子求解:
${J_w} = \sum\limits_{j = 1}^N {\sum\limits_{k = 1}^K {\left[ {\log \left( {{w_k}} \right)P\left( {\left. {{Z_j} \in {\Upsilon _k}} \right|{Y_j},{{\bf{\Theta }}^{\left( i \right)}}} \right)} \right]} } + \lambda \left[ {\sum\limits_{k = 1}^K {{w_k}} - 1} \right]$
求偏导:
$\frac{{\partial {J_w}}}{{\partial {w_k}}} = \sum\limits_{J = 1}^N {\left[ {\frac{1}{{{w_k}}}P\left( {{Z_j} \in {\Upsilon _k}|{Y_j},{{\bf{\Theta }}^{\left( i \right)}}} \right)} \right] + } \lambda = 0$
得
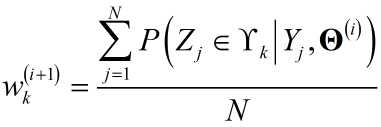
给出准则函数:
${J_\Theta } = \sum\limits_{j = 1}^N {\sum\limits_{k = 1}^K {\log \left( {{f_k}\left( {{Y_j}|{Z_j} \in {\Upsilon _k},{\theta _k}} \right)} \right)} } P\left( {{Z_j} \in {\Upsilon _k}|{Y_j},{\Theta ^{\left( i \right)}}} \right)$
对于多直线拟合问题,$Y_j$为拟合残差,假设其服从高斯分布:
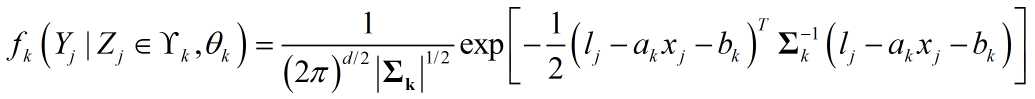
可以认为${{l_j} - {a_k}{x_j}}$就是GMM中的$Y_j$,$b_k$就是$\mu_k$。直接套用GMM中的迭代结果:
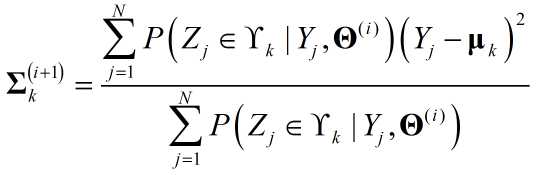
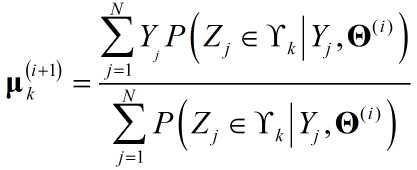
所不同的是,多了一个对$a_k$的求解,容易得出:
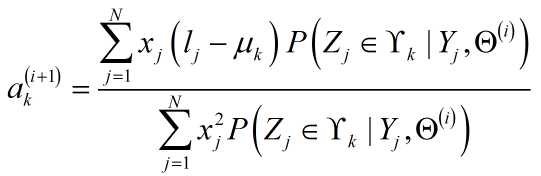
至此,理论推导完成。
三、代码实现
仍然是在之前GMM代码基础上,修改几句指令:
function [u,sig,a,t,iter] = fit_mix_line( X,l,M )
%
% fit_mix_line - fit parameters for a mixed-line using EM algorithm
%
% format: [u,sig,t,iter] = fit_mix_line( X,M )
%
% input: X - input samples, Nx1 vector
% M - number of gaussians which are assumed to compose the distribution
%
% output: u - fitted mean for each gaussian
% sig - fitted standard deviation for each gaussian
% t - probability of each gaussian in the complete distribution
% iter- number of iterations done by the function
%
% initialize and initial guesses
N = length( X );
Z = ones(N,M) * 1/M; % indicators vector
P = zeros(N,M); % probabilities vector for each sample and each model
t = ones(1,M) * 1/M; % distribution of the gaussian models in the samples
u = linspace(min(X),max(X),M); % mean vector
sig2 = ones(1,M) * var(X) / sqrt(M); % variance vector
C = 1/sqrt(2*pi); % just a constant
Ic = ones(N,1); % - enable a row replication by the * operator
Ir = ones(1,M); % - enable a column replication by the * operator
a = ones(1,M);
Q = zeros(N,M); % user variable to determine when we have converged to a steady solution
thresh = 1e-9;
step = N;
last_step = 10; % step/last_step
iter = 0;
min_iter = 3000;
% main convergence loop, assume gaussians are 1D
while ((( abs((step/last_step)-1) > thresh) & (step>(N/5*eps)) ) & (iter<min_iter) )
% E step
% ========
Q = Z;
P = C ./ (Ic*sqrt(sig2)) .* exp( -(((l*Ir-X*a) - Ic*u).^2)./(2*Ic*sig2) );
for m = 1:M
Z(:,m) = (P(:,m)*t(m))./(P*t(:));
end
% estimate convergence step size and update iteration number
prog_text = sprintf(repmat( ‘\b‘,1,(iter>0)*12+ceil(log10(iter+1)) ));
iter = iter + 1;
last_step = step * (1 + eps) + eps;
step = sum(sum(abs(Q-Z)));
fprintf( ‘%s%d iterations\n‘,prog_text,iter );
% M step
% ========
Zm = sum(Z); % sum each column
Zm(find(Zm==0)) = eps; % avoid devision by zero
sig2 = sum((((l*Ir-X*a) - Ic*u).^2).*Z) ./ Zm;
u = sum((l*Ir-X*a).*Z) ./ Zm;
a = sum((l*Ir - Ic*u).*(X*Ir).*Z) ./ (sum((X*Ir).^2.*Z));
% a (isnan(a)) = 0.001;
t = Zm/N;
end
sig = sqrt( sig2 );
给出测试程序:
clc;clear all;close all
set(0,‘defaultfigurecolor‘,‘w‘)
%generate data
x = linspace(-40,40,200);
y = zeros(1,length(x));
y1 = zeros(1,length(x)/2);
y2 = zeros(1,length(x)/2);
k1= 0;k2=0;
for i =1 :length(x)
if mod(i,2)==0
k1=k1+1;
y(i) = 5*x(i)-3 + 3*rand;%分别取0.5 和5
y1(k1)=y(i);
else
k2=k2+1;
y(i)= -7*x(i)+2 + 3*rand;
y2(k2)=y(i);
end
end
[u,sig,a] = fit_mix_line(x‘,y‘,2);
yo=[y1,y2];
[uo,sigo,ao] = fit_mix_line(x‘,yo‘,2);
%figure
subplot 211
scatter(x,y,‘k.‘);
hold on;
t = -20:20;
l1 = t*a(1)+u(1);
l2 = t*a(2)+u(2);
plot(t,l1,‘r‘,‘linewidth‘,2);hold on;
plot(t,l2,‘g--‘,‘linewidth‘,2);hold on;
grid on;
subplot 212
scatter(x,yo,‘k.‘);
hold on;
l1 = t*ao(1)+uo(1);
l2 = t*ao(2)+uo(2);
plot(t,l1,‘r‘,‘linewidth‘,2);hold on;
plot(t,l2,‘g--‘,‘linewidth‘,2);hold on;
grid on;
这里分别针对两种多线性进行拟合:
理论上二者都适用,但运行却发现二者往往只有一个理想,记录此处,暂时未找出原因。
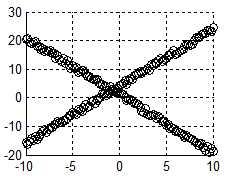
代码中 y(i) = 5*x(i)-3 + 3*rand;%分别取0.5 和5这一句取0.5时,结果图:
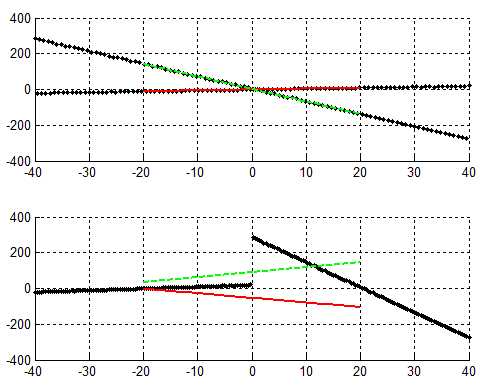
取5时,对应结果图:
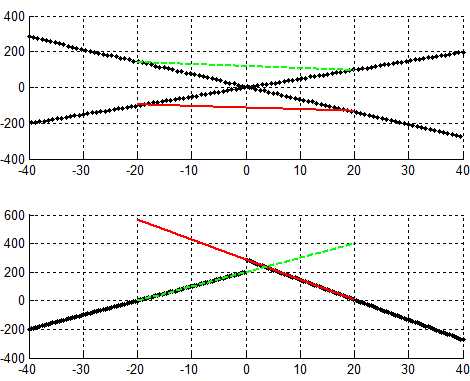
理论上应该二者都适用。
四、关于拟合的思考
A-以正态分布为例
上面分析的多直线拟合,其实是$ax+b$的形式,由此构造混合分布,对于:
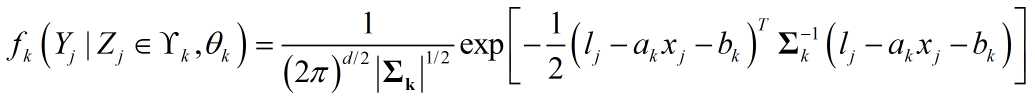
更一般的:
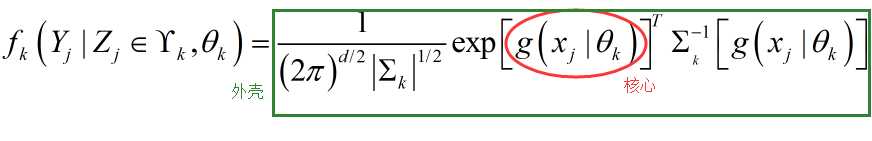
$g$为一般表达式,(如GMM就是$g = ax+b$,且a=0的情况,上文分析的为a不等于0的情况),更一般的$g$理论上可以为任意表达式:
只要将g的具体表达式代入EM求解过程即可。
B-其他分布
上文的讨论基于噪声是正态分布,如果是拉普拉斯分布呢?只要将上面更一般表达式提到的外壳换成拉普拉斯分布模型即可。
事实上,EM的混合模型到此可以看出:混合模型理论上可以实现各类形状的聚类,而噪声同样可以基于不同的分布假设。
参考:
李航:《统计学习方法》
标签:聚类 int clear grid nan dev fit 最大 vector
原文地址:http://www.cnblogs.com/xingshansi/p/6597796.html